
5 פילטרים של לינוקס שחובה להכיר
אחת התכונות המועילות ביותר של לינוקס היא היכולת לעבד קבצים גם אם הם מכילים אלפי שורות באמצעות פילטרים. מדריך זה מסביר כיצד להפעיל פילטרים פשוטים מהטרמינל.
בשביל המדריך הכנתי קובץ המכיל 12 שורות. בכל שורה מחרוזת טקסט:
words.txt
terminal
filters
remove duplicates
sort in alphabetical order
terminal
terminal
writing to standard output
filters1
redirects are awesome
filters2
Using pipes
1. הפקודה cat
הפקודה cat מדפיסה את כל המסמך. נרשום אותה לטרמינל ונריץ:
$ cat words.txtהפלט:
LINUX
terminal
filters
remove duplicates
sort in alphabetical order
terminal
terminal
writing to standard output
filters1
redirects are awesome
filters2
Using pipesהפקודה cat מדפיסה את תוכנו של הקובץ אבל גם מאפשרת לנו לייצר מסמכים, להוסיף תוכן ולהפנות מידע. הפקודה מאוד שימושית ועל כן אקדיש לה מדריך משלה. כמו לגבי כל פקודה, כדאי לעשות לה man על כדי לגלות מה יש לה להציע ע"פ התיעוד הרשמי:
$ man cat
כדי להציג את המסמך ממוספר נשתמש בפקודה nl (number of lines):
$ nl words.txt1 LINUX
2 terminal
3 filters
4 remove duplicates
5 sort in alphabetical order
6 terminal
7 terminal
8 writing to standard output
9 filters1
10 redirects are awesome
11 filters2
12 Using pipes
כדי להדפיס את המסמך בסדר הפוך נשתמש בפקודה tac (שזה cat בהיפוך אותיות):
$ tac words.txtUsing pipes
filters2
redirects are awesome
filters1
writing to standard output
terminal
terminal
sort in alphabetical order
remove duplicates
filters
terminal
LINUX
2. סטטיסטיקות של מסמך באמצעות wc
כדי לראות מידע אודת המסמך נשתמש בפקודה wc (קיצור של word count):
$ wc words.txtהתוצאה:
12 21 157 words.txtהתוצאה מתארת את מספר השורות במסמך (12), מספר המילים (21) ומספר התווים (157).
נוסיף את האפשרות -w כדי לראות את מספר המילים:
$ wc -w words.txtהתוצאה:
21 words.txt21 מילים
ומה לגבי מספר התווים? נשתמש באפשרות -c:
$ wc -c words.txt157 words.txtקיימות אפשרויות נוספות עליהם ניתן ללמוד באמצעות האופציה --help:
$ wc --help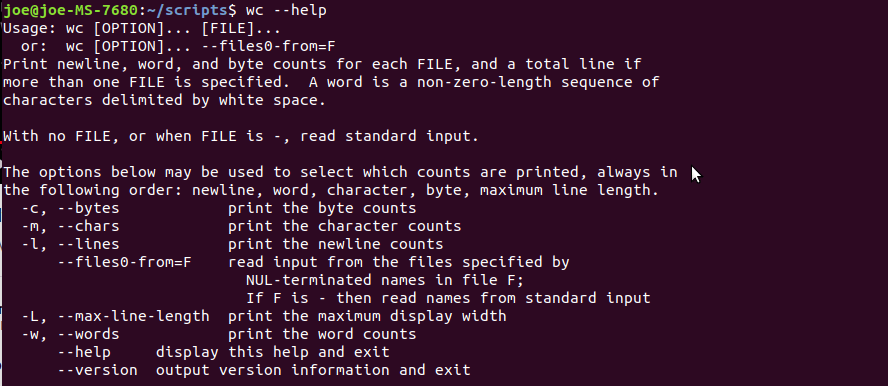
מומלץ להשתמש באופציה help של פקודות כי קשה לזכור את כל האפשרויות וגם כדי ללמוד דברים חדשים.
