

מדריך למידת מכונה (Machine Learning)
כשיש לך מעט כללים והם יחסית מובנים ומסודרים אתה עשוי להזדקק לתכנות, אבל כאשר הכללים מרובים והם מתחילים להתערבב ולהסתחרר הפתרון עשוי להיות למידת מכונה.
מבוא למדריכים על למידת מכונה באמצעות פייתון וספריות קוד מודרניות
אם לא חיית בשנים האחרונות במערה ודאי שמעת על יכולות הבינה המלאכותית שמקנים למחשבים את היכולת להביס מומחים אנושיים בשחמט, במשחקי מחשב ואפילו בזיהוי מחלות. בסדרה זו נלמד את הבסיס ללמידת מכונה שמאפשרת למחשב ללמוד בעצמו מסדרות של נתונים. נעשה זאת באמצעות פייתון וספריות קוד מודרניות דוגמת Tensorflow שעליה מתבסס מנוע החיפוש של גוגל.
הספריות הבסיסיות ללמידת מכונה
12 דברים שאתה חייב לדעת כשאתה עובד עם ספריית Numpy של Python
ספריית Numpy של Python מאפשרת לעבוד עם מערכים רב-מימדיים, ומספקת פונקציות מתמטיות לעבודה עם המערכים.

18 פעולות שאתה צריך להכיר כשאתה עובד עם Pandas של Python
Pandas היא ספרייה של Python המשמשת לניתוח של מידע. במדריך זה ריכזתי עבורכם את המושגים והפקודות השימושיים ביותר.

12 דברים שאתה חייב לדעת כשאתה מייצר תרשימים באמצעות matplotlib של python
הצגת נתונים באמצעות תרשימים היא מאוד חשובה כשמנתחים מידע. הספרייה שבה משתמשים הכי הרבה להצגת מידע באמצעות Python היא Matplotlib. במדריך זה תקבלו הצצה לכמה מהמיומנויות היותר חשובות כאשר משתמשים בספרייה.

הכנת הנתונים ללמידת מכונה באמצעות SciKit-Learn
SciKit-Learn היא ספרייה פופולרית של Python במדריכים אילה אני משתמש בספרייה רק כדי לעבד את הנתונים הגולמיים לפני למידת מכונה שנעשה בפועל באמצעות TensorFlow
מומלץ ללמוד גם את:
מודלים ללמידת מכונה של SciKit-Learn
scikit-learn היא הספרייה הפופולרית ביותר של פייתון ללמידת מכונה הודות למתודות רבות המשמשות לסיווג ורגרסיה והודות לקלות השימוש. במדריך זה נדגים את השימוש ב-scikit-learn בלמידת מכונה, ונראה כמה זה פשוט להגיע לתוצאה. בנוסף, נסקור מודלים שימושיים במיוחד שמציעה הספריייה.

7 דרכים ליצירת תרשימים אטרקטיביים ומשוכללים באמצעות seaborn ופייתון
הספרייה העיקרית בה משתמשים בפייתון לצורך הצגת נתונים היא Matplotlib שיכולה לעשות כמעט הכל אבל היא גם קשה ללמידה ולכתיבה. ספריית Seaborn מבוססת על Matplotlib, ומאפשרת ליצור תרשימים אטרקטיביים ומשוכללים בממשק ידידותי הרבה יותר. למרות הפשטות של Seaborn מומלץ קודם להכיר את עקרונות העבודה עם Matplotlib כי יש דברים שניתן לעשות רק באמצעות Matplotlib. במדריך זה תקבלו הצצה לכמה ממקרי השימוש הנפוצים כשעובדים עם Seaborn.
Keras - הממשק הידידותי ביותר ללמידת מכונה
* Keras הוא הממשק ברירת המחדל של TensorFlow 2.
רגרסיה קווית באמצעות TensorFlow 2
רגרסיה קווית (לינארית) משמשת למציאת הקשר בין נתונים מספריים. במדריך זה נמצא את המתאם (קורלציה) בין שטח בית ומחירו באמצעות למידת מכונה וספריית TensorFlow 2. קיימות שיטות פשוטות יותר למציאת רגרסיה מאשר למידת מכונה אבל אותנו מעניין ללמוד והדוגמה במדריך היא הפשוטה ביותר שאני יכול לחשוב עליה.

חיזוי מחירי בתים באמצעות למידת מכונה ומודל לינארי מרובה משתנים
במדריך הקודם בסדרה המוקדשת ללמידת מכונה פיתחנו מודל רגרסיה לינארית המסוגל לחזות מחירי דירות בהינתן השטח. במדריך הנוכחי נמשיך באותו נושא ונלמד את המכונה לחזות את מחירי הדירות על סמך מספר משתנים ותוך התחשבות בסוג המשתנים, מספרי או קטגורי.
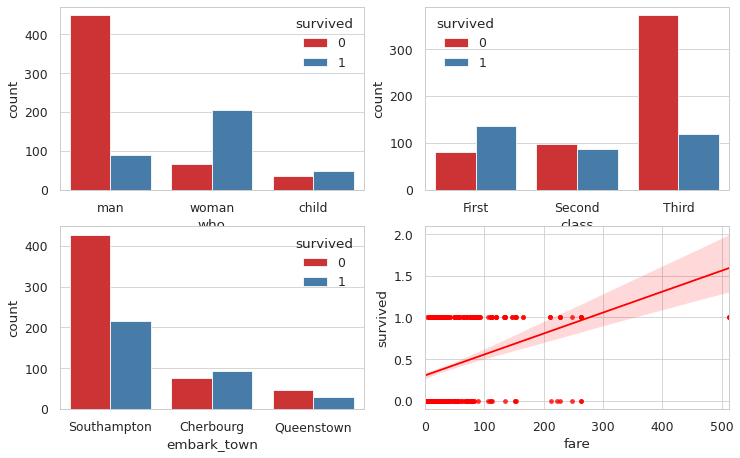
סיווג לקבוצות באמצעות למידת מכונה
מטרת המדריך היא ללמד את המחשב להבחין בין קבוצות בעזרת למידת מכונה. לשם כך נשתמש במסד נתונים קלאסי הכולל מדידות ושמות של שלושה זני אירוסים. זני הפרחים נראים כמעט זהים לחלוטין לעין אנושית אולם מעט מומחים בעולם יכולים להבחין ביניהם על סמך ממדי עלי הכותרת. מעניין האם מודל למידת המכונה אותו נפתח במדריך יצליח במלאכת הסיווג.

Confusion matrix ומדדים להערכת המודל
אחרי שסיימנו לפתח את המודל במדריך הקודם השאלה היא עד כמה הוא טוב. תשובה אחת שראינו משתמשת במדד "דיוק" (accuracy). הבעיה עם המדד accuracy שהוא יודע להעריך באופן כללי עד כמה המודל הוא מדויק אבל הוא לא יודע להגיד לנו אילו שגיאות המודל עשה. כדי לזהות את השגיאות משתמשים ב- Confusion matrix ומדדים להערכת המודל (model evaluation metrics)

מדדים להערכת המודל ועקומת ROC-AUC
אחרי שבמדריך קודם הסברנו את הנושא של confusion matrix ומדדים להערכת המודל בלי להשתמש בקוד, במדריך זה נחזור לעסוק בנושא באמצעות דוגמה קונקרטית ומודל למידת מכונה מבוסס פייתון. במדריך נכיר מדדים נוספים להערכת המודל, ונלמד על על עקומת ROC ומדד AUC.
האם נצליח ללמד את המחשב להבחין בין יינות משובחים ופשוטים?
מה גורם ליין משובח להצטיין בטעמו? זו חידה שרק מעטים יודעים את פתרונה. עד כה יחידי הסגולה שידעו להבחין בטיב היין ניחנו בחך רגיש המסוגל להבחין בין אלפי סוגי המולקולות במשקה המשכר – נצר לקבוצות עילית שזוכה לטעום אלפי דוגמאות מכל העולם בחסות ייננים מומחים. במדריך זה ננסה ללמד את המחשב להבחין בין יינות משובחים ופשוטים על סמך מספר מצומצם של תכונות כימיות. מעניין האם המכונה תצליח לעמוד במשימה שמעטים האנשים שמסוגלים לעמוד בה?

זיהוי ספרות שכתב אדם על ידי בינה מלאכותית - פיתוח המודל
במדריך זה נפתח מודל של בינה מלאכותית שמטרתו להבחין בין ספרות כתובות בכתב יד. המדריך נעשה על מסד נתונים ששמו MNIST שהסיווג שלו נחשב ל"שלום עולם" של עולם למידת המכונה באמצעות תמונות.
שמירת וטעינת מודל TensorFlow 2
אחרי שבמדריכים קודמים למדנו כיצד לבנות ולאמן מודל של למידת מכונה באמצעות , במדריך זה נסביר כיצד לשמור ולטעון את המודל
כיצד להשתמש במודל קיים של TensorFlow Hub לסיווג תמונות?
היכולת של מחשבים לזהות אובייקטים בתמונות נעשית באמצעות מודלים מבוססי קונבולוציה (convolution). הבעיה היא שפיתוח המודלים הוא קשה ומסובך כמו גם הצורך להזין למערכת מספר גדול מאוד של תמונות כדי שתלמד להבחין ביניהם. TensorFlow Hub מאפשר לפתור את הבעיה באמצעות מודלים מאומנים שפיתחו המומחים המובילים בעולם שאנחנו יכולים להשתמש בהם למטרות שלנו. במדריך זה אני משתמש במודל MobileNet לזיהוי תמונה. המודל קטן יחסית ועל כן משך הזמן שנדרש לאימון ולסיווג פוחת. ניתן להשתמש בעקרונות שילמדו במדריך במודלים אחרים במאגר TensorFlow Hub.
מיני-פרוייקט סיווג תמונות באמצעות Keras
סיווג תמונות באמצעות מודל מאומן VGG16 על מסד נתונים שהורדנו מ-kaggle
סדרת מדריכים זו מדגימה transfer learning שהיא ענף של למידת מכונה המתמקד בשימוש בידע שנרכש תוך פתרון בעיה אחת לפתרון בעיה קשורה אחרת. במדריך זה, נלמד לייעד מחדש מודל VGG16 כדי שיוכל להבחין בין תמונות כלבים לחתולים במקום בין כל 1000 הקבוצות שאותם למד המודל לסווג במקור.

למידת מכונה: סיווג תמונות באמצעות מודל VGG16 (חלק ב) - הבניית התיקיות
במדריך השני בסדרת transfer learning כדי לעשות למידת מכונה נבנה את התיקיות שישמשו אותנו לאימון המודל להבחין בין תמונות כלבים וחתולים
למידת מכונה: סיווג תמונות באמצעות מודל VGG16 (חלק ג) למידת העברה ולמידה בפועל
אחרי שבמדריכים קודמים הורדנו את מאגר הנתונים והכנו את מבנה התיקיות במדריך השלישי בסדרה על למידת העברה, transfer learning, נאמן את המודל בפועל לאחר שנחליף בו את השכבות המסווגות.
למידת מכונה : סיווג תמונות באמצעות מודל VGG16 (חלק ד) - הערכת המודל
בשלושת המדריכים הקודמים בסדרה פתחנו מודל לסיווג תמונות באמצעות למידת מכונה וייעוד מחדש של מודל קיים VGG16. מודל מוצלח מצליח להכליל מסט הנתונים שעליהם הוא פותח לנתונים אחרים שאליהם הוא לא נחשף במהלך תהליך הפיתוח. כפי שראינו במדריך קודם המודל אותו פיתחנו הצליח לסווג נכונה למעלה מ-97% מהתמונות בסט המבחן, למרות שהמודל לא נחשף לתמונות אילו בתהליך האימון. במדריך זה נמשיך לנסות ולהעריך את מידת האמינות של המודל בגישות שונות.
Keras Tuner - לבחירת ההיפר-פרמטרים למודל למידת מכונה
בכל פעם שאני צריך לבנות מודל של למידת מכונה אני צריך לקבל החלטות בנוגע להיפר-פרמטרים של הרשת מה שיוצר לי בעיה כי מספר האפשרויות הוא עצום. במדריך זה אנסה לפתור את הבעיה בשתי גישות. גישה אחת של ניחוש מושכל המבוסס על ידע אנושי. גישה שנייה היא סריקת מגוון עצום של פרמטרים וארכיטקטורות באמצעות ספריית Keras Tuner. אם תרצו אדם כנגד מכונה במשימה האולטימטיבית למצוא את מודל המכונה הטוב ביותר.

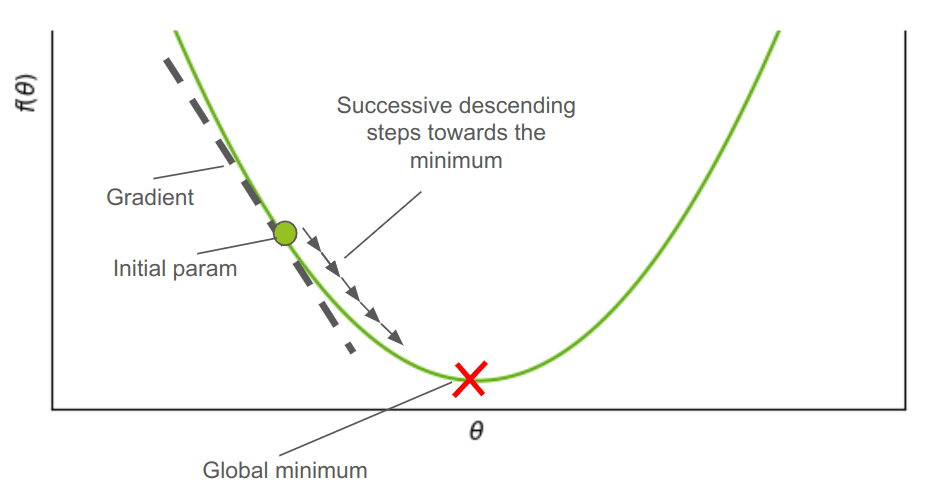
מה זה Gradient Descent ומה עושה אותו כל כך חשוב בלמידת מכונה?
Gradient Descent (GD) הוא אלגוריתם אופטימיזציה המשמש למציאת המינימום/מקסימום המקומי של פונקציה מתמטית. בלמידת מכונה, הוא משמש כדי למזער את פונקציית העלות cost function (למשל, ברגרסיה ליניארית). למרות שקיימים מספר אלגוריתמי אופטימיזציה, הנפוץ שבהם, בכל הנוגע ללמידת מכונה, הוא Gradient Descent. במדריך זה לא רק נסביר את האלגוריתם, אלא גם ניצור קוד פייתון משלנו ליישום Gradient Descent.
פונקציות אופטימיזציה וכיצד לבחור את הפונקציה המתאימה ביותר למודל?
אחרי שבמדריך הקודם מצאנו את הפרמטרים האופטימליים לבניית רשת נוירונית המשמשת לזיהוי ספרות הכתובות בכתב יד. במדריך הנוכחי ננסה לשפר את דיוק המודל ואולי אף את משך הזמן שאורך תהליך הלמידה באמצעות שינוי הפונקציות המשמשות לאופטימיזציה של התהליך. בדרך נלמד אודות פונקציות האופטימיזציה המשמשות בלמידת מכונה וגם נמצא את הפונקציות שנותנות את התוצאות הטובות ביותר עבור המודל שלנו.
הגדלת כמות התמונות ללמידת מכונה באמצעות augmentation
אחת הדרכים שבאמצעותה ניתן להרחיב את מאגר המידע ממנו יכולה ללמוד הרשת הנוירונית היא באמצעות גישה של augmentation, ולשמחתנו Keras מציעה את הפונקציה ImageDataGenerator שיכולה להפיק תמונות מגוונות ושונות זו מזו על בסיס תמונה מקורית שנספק לה. המגוון בא לידי ביטוי בשינויים ויזואליים דוגמת סיבוב, צביעה, בהירות וחדות. כך נוכל באמצעות פקודה אחת פשוטה להגדיל את כמות התמונות היכולות לשמש לאימון הרשת הנוירונית בסדרי גודל.

כיצד לחזור על אותם תוצאות בדיוק כשמשתמשים ב-Keras לצורך למידת מכונה
ודאי שמתם לב שכשאתם מאמנים את אותו המודל שפתחתם ב-Keras על אותם הנתונים אתם מקבלים תוצאות שונות. השונות הזו מובנית במערכת אבל לפעמים אנחנו מעוניינים לקבל תוצאות עקביות אז במדריך זה נלמד כיצד לאלץ את המערכת להנפיק את אותם התוצאות בכל פעם ובתנאי שמשתמשים באותו המודל ובאותם הנתונים.
כיצד להתגבר על overfitting במודלים מבוססי Keras?
המדריך מסביר מהו overfitting במודלים של למידת מכונה וכיצד לגבור עליהם באמצעות מתודות של Keras.
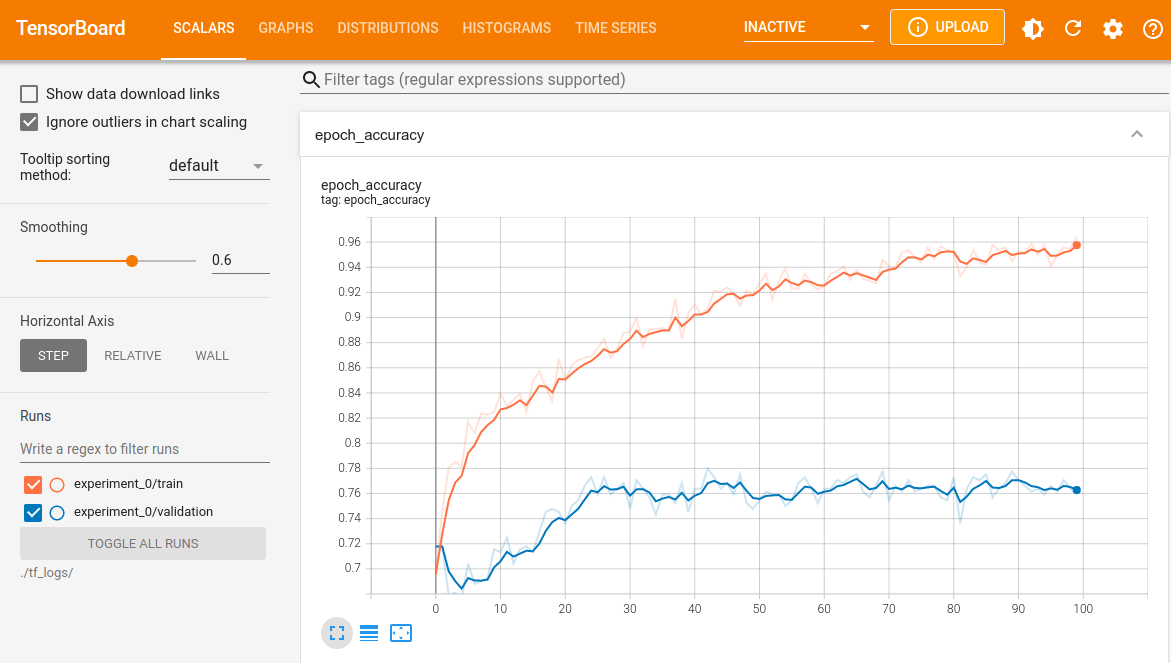
שימוש ב-TensorBoard לניטור מודלים של למידת מכונה
מעקב אחר פרמטרים מדידים של למידת מכונה דוגמת, דיוק ו-loss, הכרחיים כדי שנוכל להעריך את האפקטיביות של המודל שלנו. במדריך זה נכיר את TensorBoard המאפשר מעקב אחר ביצועי המודל בזמן אמת ובפירוט רב.
מדריך לשימוש ב-API הפונקציונלי של Keras
עד כה כתבנו מודלים של למידת מכונה באמצעות מודלים של Keras מסוג sequential כי הם הנוחים ביותר למתחילים אבל רוב המודלים המקצועיים זקוקים לתחביר גמיש יותר דוגמת זה שמאפשר ה-API הפונקציונלי functional. במדריך זה נלמד איך ולמה לעבוד עם ה-API הפונקציונלי.
subclassing של שכבות ומודלים בספריית Keras
אחרי שעבדנו עם ה-API הסדרתי sequential של Keras שהוא הכי ידידותי וגם הכי פחות גמיש ועם ה-API הפונקציונלי שהוא פחות ידידותי ויותר גמיש, במדריך זה נלמד לעשות subclassing של שכבות ומודלים. הדוגמה במדריך מבוססת על מדריך קודם זיהוי ספרות שכתב אדם על ידי בינה מלאכותית שם למדנו להשתמש ברשת נוירונית מבוססת קונבולוציה CNN, Convolutional Neural Network לעבודה עם תמונות. רשת CNN בנויה מאחד או יותר בלוקים של קונבולוציה שכל אחד מהם מורכב משכבה אחת או יותר של קונבולוציה שאחריה שכבת pooling. במדריך הסתפקנו בשתי שכבות בגלל שהמשימה היתה פשוטה: סיווג תמונות של ספרות קטנות (28X28 פיקסלים) שאנשים כתבו בכתב יד לאחת מ-10 קטגוריות (0 - 9). במציאות, יכולים להיות הרבה יותר קטגוריות וגם התמונות יכולות להיות גדולות הרבה יותר מה שדורש יותר בלוקים של קונבולוציה וגם ארכיטקטורה מורכבת. אפשר לחסוך חלק מהמורכבות אם מתייחסים לבלוק של הקונבולוציה בתור מודול ואז משלבים כמה מודולים כאלה בבניית הרשת הנוירונית. כדי לעשות זאת נשתמש ב-API ה-subclassing של Keras. וזו רק דוגמה לשימוש ב-subclassing בבניית מודלים מורכבים של למידת מכונה.

מה רואות שכבות הביניים כשעושים למידת מכונה עם מודל מבוסס CNN
יש נטייה להתייחס למודלים של למידת מכונת עמוקה כאל קופסה שחורה שמכניסים לתוכה נתונים ומקבלים תחזיות בצד השני בלי יכולת להבין מה קורה באמצע. אבל בכל הנוגע לרשתות נוירונים מבוססות שכבות קונבולוציה CNN זה לא המצב. במדריך זה נראה כיצד אנחנו יכולים לראות מה מזהים הפילטרים מהם מורכבת הרשת.