3. הפקודות head ו-tail
הפקודה head מדפיסה את השורות הראשונות של הקובץ. נריץ אותה:
$ head words.txtהתוצאה:
LINUX
terminal
filters
remove duplicates
sort in alphabetical order
terminal
terminal
writing to standard output
filters1
redirects are awesomeנוסיף מספרי שורות על ידי הפניית הפלט ל-nl שהיא הפקודה שמציגה את מספרי השורות:
$ head words.txt | nlהתוצאה:
1 LINUX
2 terminal
3 filters
4 remove duplicates
5 sort in alphabetical order
6 terminal
7 terminal
8 writing to standard output
9 filters1
10 redirects are awesomeהפקודה head מציגה 10 שורות כדיפולט (ברירת מחדל). נשנה את מספר השורות על ידי העברת האופציה לפקודה:
head [-number of lines] [path]
לדוגמה 3 שורות:
$ head -3 words.txtהתוצאה:
LINUX
terminal
filters
נשתמש בה ללא פרמטרים:
$ tail words.txtהתוצאה:
filters
remove duplicates
sort in alphabetical order
terminal
terminal
writing to standard output
filters1
redirects are awesome
filters2
Using pipesנבקש להציג רק 5 שורות:
$ tail -5 words.txtwriting to standard output
filters1
redirects are awesome
filters2
Using pipesאפשרות מועילה במיוחד לקריאת קבצים המתעדכנים תוך כדי קריאה (דוגמת קבצי לוג) היא שימוש בדגל -f, לדוגמה:
$ tail -f /var/log/apache2/error.log- כל מידע חדש שיתווסף ללוג יראה מיד עם התווספותו על מסך הטרמינל.
4. איך לסדר לפי סדר א"ב עם sort?
המחרוזות במסמך לא מסודרות לפי סדר. נפעיל את הפקודה sort על המסמך כדי לסדר אותם:
$ sort words.txtהמחרוזות מסודרות עכשיו לפי סדר אלף ביתי:
command line
filters
filters1
filters2
LINUX
remove duplicates
sort in alphabetical order
terminal
terminal
terminal
Using pipes
writing to standard outputנשתמש בהפנייה כדי לרשום את הרשימה המסודרת לקובץ חדש:
$ sort words.txt > words-sorted.txt
5. איך לסנן כפילויות באמצעות הפילטר uniq?
המסמך words.txt מכיל כפילויות. כדי להישאר רק עם מחרוזות ייחודיות נשתמש בפקודה uniq:
$ uniq words.txtהתוצאה:
LINUX
terminal
filters
remove duplicates
sort in alphabetical order
terminal
writing to standard output
filters1
command line
filters2
Using pipesהביטוי terminal עדיין מופיע בשתי שורות שונות כי כדי ש-uniq יעבוד צריך קודם כל להריץ את הפקודה sort אז נשתמש בצינור כדי להפנות את פלט הפקודה sort ל-uniq:
הביטוי terminal עדיין מופיע בשתי שורות שונות כי כדי ש-uniq יעבוד צריך קודם כל להריץ את הפקודה sort אז נשתמש בצינור כדי להפנות את פלט הפקודה sort ל-uniq:
$ sort words.txt | uniqוהתוצאה:
command line
filters
filters1
filters2
LINUX
remove duplicates
sort in alphabetical order
terminal
Using pipes
writing to standard outputיופי! המילה terminal מופיעה עכשיו פעם אחת בלבד.
כדי לראות אילו מילים מופיעות יותר מפעם אחת צריך להוסיף את האופציה -d ל uniq:
$ sort words.txt | uniq -dהתוצאה:
terminal
הפקודה grep גם היא פילטר והיא כל כך חשובה ומעניינת שהקדשתי לה מדריך נפרד: חיפוש בתוך קבצים עם grep.
אולי גם זה יעניין אותך:
מערכת הקבצים של Linux - מה שרצית לדעת ולא העזת לשאול
ניהול תהליכים בלינוקס או איך לא להתעצבן כשהמחשב שוב נתקע
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.