YOLO - בינה מלאכותית שמזהה עצמים מרובים בתמונות
אחת הטכנולוגיות הנפוצות ביותר לזיהוי של עצמים היא YOLO במדריך הזה נלמד כיצד להשתמש ב-YOLO כדי לזהות מספר עצמים בתמונות בודדות.

למידת מכונה כשסדר הנתונים משנה RNN
ניתוח והצגת סדרות נתונים מבוססות זמן באמצעות pandas
במדריך זה נלמד להציג ולנתח סדרות נתונים מבוססי זמן באמצעות pandas. הדוגמה במדריך היא של מחירי מניות.
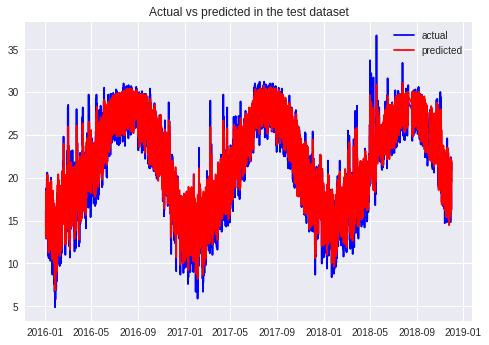
חיזוי טמפרטורות באמצעות למידת מכונה
חיזוי של סדרות נתונים מציב אתגר גדול בפני למידת מכונה בגלל שהמחשב צריך לזכור את התוצאות שחושבו בשלבים הקודמים של תהליך הלמידה דבר שאינו אפשרי ברשת נוירונית רגילה (feed forward network). כדי לטפל בבעייה ניתן להשתמש בסוג מיוחד של למידת מכונה, RNN - Recurrent Neural Networks. המדריך מדגים חיזוי טמפרטורות שנתיים בעתיד באמצעות למידת מכונה באמצעות ספריית keras.
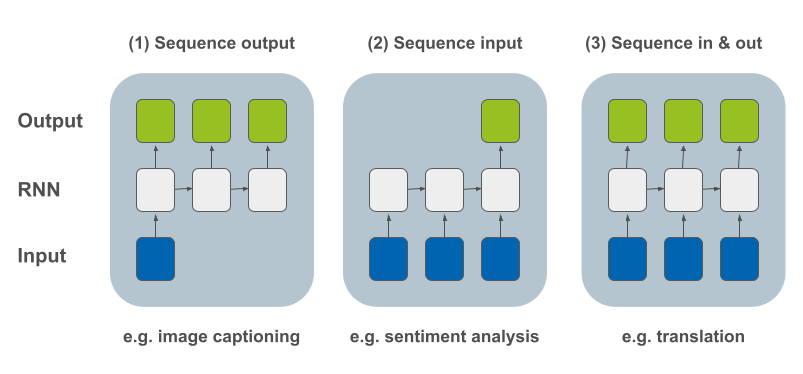
ארכיטקטורות של מודל RNN
אחרי שבמדריך קודם למדנו כיצד להשתמש ברשת נאורונית מסוג RNN כדי לאפשר למחשב ללמוד רצפים, במדריך זה נלמד 4 סוגי מבנים שבהם אנו יכולים להשתמש כדי ליצור את המודל שלנו.
דף צ'יטים לבניית מודלים של למידה עמוקה באמצעות Keras
למידת מכונה היא הדרך העיקרית ליישם בינה מלאכותית, בתוכה למידה עמוקה היא התחום שמושך הכי הרבה עניין. בלמידה עמוקה ישנם 4 סוגי ארכיטקטורות עיקריות: Dense בשביל בעיות סיווג ורגרסיה, CNN בשביל תמונות, RNN בשביל רצפים, ו-Transformers בשביל תרגום רצפים. הדרך הפשוטה ביותר לעשות למידה עמוקה הוא באמצעות ממשק Keras.
עיבוד שפה טבעית NLP
תקציר מאמר וויקיפדיה באמצעות פייתון
אחת הדרכים הטובות ביותר ללמוד תחום היא להכיר את המונחים הנפוצים ביותר בתחום. נשתמש בעיקרון זה כדי ללמוד מאמר בוויקיפדיה. הסקריפט הבא ימצא את כל המאמרים בוויקיפדיה בנושא מסוים, ישלוף את המאמר הראשון מתוך המאמרים, יגרד את דף ההטמ"ל של המאמר הראשון, ינקה את התוכן, ויספק טבלה של 15 המונחים הנפוצים ביותר במאמר. בסוף ננסה להעריך כמה אנחנו יכולים להבין מתוכנו של מאמר על סמך המילים הנפוצות בו.
מבוא לעיבוד שפה באמצעות Gensim ו-Word2Vec
Gensim היא חבילה של פייתון לעיבוד שפה (Natural Language processing) באמצעות למידת מכונה. Word2Vec הם אלגוריתמים שמייצרים וקטורים ממילים כדי שהמחשב יוכל לבצע את הפעולות החשבוניות החיוניות ללמידת מכונה.

למידת מכונה - סיווג טקסטים באמצעות sklearn
אחרי שניסיתי לסווג דוגמאות טקסט בכל מיני שיטות הצלחתי להגיע לתוצאות מעולות באמצעות sklearn שהיא גם השיטה הפשוטה ביותר ליישום.

פיתוח מודל לאנליזת סנטימנט באמצעות למידת מכונה ו-TensorFlow
אנליזת סנטימנט (sentiment analysis) משתמשת במחשבים כדי ללמוד את דעת הקהל מטקסטים שהציבור מפרסם ברשתות חברתיות ובאזור תגובות הקהל בעיתונים. ניתן לבצע את האנליזה באמצעות למידת מכונה מטקסטים בגישה של עיבוד שפה טבעית (Natural Language Processing, NLP). במדריך זה נלמד את המחשב להבחין בין טקסטים המבטאים דעות חיוביות ושליליות באמצעות TensorFlow 2, הספרייה המשמשת את גוגל ללמידת מכונה.

שימוש ב-word embedding שאומן מראש במודל Keras לסיווג טקסטים
בהמשך למדריכים קודמים על סיווג טקסטים באמצעות למידת מכונה, במדריך זה נעזר ב-word embedding מבוסס אלגוריתם GloVe.
הטרנספורמרים משנים את עולם הבינה המלאכותית
מודלים מסוג טרנספורמרים משנים את עולם הבינה המלאכותית ומגיעים להישגים על אנושיים במשימות של עיבוד שפה טבעית (NLP), יצירת איורים, קיפול חלבונים, משחקי לוח ומחשב, ועוד. ספריית transformers מאפשרת לעבוד עם הטרנספורמרים השונים בממשק אחיד שנועד לשרת את חובבי Tensorflow כמו גם את מקצועני PyTorch. במדריך זה אסביר בקצרה מהם טרנספורמרים ואדגים סיכום של טקסט באמצעות הספרייה.

סיכום מאמר ויקיפדיה באמצעות המודל המתקדם בעולם T5 של גוגל
נמאס לך לקרוא מאמרים ארוכים? חולם על בינה מלאכותית שתסכם בשבילך טקסטים ארוכים? מסתבר שמערכת כזו כבר קיימת וכלל אינה מדע בידיוני. מאמר זה מסביר איך לבנות מערכת שתסכם בשבילך את המאמרים שאתה מעוניין לקרוא בכמה שורות של קוד פייתון. במדריך נסכם את הערך על טרנספורמרים בויקיפדיה האנגלית באמצעות המודל המתקדם מסוגו בעולם - T5 של גוגל. המערכת משתמשת במאמר ויקיפדיה כדוגמה אותה ניתן לשנות בקלות כדי לסכם כל תוכן שאפשר להוריד למחשב.
זיהוי הודעות SMS ספאמיות בעברית בעזרת מודל טרנספורמר heBERT
הפצצה של הטלפונים הניידים בהודעות SMS ספאמיות היא מטרד שכיח במקומותינו. במדריך אני משתמש בלמידת מכונה לסיווג מהיר של הודעות. ישנם מגוון של מודלים של למידת מכונה שיכולים להתמודד עם שפה אנושית NLP אבל מ-2017 המודלים הטובים ביותר הם מסוג טרנספורמר transformer. השנה נוסף מודל טרנספורמר heBERT שאומן על טקסטים בעברית ובמקור משמש לאנליזת סנטימנט. במדריך זה אדגים כיצד לאמן את המודל למשימה של זיהוי הודעות ספאם קצרות.
זיהוי SMS ספאמי בעזרת בינה מלאכותית
קיימות שתי גישות לעיבוד טקסט. הראשונה מתייחסת לטקסט כאל סדרה sequence שחיוני לשמור בה על סדר המילים. השנייה כאל "שק מילים" bag of words שאינה שומרת על הסדר. המודלים של עיבוד שפה טבעית NLP נחלקים בהתאם למודלים מבוססי סדר (RNN וטרנספורמרים) ולעומתם מודלים bag of words. במדריך זה נסביר איך להשתמש במודל bag of words לצורך אבחנה בין הודעות SMS לגיטימיות וספאמיות (ham or spam) באמצעות ספריית למידת מכונה Keras. יכולת חשובה במדינה שבה מציפים אותנו השכם והערב בהודעות טקסט שמטרתם לקדם: הלוואות, קנאביס או פוליטיקאים מזדמנים.
זיהוי SMS ספאמי באמצעות מודל RNN
במדריך הקודם ראינו כיצד לאתר הודעות SMS ספאמיות בשיטת bag of words בה אין חשיבות לסדר המילים. במדריך זה נראה כיצד להשתמש במודלים מבוססי סדר באמצעות רשתות מסוג RNN ושכבת הטמעה להשגת אותה מטרה.

זיהוי SMS ספאמי בעזרת RNN ומרחב הטמעה שאומן מראש
במדריך הקודם ראינו כיצד להבחין בין הודעות SMS תקינות לספאמיות באמצעות מודל RNN המתחשב בסדר המילים ומוזן על ידי שכבת הטמעה embedding אותה אימנו מאפס. יכולנו להרשות לעצמנו לאמן את הרשת מאפס בגלל שמסד הנתונים שעמד לרשותינו היה גדול מספיק. רק שלעיתים כמות הטקסט אינה מספיקה לאימון המודל ואז אפשר להשתמש במסד נתונים של וקטורי הטמעה שאומנו מראש pre-trained word embeddings, המכילים מספיק מילים והקשרים שחלקם עשויים להיות שימושיים עבור המשימה שעל הפרק. לצורך זה, קיימות מספר ספריות ידועות באנגלית, ביניהם word2vec ו-GloVe.
איתור SMS ספאמי באמצעות טכנולוגית Transformer
מודלים מבוססי ארכיטקטורת טרנספורמר Transformer שינו מן היסוד את הדרך בה אנו עובדים עם מודלים של עיבוד שפה אנושית NLP בזכות מנגנון self attention המאפשר עבודה עם רצפים ארוכים של מידע. אחת הבעיות היא שצריך כמות אדירה של נתונים ומשאבי מחשוב כדי לאמן מודלים מסוג זה. לדוגמה, מודל GPT-3 אומן על קורפוס של טריליון מילים הכולל את ויקיפדיה, ספריות שלמות של ספרים ונתונים שמקורם בגלישה באינטרנט (שווה ערך לעשרת אלפים שנות דיבור ללא הפסקה בקצב של 100 מילים בדקה). הפתרון הוא להשתמש באותם מודלים מאומנים pretrained models במקום לאמן רשת לכל מטרה. מאז הופעת הארכיטקטורה ב-2017 נוצרו אלפי מודלים שחלק גדול מהם זמין להורדה ולשימוש. כאשר מיזם hugging face מספק ממשק אחיד לשימוש במודלים. במדריך זה נשתמש במודל קלאסי לעיבוד שפה אנושית ששמו BERT כדי להבחין בין הודעות SMS תקינות וספאמיות (ham or spam). המדריך מהווה המשך למדריכים קודמים בסדרה על למידת מכונה בהם סיווגנו הודעות SMS בגישות שונות: זיהוי SMS ספאמי באמצעות bag of words, זיהוי SMS ספאמי באמצעות RNN, זיהוי SMS ספאמי באמצעות RNN ומרחב הטמעה שאומן מראש.

ensemble learning לשיפור ביצועי מודלים של למידת מכונה
בסדרת המדריכים המוקדשת ללמידת מכונה הכרנו מגוון של מודלים. לכל אחד יתרונות וחסרונות בלימוד הבעיה שאנו מנסים לפתור בפרט כאשר המודלים מבוססים על אלגוריתמים שונים. כדי להתגבר על הקשיים הפרטיים של מודלים הנטייה כיום היא לשלב מספר מודלים יחדיו כדי שכל אחד מהם יתרום את החוזקות שלו וכך יחפה על חולשתם היחסית של מודלים אחרים שאיתם הוא עובד בצוותא. שילוב זה מכונה למידה בצוותא ensemble learning. למידה בצוותא ensemble learning דומה למשל ההודי על חמישה עיוורים הממששים פיל. כל אחד מהם ממשש חלק אחר - חדק, חטים, אוזן, רגל, בטן - וכל אחד מתאר את הפיל באופן שונה. הם מצליחים להתקרב להבנה בדבר מהות הפיל רק כאשר הם מתקשרים ביניהם ומסיקים תמונה כוללת.

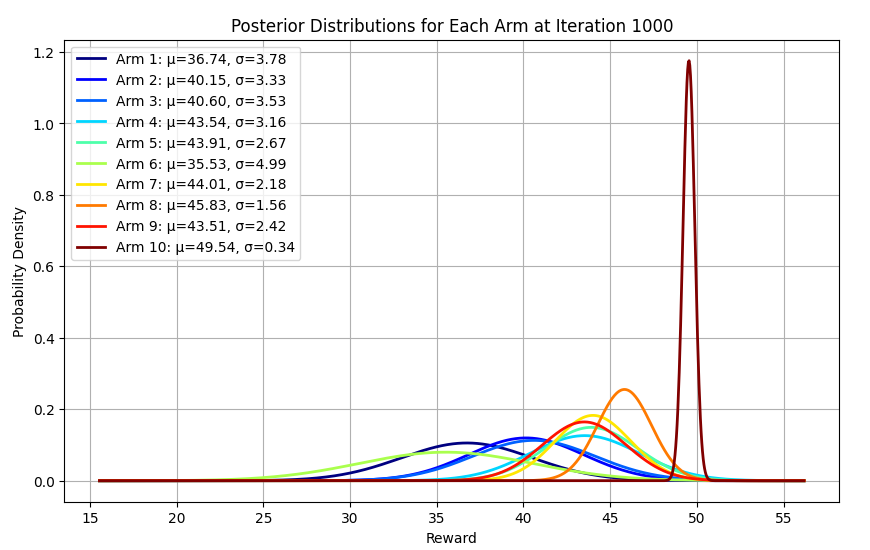
שימוש בדגימת תומפסון להתמודדות עם דילמת השודד בעל הזרועות המרובות
דילמת ה- Multi-Armed Bandit הינה בעיה בה סוכן נדרש לבחור בין מספר חלופות (או זרועות) כדי למקסם את הסך הכולל של הפרסים לאורך זמן. האלגוריתם מאזן בין חקר (Exploration) – איסוף מידע על כל אפשרות, לבין ניצול (Exploitation) – שימוש באפשרות אשר מניבה את התוצאה הגבוהה ביותר בהתבסס על הנתונים הקיימים. במדריך זה תלמד את אחת הדרכים הפשוטות והחזקות ביותר לפתור את הדילמה באמצעות Thompson sampling. נוסף להסברים, המדריך כולל דוגמת קוד Python.
אופטימיזציה עבור למידה בצוותא ensemble learning
תהליך אופטימיזציה מנסה למצוא את נקודות הקיצון (מינימום או מקסימום) של פונקציה. במסגרת למידת מכונה משתמשים באופטימיזציה כדי למצוא את הפרמטרים עליהם מבססים את המודל המוצלח ביותר. במדריך זה נשתמש בשיטות שונות של אופטימיזציה כדי למצוא את הרכב תוצאות המודלים שייתן את התוצאה המוצלחת ביותר עבור תהליך אופטימיזציה של ensemble learning, למידה בצוותא.
מערכת שאלות-תשובות מבוססת בינה מלאכותית
במדריך נשתמש במנוע החיפוש Elasticsearch ובבינה מלאכותית מבוססת טרנספורמר כדי לענות על שאלות אודות מאמר. Elasticsearch הוא מנוע חיפוש המתמחה באיתור טקסט ואף ניתן לשלבו עם מודלים מסוג טרנספורמרים - המובילים בעולם בתחום עיבוד שפה טבעית NLP.
איך לגרום ל GPT-3, מודל הבינה המלאכותית המתקדם בעולם, להבין בדיחה?
GPT-3 הוא מודל שפה שיצרו OpenAI, והוא הגדול והמתוחכם שבהם. הוא אומן על כל המקורות הקיימים באינטרנט, והוא מציג יכולות דומות לאנושיות בתחום השפה. לדוגמה, הוא יכול להסביר בשפה פשוטה מסמכים משפטיים, לכתוב פסקאות שלמות, לכתוב קוד פשוט, ואף ליצור תמונות מדהימות על סמך משפטים שמזינים לתוכו. במדריך זה אני סוקר 3 מהיכולות שלו: כתיבת פסקה קצרה, כתיבת קוד וכישורי שיחה.

פריסת מודל למידת מכונה כאפליקציה אינטרנטית
הפיכת מודל מכונה לחיזוי מחירי דירות לאפליקצית אינטרנט עם FastApi
עבדת על פרויקט למידת המכונה שלך, הצלחת להרים משהו שהוא מספיק מעניין, ועכשיו מגיע אתגר לא פחות משמעותי והוא כיצד לשתף בזה אנשים נוספים. אולי אפילו להנגיש לציבור הרחב. הפתרון יכול להיות אפליקציה אינטרנטית, ומה שאני מדגים במדריך הוא שילוב של מודל מבוסס TensorFlow לחיזוי מחירי בתים בתוך אפליקציה אינטרנטית מבוססת FastApi.

הקמת אפליקציה אינטרנטית למערכת שאלות ותשובות מבוססת בינה מלאכותית
במדריך קודם מערכת שאלות ותשובות מבוססת בינה מלאכותית השתמשנו במנוע החיפוש Elasticsearch עם מודל טרנספורמר כדי לענות על שאלות אודות מאמר. במדריך הנוכחי נהפוך את המערכת לאפליקציה אינטרנטית באמצעותה יזין המשתמש קטע קריאה קצר ושאלה לתוך טופס בדפדפן, המידע ישלח לצד השרת לעיבוד, והתשובה תוצג למשתמש בדפדפן.
היכונו לעידן המכונות החושבות, למידת מכונה בדפדפן באמצעות ספריית TensorFlow.js
גוגל שיחררו את ספריית TensorFlow.js שמאפשרת לעשות למידת מכונה (Machine Learning, ML) בדפדפן. זה פותח עולם חדש ומלהיב של אפשרויות למתכנתי אינטרנט מפני שניתן מעכשיו לשלב יישומים של בינה מלאכותית שכתובים ב-JavaScript בתוך דפי האינטרנט שאנחנו כותבים.

ייצוא מודל בינה מלאכותית לשימוש בדפדפן
אחרי שלמדנו כיצד לפתח מודלים של בינה מלאכותית הגיע הזמן לאפשר למשתמשים רגילים להשתמש בבינה שאנו מפתחים. הממשק שדרכו אנשים בדרך כלל עובדים עם תוכנות הוא באמצעות האינטרנט. מדריך זה מסביר כיצד לייצא מודלים של בינה מלאכותית מבוססי ספריית Keras לדפדפן באמצעות tensorflowjs. הדוגמה שלנו מתבססת על המודל שפתחנו במדריך "מודל לינארי הכולל משתנים קטגוריים לחיזוי מחירי בתים". תוכלו לראות את הקוד בפעולה אם תגללו לתחתית המדריך, ותזינו ערכים לטופס. שימו לב! מחירי הבתים החזויים מבוססים על נתונים של מחירי בתים בסקרמנטו בארה"ב וכל קשר ביניהם ובין המציאות הישראלית מקרי בהחלט.
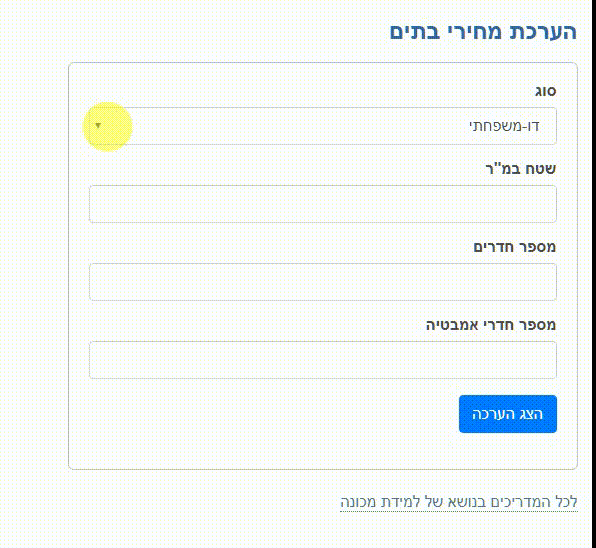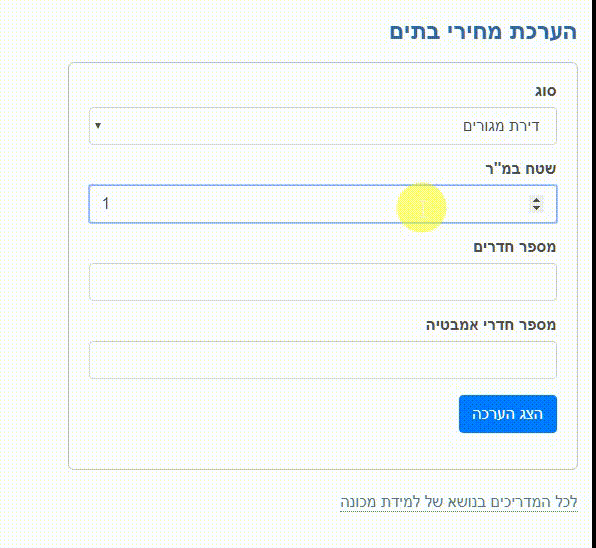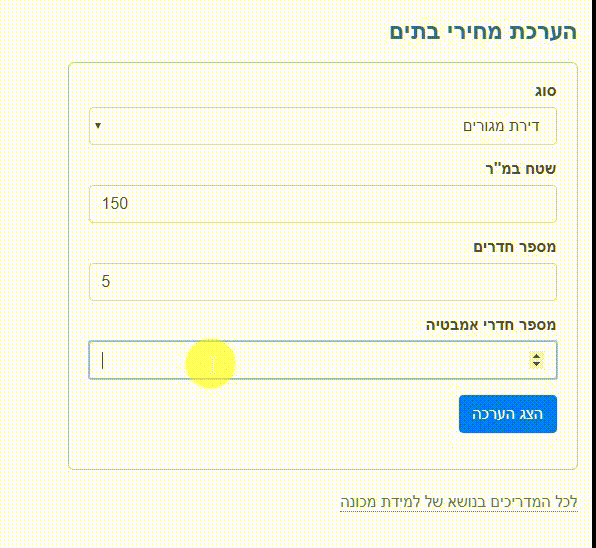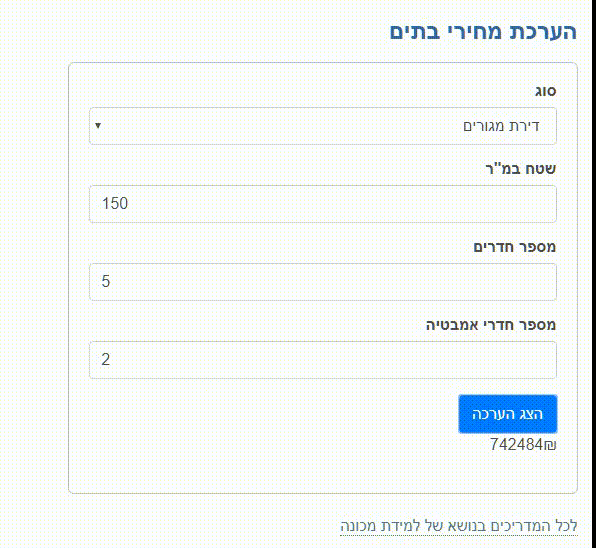
זיהוי ספרות שכתב אדם באמצעות בינה מלאכותית
האפליקציה שנפתח במדריך מאפשרת לאדם לכתוב ספרות בכתב ידו, כשמודל מבוסס בינה מלאכותית מפענח את הכתוב ומציג את ההערכה שלו לגבי מה שכתב המשתמש.
אפליקציית בינה מלאכותית שעונה על שאלות בדפדפן
במדריך הזה ניצור אפליקציה אינטרנטית מבוססת בינה מלאכותית שתענה על שאלות אודות פסקה שנזין לתוכה.
למידה בלתי מפוקחת
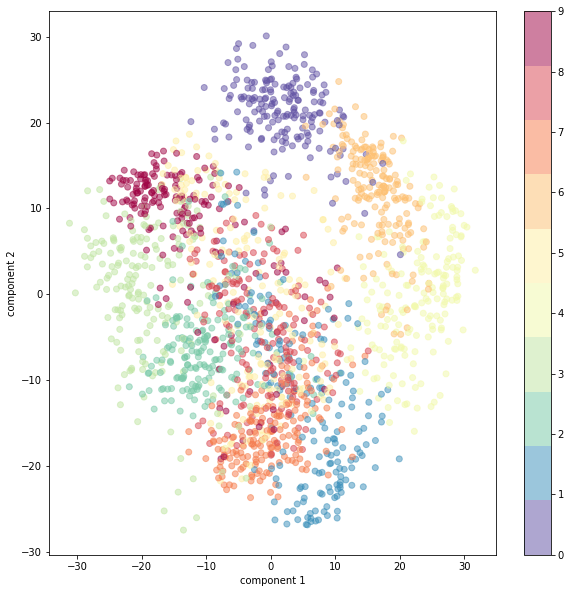
למידת מכונה בלתי מפוקחת באמצעות PCA
ניתוח גורמים ראשיים (Principal Component Analysis, PCA) היא טכניקה בה אנו משתמשים כדי להפחית את הממדיות (= מספר הפיצ'רים) של מערכי נתונים גדולים תוך שמירה על רוב השונות. כאשר, נא לזכור, השונות היא מה שמעניין אותנו במערך הנתונים. הפחתת מימדיות מקריבה דיוק ומעניקה פשטות. התוצאה היא נתונים פחות מדויקים, אבל כאלה שאנחנו יכולים בקלות לצייר מהם תרשים או להשתמש בהם כדי לאמן את המודלים שלנו בזמן קצר יותר. חשוב להבין, שהטכניקה לא משתמשת בממדים הקיימים אלא מארגנת את המידע באופן שיוצר ממדים חדשים קומפקטיים שמצליחים להכיל את המידע במספר מצומצם של ממדים דחוסים. PCA הוא אחד האלגוריתמים הנפוצים ביותר עבור למידה לא מפוקחת במסגרתה המחשב מסווג את הנתונים לקבוצות בלי ידע מוקדם לגבי הקבוצות. למידה בלתי מפוקחת יכולה לספק תובנות מפתיעות על הנתונים. לדוגמה, מחקר רפואי שהתבסס על מספר גדול של מדדים מצא שהמדד שמצליח לחזות באופן הטוב ביותר את הסיכוי ללקות בהתקף לב הוא ירידה בעוצמה של לחיצת היד. במדריך נעשה PCA באמצעות ספריית sklearn
ניקוי תמונות מרעשים באמצעות למידת מכונה
אוטואנקודר autoencoder היא רשת נוירונית שמשחזרת את הקלט שהיא מקבלת בשכבת הפלט. במדריך הנוכחי נלמד לנקות תמונות של ספרות הכתובות בכתב יד מרעשים.
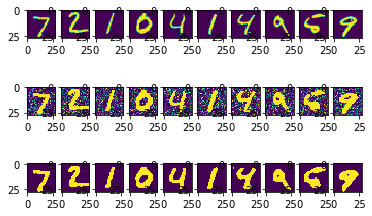
האצת למידת מכונה באמצעות שלב מקדים מבוסס טרנספורמציית PCA
במדריך זה אני בודק כיצד שימוש ב- PCA לצורך הפחתת מספר הממדים משפיע על הזמן והדיוק של אימון מודל Keras על מערך נתונים MNIST. המדריך מבוסס על מדריך קודם שלימד כיצד לפתח מודל מבוסס קונבולוציה כדי ללמד מחשב להבחין בין ספרות הכתובות בכתב יד.
למידת מכונה אוטומטית - Automated machine learning
למידת מכונה אוטומטית (AutoML) מציעה כלים לאיתור אוטומטי של המודלים והפרמטרים המתאימים ביותר לפתרון הבעיה שמעניינת אותך.
בחירת הרכב המודלים ללמידת מכונה באופן אוטומטי על ידי ספריית Auto Sklearn
אתה מכיר את הנושא של למידת מכונה? כבר השתמשת בבינה מלאכותית לפתרון בעיות? אבל שברת את הראש באילו מודלים להשתמש ובאילו פרמטרים. אם זה אתה. אז כדאי שתכיר את תחום האוטומציה של למידת מכונה - חבילות קוד שבוחרות בשבילך את הרכב ensemble המודלים והפרמטרים המתאימים ביותר לביצוע המשימה שעל הפרק. במדריך זה, נכיר את auto-sklearn - ספרייה שמרכיבה למענך אנסמבל אלגוריתמים המספק את התוצאות הטובות ביותר.

מודל לחיזוי השרדות נוסעים על סיפון הטיטניק באמצעות למידת מכונה אוטומטית ו-AutoKeras
הספינה טיטאניק שקעה במצולות הים בשעות הבוקר המוקדמות של 1912 למרות שהיא נחשבה לגדולה והמשוכללת מבין הספינות של התקופה. מ-2,224 נוסעי הספינה שרדו רק 724 מה שהופך את התאונה לאחד האסונות הימיים הגדולים בהיסטוריה. במדריך זה ננסה לחזות אילו נוסעים שרדו את האסון על סמך נתונים דוגמת נמל המוצא, מין הנוסע וגילו. את החיזוי נעשה באמצעות ספריית AutoKeras שתמצא באופן אוטומטי את המודל הטוב ביותר של Keras, ממשק הלמידה העמוקה של גוגל.

שונות
מודל למידת מכונה - XGBoost - לראות את העצים בתוך היער
XGBoost הוא מודל למידת מכונה מבוסס עצי החלטה שמוכיח עליונות על למידת מכונה עמוקה ברוב המקרים וכל עוד מסד הנתונים אינו גדול ומסובך מדי. לדוגמה, המודל זיכה את המשתמשים בו בהצלחה בתחרויות Kaggle על מסדי נתונים טבלאיים. העליונות של XGBoost מתבטאת לא רק בדיוק המודלים אלא גם בהפחתה משמעותית בצריכת משאבי מחשב והאפשרות של אדם לקרוא את עצי ההחלטה שהמודל מפתח ולהבין מה הסיבה לתוצאה בעוד בלמידה עמוקה קשה מאוד להבין מדוע המודל מגיע למסקנה מסוימת. ניתן להשתמש ב-XGBoost לרגרסיה או לסיווג (קלסיפיקציה). במדריך זה נדגים את יכולות הסיווג של המודל שיצטרך לחזות מי שרד את טביעת הטיטניק. במדריך נלמד להכין מסד נתונים מבוססי טבלה ללמידת מכונה באמצעות-XGBoost, כיצד להשתמש במודל, וכיצד לשפר את היכולות שלו באמצעות כוונון פרמטרים hyper parameter tuning.
חיזוי מחירי מכוניות - XGBoost, Optuna, SHAP, ועוד הרבה דברים טובים...
במדריך זה בסדרת למידת המכונה נלמד לחזות מחירי מכוניות. על הדרך:
- נסקור את מסד הנתונים בעזרת pandas_profiling
- נעשה רגרסיה באמצעות XGBoost
- נשפר את ביצועי המודל באמצעות Optuna
- נלמד להעריך את תוצאות המודל
- נבין את הסיבה שהמודל הגיע לתוצאות באמצעות SHAP
- ועוד הרבה דברים טובים...

מה הגורמים החשובים ביותר המנבאים הכנסה גבוהה?
במדריך זה ננסה למצוא את הגורמים האינדיקטיביים ביותר להכנסה גבוהה. לשם כך, נשתמש בנתוני סקר שנאסף בארה"ב בשנת 1994 שסקר גורמים שונים, דוגמת השכלה, מספר שעות עבודה שבועיות, מין וארץ מוצא, וסיווג את הדוגמאות על פי רמת הכנסה גבוהה או נמוכה. במדריך נאמן מודל XGBoost בסיווג דוגמאות על פי רמת הכנסה, וננתח את הנתונים באמצעות SHAP שימצא קשרים בין רמת ההכנסה לבין הגורמים בסקר.
שימוש באלגוריתם גנטי להתמודדות עם בעיה חישובית קשות במיוחד ממחלקה NP
אין דבר מהנה יותר ממציאת פתרון אלגנטי לבעיות תכנותיות במיוחד אם הם קשות ומסובכות ופתרונם מצריך מאמץ רב, אולם קיימות בעיות תכנותיות שהם כל כך מורכבות עד שגם המחשבים החזקים ביותר מתקשים למצוא להם פתרונות בזמן סביר. בעיות אלו שייכות למחלקת NP - בעיות שאין להם פתרון דטרמיניסטי בזמן פולינומי. דוגמה לבעיה מסוג NP היא בעיית התרמיל 0/1 - אשר נחשבת לאתגר אופטימיזציה קלאסי. הבעיה דורשת למקסם את הערך הכולל תחת מגבלות משקל, והיא הולכת ומסתבכת ככל שגדל מספר הפריטים. בעיית התרמיל 0/1 ידועה לשמצה בסיווגה כ-NP, מה שאומר שאין אלגוריתם ידוע בזמן פולינומי שיכול לפתור את כל המקרים באופן מיטבי. הבעיה נובעת מכך שככל שגדל מספר הפריטים אותם ניתן לבחור האם להכניס לתרמיל, גדל מספר השילובים האפשריים באופן אקספוננציאלי כיוון שכל פריט מוסיף שתי אפשרויות (להכניס או להוציא), מה שמוביל ל-2^n שילובים פוטנציאליים עבור n פריטים. מורכבות אקספוננציאלית זו מאפיינת בעיות רבות השייכות למחלקה NP, שלא ידוע על אלגוריתמים יעילים למציאת פתרונות מיטביים עבורם. כיוון שפתרון מיטבי של מקרים מרובי פריטים של בעיית התרמיל לא קיים למעשה, מומחי התכנות פונים לשימוש באלגוריתמים מקורבים שאף שאינם מבטיחים פתרונות מיטביים, הם כן מצליחים לספק תוצאות טובות למדי במסגרת טווחי זמן סבירים. דוגמה אחת היא שימוש באלגוריתם גנטי לצורך מציאת פתרונות מקורבים לבעיה. אלגוריתמים גנטיים, אשר שואבים השראה מתחומי האבולוציה והגנטיקה, עושים שימוש במנגנונים של ברירה, שחלוף, ומוטציה כדי לאפשר לאוכלוסייה של פתרונות פוטנציאליים להתפתח לאורך דורות. בעוד שהפתרון האופטימלי אינו מובטח, אלגוריתמים אילה חוקרים ביעילות מרחבי פתרונות עצומים. היישום במדריך של האלגוריתם הגנטי לבעיית התרמיל מדמה את האבולוציה של אוכלוסיות. הוא משלב אסטרטגיות כגון יצירת ושמירה על שונות, ברירת פרטים לפי מידת כשירות, יישום של שחלוף לצירוף חומר גנטי, והכנסת מוטציות לשיפור השונות. אסטרטגיות אילו, בדומה לתהליכים טבעיים, מנווטות במרחב החיפוש, ומתכנסות לפתרונות העומדים בדרישות הבעיה או לפחות מתקרבים לפתרון אופטימלי. שיפורים נוספים, הכוללים אליטיזם והתאמה דינמית של שיעורי השחלוף, נועדו לשפר את ביצועי האלגוריתם. בנוסף, המדריך ידגים קריטריוני התכנסות כדי לקבוע מתי האלגוריתם הגנטי צריך לסיים לחקור עקב תשואה פוחתת של השיפור במידת הכשירות במעבר בין הדורות. דוגמה לבעיה מסוג NP היא בעיית התרמיל 0/1 - אשר נחשבת לאתגר אופטימיזציה קלאסי. הבעיה דורשת למקסם את הערך הכולל תחת מגבלות משקל, והיא הולכת ומסתבכת ככל שגדל מספר הפריטים. בעיית התרמיל 0/1 ידועה לשמצה בסיווגה כ-NP, מה שאומר שאין אלגוריתם ידוע בזמן פולינומי שיכול לפתור את כל המקרים באופן מיטבי. הבעיה נובעת מכך שככל שגדל מספר הפריטים אותם ניתן לבחור האם להכניס לתרמיל, גדל מספר השילובים האפשריים באופן אקספוננציאלי כיוון שכל פריט מוסיף שתי אפשרויות (להכניס או להוציא), מה שמוביל ל-2^n שילובים פוטנציאליים עבור n פריטים. מורכבות אקספוננציאלית זו מאפיינת בעיות רבות השייכות למחלקה NP, שלא ידוע על אלגוריתמים יעילים למציאת פתרונות מיטביים עבורם. כיוון שפתרון מיטבי של מקרים מרובי פריטים של בעיית התרמיל לא קיים למעשה, מומחי התכנות פונים לשימוש באלגוריתמים מקורבים שאף שאינם מבטיחים פתרונות מיטביים, הם כן מצליחים לספק תוצאות טובות למדי במסגרת טווחי זמן סבירים. דוגמה אחת היא שימוש באלגוריתם גנטי לצורך מציאת פתרונות מקורבים לבעיה. אלגוריתמים גנטיים, אשר שואבים השראה מתחומי האבולוציה והגנטיקה, עושים שימוש במנגנונים של ברירה, שחלוף, ומוטציה כדי לאפשר לאוכלוסייה של פתרונות פוטנציאליים להתפתח לאורך דורות. בעוד שהפתרון האופטימלי אינו מובטח, אלגוריתמים אילה חוקרים ביעילות מרחבי פתרונות עצומים. היישום במדריך של האלגוריתם הגנטי לבעיית התרמיל מדמה את האבולוציה של אוכלוסיות. הוא משלב אסטרטגיות כגון יצירת ושמירה על שונות, ברירת פרטים לפי מידת כשירות, יישום של שחלוף לצירוף חומר גנטי, והכנסת מוטציות לשיפור השונות. אסטרטגיות אילו, בדומה לתהליכים טבעיים, מנווטות במרחב החיפוש, ומתכנסות לפתרונות העומדים בדרישות הבעיה או לפחות מתקרבים לפתרון אופטימלי. שיפורים נוספים, הכוללים אליטיזם והתאמה דינמית של שיעורי השחלוף, נועדו לשפר את ביצועי האלגוריתם. בנוסף, המדריך ידגים קריטריוני התכנסות כדי לקבוע מתי האלגוריתם הגנטי צריך לסיים לחקור עקב תשואה פוחתת של השיפור במידת הכשירות במעבר בין הדורות.
PyTorch
10 דברים שחובה להכיר כשעובדים עם טנסורים של pytorch
אחת המיומנויות החשובות ביותר כשעובדים עם pytorch היא עבודה עם טנסורים. במדריך זה 10 דברים שחשוב להכיר כשעובדים עם טנסורים של pytorch.

רגרסיה קווית להערכת מחירי דירות באמצעות PyTorch ולמידת מכונה
רגרסיה משמשת למציאת המידה שבה נתון מספרי אחד משפיע על אחר. במדריך זה נמצא רגרסיה קווית המתארת את השינוי במחיר דירה ביחס לשטח באמצעות למידת מכונה בעזרת ספריית PyTorch.

סיווג תמונות באמצעות למידת מכונה מבוססת PyTorch
במדריך זה נפתח מודל בינה מלאכותית המבוסס על רשת נוירונית מבוססת קונבולוציה CNN שילמד את עצמו כיצד לסווג תמונות לקטגוריות באמצעות ספריית PyTorch.
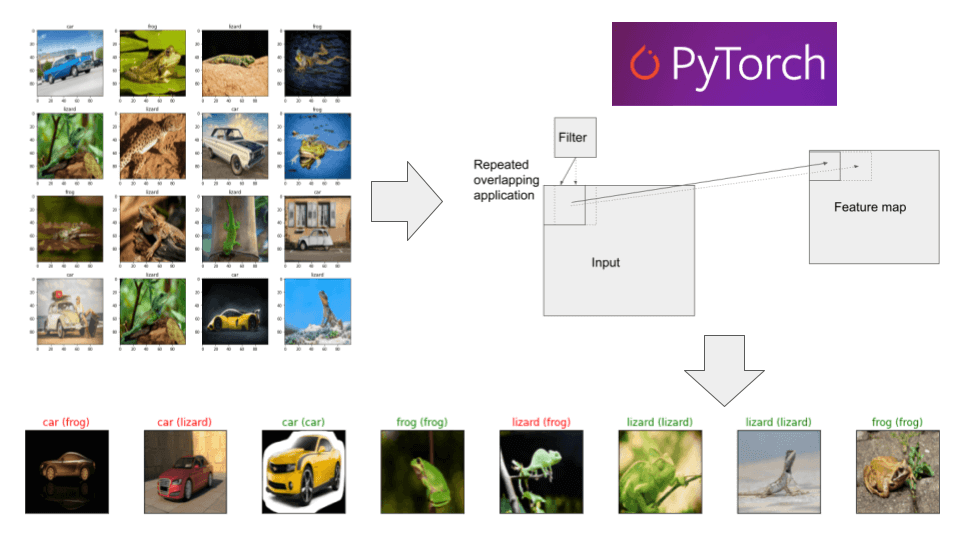
סיווג בינארי עם PyTorch - מתי ואיך
סיווג בינארי הוא מצב שבו נדרש לסווג דוגמאות לאחת משתי קטגוריות מובחנות. לדוגמה, אבחנה בין תמונות כלבים וחתולים, בחירה האם לזמן שחקן לאימוני הנבחרת ואבחנה בין יינות משובחים ופשוטים. במדריך זה נלמד לסווג נקודות במרחב לאחת משתי קבוצות (אדומים לעומת כחולים) באמצעות ספריית PyTorch בגישה של רגרסיה לוגיסטית logistic regression שעיקר השימוש בה הוא בשביל סיווג בינארי.
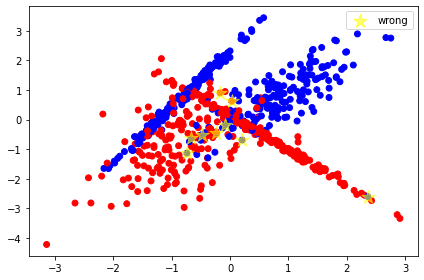
חיזוי טמפרטורות בעזרת RNN וספריית PyTorch
חיזוי סדרות נתונים מציב אתגר משמעותי בפני למידת מכונה בגלל שהמחשב צריך לזכור את תוצאות השלבים הקודמים של תהליך הלמידה מה שרשת נוירונית רגילה feed forward network לא יודעת לעשות. אחת הדרכים הוותיקות לטפל בבעיה היא באמצעות רשתות מסוג RNN - Recurrent Neural Networks. ברשת נוירונית שמיישמת ארכיטקטורת RNN לכל יחידה cell יש מצב state המאפשר לזכור מידע שמקורו בשלבים קודמים בתהליך הלמידה. RNN יכול לשמש למשימות שדורשות עבודה עם רצפים. כדוגמת, שפה שמורכבת מרצף של מילים, סרטונים שעשויים מרצף של פריימים או מידע התלוי בחילופי העיתים, מחזורי שפל וגאות כלכלית או מחזור כתמי השמש.
ניתוח סנטימנט - הבנת רגשות ההמון באמצעות בינה מלאכותית
מערכות בינה מלאכותית הגיעו לשלב שבו הם יכולות להבין את כוונת האדם על סמך טקסט שכתב באמצעות ניתוח סנטימנט sentiment analysis מה שיכול לעזור למפרסמים ומשווקים שרוצים לדעת מה רוצה ההמון כדי לעשות מזה הון. במדריך זה נערוך ניתוח סנטימנט כדי לחוש את רגשות הציבור על סמך תגובות גולשים באתר. במסגרת המדריך, נכיר את עולם עיבוד שפות אנוש על ידי מחשבים, NLP, נגרד תגובות מדף אינטרנט, ונערוך ניתוח סנטימנט באמצעות מודל BERT מתקדם.

מדריכים קצרים וקטעי קוד
כיצד לשפר רזולוציה של תמונה באמצעות למידת מכונה?
מצאת באינטרנט תמונה קטנה מדי של מוצר שעשוי לעניין אותך ואתה רוצה לראות אותה ברזולוציה גבוהה יותר? או שתמונות שצילמת הם קטנות מכדי שניתן יהיה לשתף אותם ברשת החברתית? מה אפשר לעשות? הפתרון היחיד הוא להעלות את הרזולוציה של התמונות, ואת זה נעשה באמצעות שימוש בבינה מלאכותית. במדריך זה, נלמד כיצד לשפר דרמטית את הרזולוציה של תמונות באמצעות ספריית פייתון פשוטה לשימוש מבוססת למידת מכונה.

נסיעת מבחן למערכת בינה מלאכותית לשכתוב תוכן של AI21 labs
אחד התסכולים הגדולים של מלאכת הכתיבה הוא שיכתוב טקסט כדי להביא אותו לרמה טובה, ולכן טוב שיש כלים שיכולים לעזור. חברת AI21 Labs שחררה גרסת בטא של rewrite - כלי מבוסס בינה מלאכותית המסייע בשכתוב משפטים. כרגע, הכלי זמין לקבוצה נבחרת של משתמשים. לקחתי אותו לנסיעת מבחן.

heBERT - מודל Transformer בעברית
BERT הוא מודל מסוג Transformer לעיבוד שפות אנוש (NLP) שגוגל שחררו ב-2017. מאז המודל והטכנולוגיה הספיקו לשנות את העולם, ועכשיו אפשר ליהנות מיכולות המודל בעברית בזכות heBERT שיודע לעבוד עם עברית. במדריך הזה אני סוקר את יכולות המודל כמו שהוא, בלי אימון נוסף.

סטטיסטיקה והסתברות
סטטיסטיקה היא תהליך קבלת החלטות במצבי אי וודאות.
סטיית תקן ושגיאת תקן
- סטיית התקן (σ) מתארת את השונות בתוך המדגם.
- שגיאת התקן (SE) מתייחסת לדיוק אומדן סטטיסטי המבוסס על מדגם לגבי כלל האוכלוסיה.
רווח בר סמך confidence interval
בגלל שממוצע המדגם הוא רק הערכה רצוי להגדיר טווח בתוכו עשוי להימצא בסבירות רבה הפרמטר המבוקש באוכלוסיה כולה. במדריך זה נלמד על הדרך להגדיר טווח ביטחון לפרמטר סטטיסטי באמצעות רווח בר סמך.
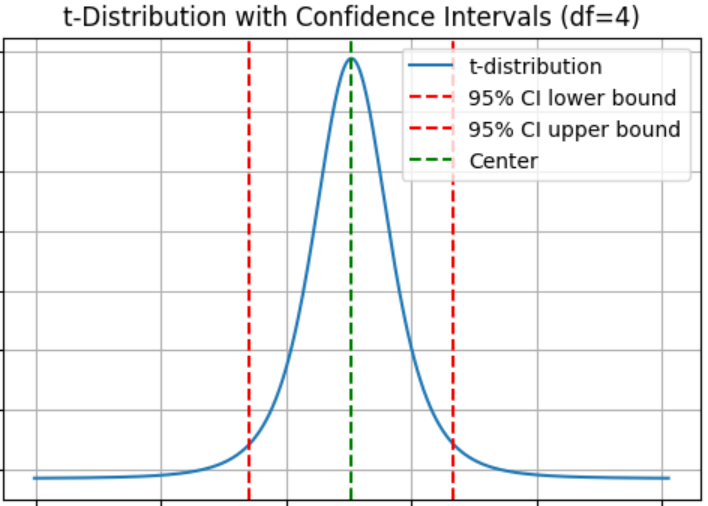
משפט הגבול המרכזי: הצדקה לשימוש במבחנים הדורשים התפלגות נורמלית גם על נתונים לא נורמליים
משפט הגבול המרכזי central limit theorem חשוב ללמידת מכונה כיוון שהוא מאפשר לנו להניח שהתפלגות הדגימות של אוכלוסייה היא נורמלית מה שמאפשר לנו לעבוד עם טכניקות סטטיסטיות שמניחות התפלגות נורמלית אפילו אם האוכלוסייה לא נורמלית.
מבחני חי בריבוע לבדיקת השערות עם פייתון
משתמשים במבחני חי בריבוע Chi-Square לבחינת השערות על התפלגות האוכלוסייה לקטגוריות. מבחן חי בריבוע בוחן את שכיחות התצפיות בקטגוריות, ומנסה למצוא האם קטגוריה אחת (או שילוב של קטגוריות) הוא נפוץ יותר מהצפוי. במדריך זה נעשה מבחנים לבחינת השערות עם פייתון ונסביר למה לעשות, מה לעשות, ואיך.

הסתברות אומרת לנו מה הסבירות שאירוע מסוים יקרה.
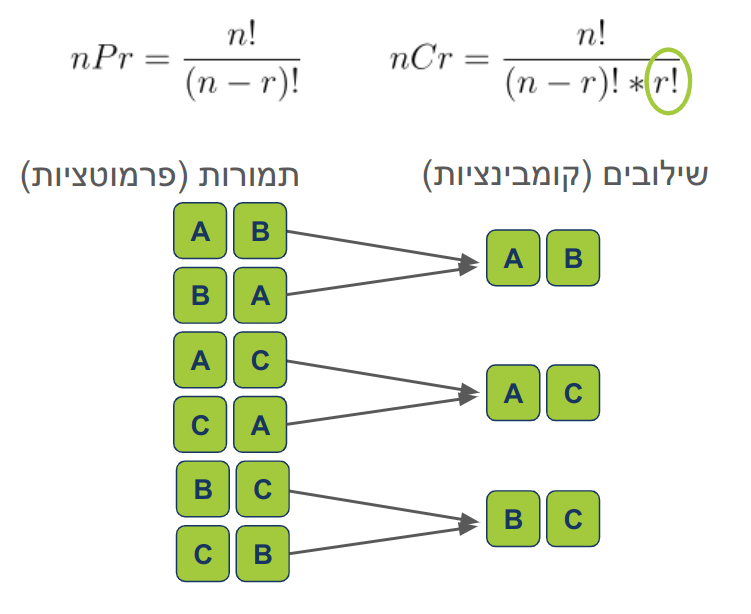
תמורות ושילובים בתורת הצירופים
הקומבינטוריקה. נבין איך לחשב, מה הסיבה, נתרגל באמצעות דוגמאות מהחיים, ונקנח בחישוב הסיכוי לזכות בלוטו.
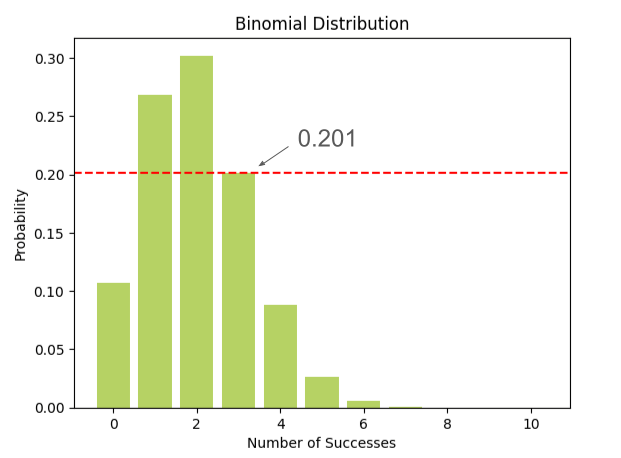
התפלגות בינומית - הלכה למעשה
התפלגות בינומית היא אחת התפלגויות השימושיות בתחום הסטטיסטיקה. במדריך נטעם מההתפלגות הבינומית בעזרת דוגמה טעימה במיוחד, ונקנח עם קוד פייתון.
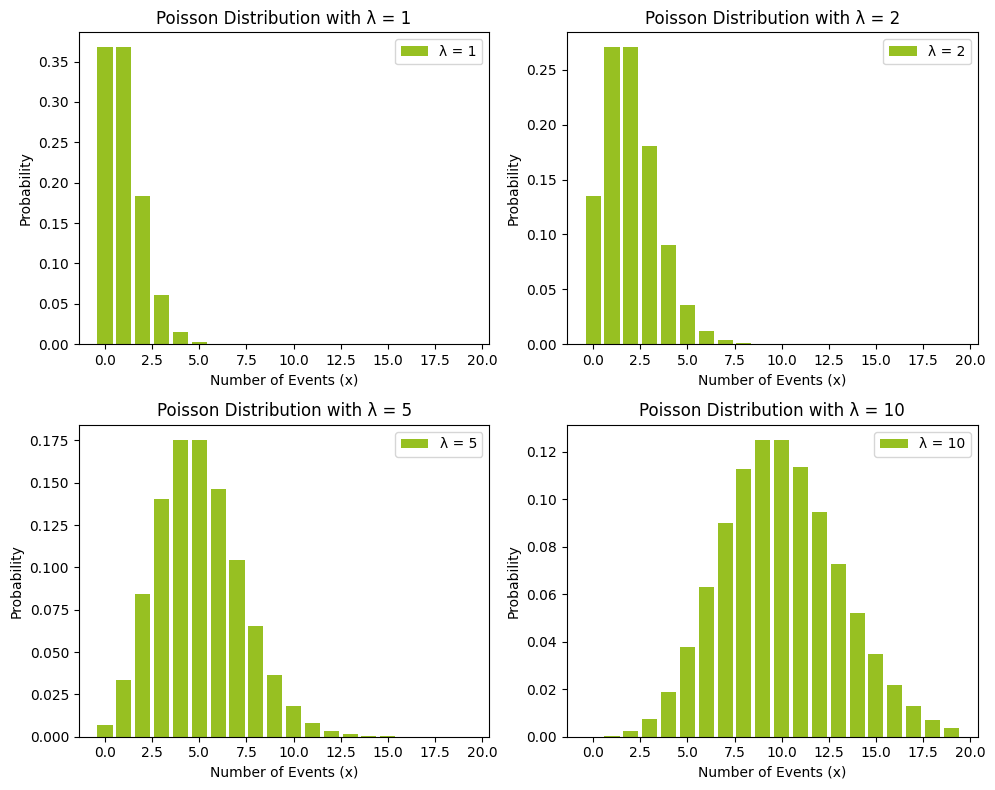
מדריך מעשי על התפלגות פואסנית באמצעות קוד פייתון וציפורים נודדות
בהסתברות פואסונית (Poisson) משתמשים כדי להעריך את הסיכויים להתרחשות אירועים בלתי תלויים אשר קורים בקצב קבוע. במדריך זה נבין מתי להשתמש בהסתברות ואיך להשתמש בהסתברות באמצעות קוד פייתון.
מדריך הסתברות מעריכית (אקספוננציאלית) מהלכה למעשה עם פייתון
התפלגות מעריכית (אקספוננציאלית) מתארת משתנים רציפים (יכולים לקבל כל ערך בטווח) וחיוביים. היא מתארת את הזמן החולף בין אירועים המתרחשים בקצב קבוע ללא תלות באירועים קודמים. עצמאות זו מאירועים קודמים הופכת את ההסתברות המעריכית לחסרת זכרון. ההתפלגות המעריכית שימושית לניתוח זמני המתנה, לחיזוי אירועים עתידיים, ותכנון מערכות. דוגמאות לאירועים המתפלגים מעריכית הינם: הזמן במילישניות בין התפרקויות רדיואקטיביות, הזמן בדקות עד למענה לשיחות במוקד שיחות, הזמן בשעות בין לחיצות על לינק בדף אינטרנט, או הזמן בשנים בין רעידות אדמה.

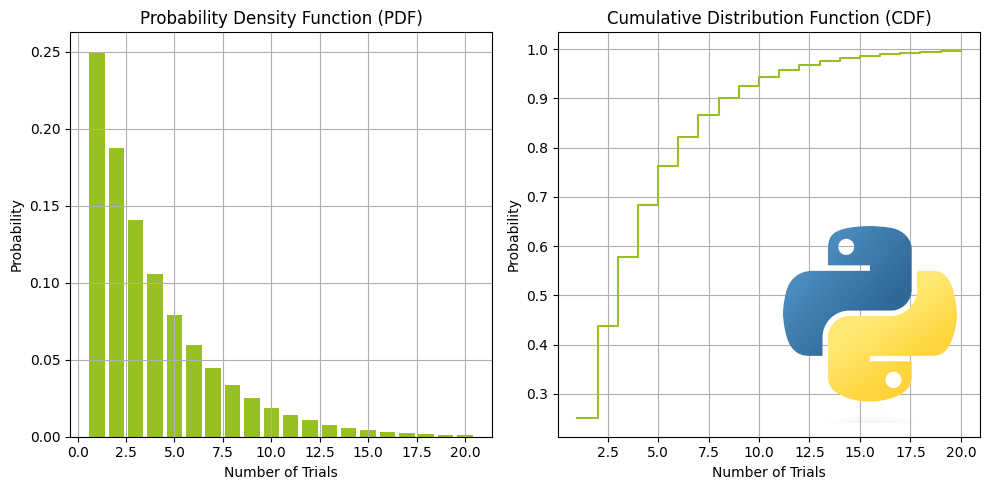
התפלגות גיאומטרית ישר ולעניין עם קוד פייתון
משה מהפועל ארגזים עולה מהספסל וידוע שהוא מבקיע בממוצע 25% מהפנדלים שהוא בועט. מה הסיכוי שלו להבקיע בפעם הראשונה בניסיון השלישי? זו דוגמה לבעיה שאפשר לענות עליה בעזרת התפלגות גיאומטרית. ההתפלגות הגיאומטרית עוסקת בספירת הניסיונות הדרושים כדי להגיע להצלחה הראשונה בסדרה של ניסויים עצמאיים.
התפלגות בינומית שלילית עם פייתון
בשקית שמכילה סוכריות טופי בטעמים שונים ידוע ש-30% מהסוכריות הם בטעם קרמל. מה הסיכוי לאכילת 4 סוכריות בטעם קרמל אם אוכלים 10 סוכריות? זו רק טעימה מסוג הבעיות אותם ניתן לפתור באמצעות התפלגות בינומית שלילית. על ההתפלגות ועל הבעיות אותם ניתן לפתור באמצעותה תוכלו לקרוא במדריך.

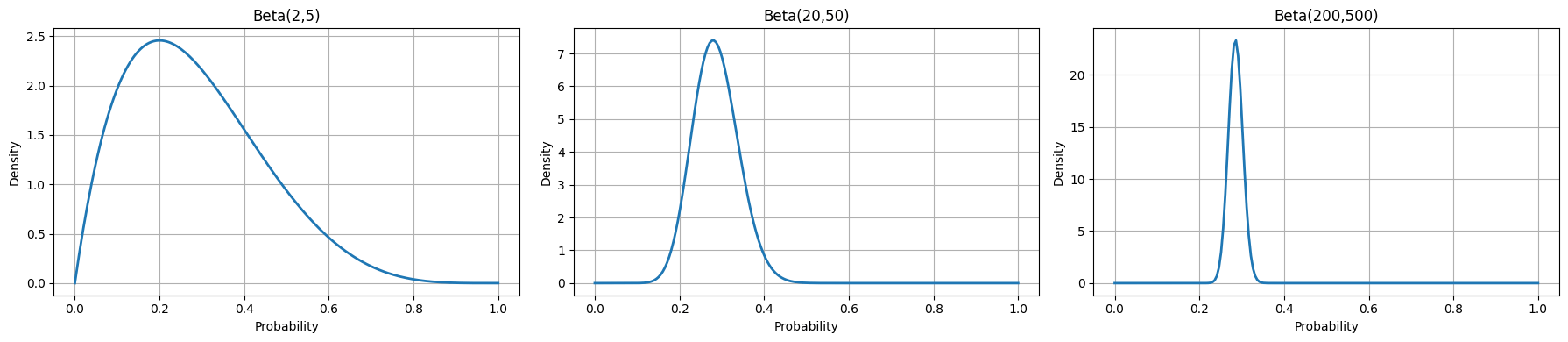
התפלגות בטא ותהליך העדכון הבייסיאני
הרבה פעמים אנחנו משתמשים בסטטיסטיקה על מנת לייצר מודל של אי ודאות לגבי הסתברויות - בין אם זה הסיכוי של מטבע לנחות על ראשו או שיעור ההצלחה של קמפיין שיווקי. התפלגות בטא, התחומה לרוב בין הערכים [0,1], היא בחירה טבעית עבור משימות אילו. מדריך זה יוליך את הקורא בנתיב המוביל להתפלגות בטא, יסביר את מקרי השימוש בה, יציג עדכון בייסיאני כמסגרת לבחינת הסתברויות, ויסיים בדוגמה מעשית של קוד Python.
חיפוש אחר משמעות סטטיסטית בגן השבילים המתפצלים
המרדף אחר ידע כרוך לעיתים קרובות במרדף אחר מובהקות סטטיסטית. אתה מחפש תבניות, מגלה מגמות, ומנסה לספר סיפור קוהרנטי על העולם. אך מה קורה כאשר החיפוש הזה מוביל אותך אל תוך מבוך סמוי מן העין, אשליה סטטיסטית. שני כשלים קשורים אך נפרדים עלולים להכשיל אותך בדרך: p-hacking וגן השבילים המתפצלים.

שינוי בסיס: איך להעביר וקטור מבסיס לבסיס באלגברה לינארית?
ההופכי של מטריצת המעבר מאפשר לנו לתרגם וקטורים מבסיס אחד לבסיס אחר בתהליך הנקרא שינוי בסיס.

SVD - Singular Value Decomposition באמצעות פייתון
במדריך זה נראה איך לבצע SVD בפייתון וכיצד להשתמש בהליך לדחיסת מידע.
פירוק לגורמים P)LU) גם באמצעות פייתון
מה זה פירוק לגורמים? אם אתה קורא מדריך על נושא די מתקדם בתחום האלגברה הלינארית אז אתה בטוח יודע. למשל, אפשר לפרק את המספר 42 למכפלה של 6 כפול 7 (42 = 7 * 6). אפשר גם לפרק אותו למכפלה של 2 כפול 21 (42 = 2 * 21). פירוק LU עושה משהו דומה, אבל למטריצות! אנחנו מנסים לפרק מטריצה למכפלה של שתי מטריצות אחרות, שנקראות L ו-U. כשאנחנו עובדים על מטריצות זה עוזר לנו לפתור בעיות מסובכות בצורה יותר קלה.

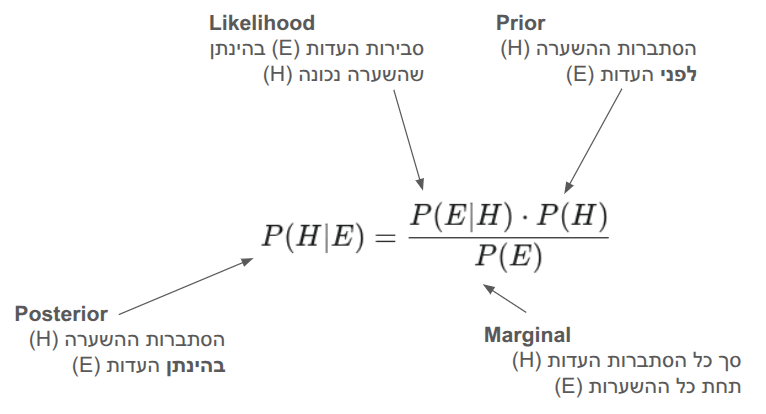
מה ההצדקה לשימוש ב-Naive Bayes Classifier בלמידת מכונה
איך הופכת נוסחת בייס למודל שמנבא אם תקבל מייל ספאם, ביקורת שלילית, או צלחת מעופפת חייזרית? במדריך זה תלמד מדוע הסיווג הבייסיאני הנאיבי מצליח למרות הנחתו הפשטנית, ונראה כיצד מחשבים צעד־צעד את ההסתברויות מאחורי אחת השיטות הוותיקות והאמינות בלמידת מכונה.

סיווג טקסטים (בעיקר) באמצעות מודלים של Naive Bayes Classifier
עולם סיווג הטקסט בנוי על רעיון פשוט: המרת מסמכים לוקטורים מספריים, והחלטה לאיזו מחלקה הם שייכים. גישות שונות של למידת מכונה פותחו כדי לענות על השאלה לאיזו מחלקה שייך המסמך ואחת הבולטות מבוססת על Naive Bayes אשר נחשב לסוס העבודה של עולם עיבוד השפה NLP (Natural Language Processing).

מדריכים ישנים בסדרה על למידת מכונה
ואידך זיל גמור...

נכתב ע"י יוסי בן הרוש
מתכנת אתרי אינטרנט, מומחה Laravel ו-Angular, והכותב של כל התכנים ב רשתטק תכנות אתרי אינטרנט