
מדריך Awk - פקודה של Bash שהיא גם (סוג של) שפת תכנות
Awk היא פקודה של Bash וגם שפת תכנות. נעזרים בה בעיקר כשעובדים עם עמודות.

נוסיף את הקובץ "cars.text":
$ touch cars.textבתוכו נכתוב מידע המכיל עמודות:
BMW i7 1250000
jaguar F-PACE 380000
mercedes CL-Class 370000
tesla Model3 216000
ferrari 812GTS 2300000
maserati Grecale 440000נדפיס את העמודה הראשונה:
$ awk '{print $1}' cars.textהתוצאה:
BMW
jaguar
mercedes
tesla
ferrari
maserati- עבור awk רווחים מפרידים בין העמודות.
השורות במלואן מאוחסנות בתוך המשתנה $0 וניתן לגשת לכל אחת מהעמודות על פי מספר: $1 לעמודה הראשונה, $2 לשנייה וכיו"ב. העמודה האחרונה מאוחסנת בתוך המשתנה $NF.
נדפיס את העמודה השנייה:
$ awk '{print $2}' cars.textהתוצאה:
i7
F-PACE
CL-Class
Model3
812GTS
Grecaleאפשר להדפיס יותר מעמודה אחת:
$ awk '{print $1 $2 $3}' cars.textהתוצאה:
BMWi71250000
jaguarF-PACE380000
mercedesCL-Class370000
teslaModel3216000
ferrari812GTS2300000
maseratiGrecale440000- התוצאה הודפסה ללא רווחים בין העמודות.
נוסיף רווח של תו אחד בין העמודות כדי לשפר את המראה:
$ awk '{print $1" "$2" "$3}' cars.textהתוצאה:
BMW i7 1250000
jaguar F-PACE 380000
mercedes CL-Class 370000
tesla Model3 216000
ferrari 812GTS 2300000
maserati Grecale 440000אפשר לרווח עוד יותר ע"י הוספת tab בין העמודות:

התוצאה:
BMW i7 1250000
jaguar F-PACE 380000
mercedes CL-Class 370000
tesla Model3 216000
ferrari 812GTS 2300000
maserati Grecale 440000- בתחביר זה אפשר להשתמש בכל תו בתור מפריד בין העמודות שיוצג בפלט.
לא תמיד ההפרדה בין העמודות היא באמצעות רווח. לדוגמה, הקובץ /etc/passwd משתמש בנקודתיים (:).
נערוך את התוכן של הקובץ שלנו "cars.text" כדי שנקודתיים יפרידו בין העמודות:
BMW:i7:1250000
jaguar:F-PACE:380000
mercedes:CL-Class:370000
tesla:Model3:216000
ferrari:812GTS:2300000
maserati:Grecale:440000בגלל שברירת המחדל של awk למפריד בין עמודות הוא רווח נעביר לפקודה הוראה למפריד אחר. נקודתיים כי זה מה שמפריד בין העמודות בקובץ שלנו:
$ awk -F ':' '{print $1}' cars.text- העברנו לאופציה F את התו ":" כדי שזה ישמש כמפריד בין השדות
התוצאה:
BMW
jaguar
mercedes
tesla
ferrari
maseratiנשתמש ב-$NF כדי להדפיס את העמודה האחרונה בכל שורה:
$ awk -F ':' '{print $NF}' cars.textהתוצאה:
1250000
380000
370000
216000
2300000
440000
שימוש בביטויים ב-Awk
עוד אפשרות שימושית במיוחד היא לסנן שורות על בסיס מחרוזות המופיעות בהם.
לדוגמה, נדפיס שורות רק בתנאי שהן מכילות את הביטוי "tesla":
$ awk '/tesla/ {print $0}' cars.textהתוצאה:
tesla:Model3:216000- מגדירים את הביטוי שמחפשים בין סלאשים. במקרה זה "/tesla/"
- השתמשנו ב-$0 כדי להדפיס את כל אורך השורה
הביטוי לא חייב להיות מדויק. אנחנו יכולים להשתמש בביטוי רגולרי. לדוגמה, להדפיס רק את השורות הכוללות את הביטוי "class" בלי להתחשב האם האותיות הם גדולות או קטנות:
$ awk 'tolower($0) ~ /class/ {print $0}' cars.text- $0 כדי לקבל את כל השורה
- הפקודה tolower הופכת את הטקסט לאותיות קטנות
- הביטוי הרגולרי מחפש התאמה ל-"class"
התוצאה:
mercedes:CL-Class:370000הנושא של ביטויים רגולריים הוא רחב ומעניין מאוד. סקרתי אותו בהרחבה במדריך ביטויים רגולריים בפייתון. במדריך זה אציג טעימה קלה מהיכולת של ביטויים אילה שהשימוש בהם מסייע רבות כשעובדים עם מחרוזות.
אפשרות נוספת לשימוש בביטויים רגולריים היא לבחור בין כמה אפשרויות בתוך סוגריים כאשר החלופות מופרדות בפייפים. במקרה זה, נבחר בשורות המכילות את הביטוי "model" או "class":
$ awk 'tolower($0) ~ /(class|model)/ {print $0}' cars.textהתוצאה:
mercedes:CL-Class:370000
tesla:Model3:216000אנחנו יכולים להשתמש במפריד שאינו רווח להפרדה בין עמודות וגם להגדיר שבתוצא (output) יוצג מפריד אחר.
לדוגמה, נהפוך את המפריד המקורי (:) בקלט למפריד טאב בפלט:

- המשתנה FS מפריד את השורות לעמודות בקלט באמצעות ביטוי רגולרי (שהוא במקרה שלנו :)
- המשתנה OFS קובע מה יהיה המפריד בין העמודות בפלט.
התוצאה:
BMW i7 1250000
jaguar F-PACE 380000
mercedes CL-Class 370000
tesla Model3 216000
ferrari 812GTS 2300000
maserati Grecale 440000בוא נראה דוגמה מהחיים מקובץ /etc/shells המכילה את רשימת ה-shells (שורת הפקודות שאנחנו רואים בטרמינל דוגמת bash).
נציג את תוכן הקובץ בטרמינל באמצעות הפקודה:
$ cat /etc/shellsכך זה נראה אצלי:
# /etc/shells: valid login shells
/bin/sh
/bin/bash
/usr/bin/bash
/bin/rbash
/usr/bin/rbash
/bin/dash
/usr/bin/dash
/usr/bin/sh- הנתיב המלא של כל ה-shells
במקום הנתיב המלא ניקח רק את החלק האחרון בכל שורה באמצעות $NF:

- שימוש בסלאש "/" בתור המפריד בין השדות (במקום ברווח)
- הביטוי הרגולרי תחום בין שני סלאשים //
- בתוך הביטוי הסמל "^" מציין את תחילת השורה
- חייבים לעשות אסקייפ של הסלאש כדי ש-bash לא יתבלבל בין הסלאשים
התוצאה:
sh
bash
bash
rbash
rbash
dash
dash
sh- בין השאר קיבלנו תוצאות כפולות. לדוגמה, פעמיים bash ופעמיים sh.
נעשה פייפ לפקודה uniq כדי לקבל תוצאות ייחודיות:

התוצאה:
sh
bash
rbash
dashאת הנושא של פייפים והפניות הסברתי במדריך "לינוקס - צינורות והפניות".
נסדר את התוצאות בסדר עולה באמצעות פייפ לפקודה sort:

התוצאה:
bash
dash
rbash
sh
Awk גם על פקודות
עד כה עבדנו עם awk על קבצים עם התחביר:
awk '{...}' /path/to/file
ניתן לעשות פייפ של פקודה ולהעביר ל-awk עם תחביר:
[command] | awk '{...}'
הפקודה df של לינוקס מציג את כמות המקום החופשי במערכת הקבצים:
$ dfכך זה נראה על המחשב שאני עובד עליו כרגע:
Filesystem 1K-blocks Used Available Use% Mounted on
tmpfs 1625308 3764 1621544 1% /run
/dev/sda3 459848776 299298232 137117996 69% /
tmpfs 8126528 257180 7869348 4% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
/dev/sda2 524272 5368 518904 2% /boot/efi
tmpfs 1625304 2444 1622860 1% /run/user/1000נעשה לפקודה df פייפ ל-awk ונציג רק את 3 העמודות הראשונות של השורות המכילות את הביטוי "dev/sda":
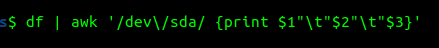
- כפי שראינו בדוגמה קודמת, צריך לעשות אסקייפ לסלאש כדי שיעבוד.
התוצאה:
/dev/sda3 459848776 299300336
/dev/sda2 524272 5368
שימוש ב-Awk כשפת סקריפט
Awk היא שפת סקריפט ולכן, לדוגמה, אפשר לבצע פעולות חשבוניות על עמודות.
לחבר בין שתי עמודות:
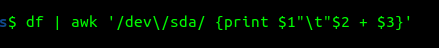
התוצאה אצלי:
/dev/sda3 759147764
/dev/sda2 529640לסכום את העמודה השנייה:
$ df | awk '{s+=$2} END {print s}'
נשתמש בפקודה length כדי לקבל את אורך השורות:
$ awk '{print length($0)}' cars.text- כל מה שקיים בשורה מאוחסן בתוך המשתנה $0
- הפונקציה length() מחזירה את אורך המחרוזת, מספר התווים
התוצאה:
14
20
24
19
22
23נדפיס את השורות בתנאי שמספר התווים גדול מ-20:
$ awk 'length($0) > 20' cars.textהתוצאה:
mercedes:CL-Class:370000
ferrari:812GTS:2300000
maserati:Grecale:440000
הפקודה ps משמשת להצגת כל התהליכים של המשתמש. נריץ אותה:
$ ps -efנבחר מתוך התהליכים במערכת רק את אילו השייכים לתהליך "mysqld" במדויק:
$ ps -ef | awk '{ if($NF == "/usr/sbin/mysqld") print $0}'לא תמיד אנחנו יודעים את הנתיב המלא של תהליך. במקרים אילה ביטוי רגולרי יכול לפתור את הבעיה.
נעזר בביטוי רגולרי כדי למצוא את כל התהליכים שהנתיב בהם כולל את הביטוי "mysql":
$ ps -ef | awk '{ if($NF ~ /mysql/) print $0}'
נחזור לקובץ "cars.text".
כמה שורות בקובץ?
$ awk 'END {print NR}' cars.textהתוצאה:
6נציץ ב-5 השורות הראשונות של הקובץ:
$ awk 'NR < 6' cars.textהתוצאה:
BMW:i7:1250000
jaguar:F-PACE:380000
mercedes:CL-Class:370000
tesla:Model3:216000
ferrari:812GTS:2300000נוסיף מספור לשורות:
$ awk 'NR < 10 {print NR, $0}' cars.textהתוצאה:
1 BMW:i7:1250000
2 jaguar:F-PACE:380000
3 mercedes:CL-Class:370000
4 tesla:Model3:216000
5 ferrari:812GTS:2300000
6 maserati:Grecale:440000נדפיס את השורה השלישית בלבד:
$ awk 'NR==3' cars.textהתוצאה:
mercedes:CL-Class:370000נדפיס את השורות 2 עד 4:
$ awk 'NR==2, NR==4' cars.textהתוצאה:
jaguar:F-PACE:380000
mercedes:CL-Class:370000
tesla:Model3:216000נדפיס כל שורה שנייה החל מהשורה הראשונה:
$ awk 'NR%2==1' cars.textהתוצאה:
BMW:i7:1250000
mercedes:CL-Class:370000
ferrari:812GTS:2300000זה יכול לעבוד עם כל שורה שלישית:
$ awk 'NR%3==1' cars.textנדפיס את כל השורות בהם העמודה השלישית היא בין הערכים 400,000 עד 2,000,000:
$ awk -F ":" '($3 >= 400000 && $3 <= 2000000)' cars.textהתוצאה:
BMW:i7:1250000
maserati:Grecale:440000
ניתן לבחור תת מחרוזת בעזרת הפונקציה substring() בתחביר:
substr(s, i, n)
- מחזיר n תווים ממחרוזת s החל מעמדה i
- הפרמטר n אינו חובה
נבחן את הפונקציה על המחרוזת אותה נדפיס למסך:
$ echo "I love awk"נשתמש בפייפ כדי להעביר ל-Awk לצורך הפעלת הפונקציה substr() וקבלת חלקי המחרוזת שמעניינים אותנו:
$ echo "I love awk" | awk '{print substr($0,1,1)}'נקרא את הפרמטרים משמאל לימין:
- $0 מציין שאנחנו רוצים את כל המחרוזת
- 1 כי אנו רוצים להתחיל מהעמדה הראשונה
- 1 כי אנו רוצים להחזיר תו יחיד
התוצאה:
Iנתחיל להדפיס מהעמדה הרביעית ועד לסוף השורה:
$ echo "I love awk" | awk '{print substr($0,3)}'התוצאה:
ove awk
Awk היא שפת סקריפט. ואכן, אפשר להריץ אפילו לולאות.
לולאת for:
$ awk 'BEGIN { for (i = 0; i <= 10; ++i) {print "index is: ", i} }'- בין הסוגריים המסולסלים אנחנו כותבים את הקוד לביצוע.
התוצאה:
index is: 0
index is: 1
index is: 2
index is: 3
index is: 4
index is: 5
index is: 6
index is: 7
index is: 8
index is: 9
index is: 10נכתוב יותר מפקודה אחת בין הסוגריים המסולסלים:
$ awk 'BEGIN { for (i = 1; i <= 10; ++i) {print i; if (i%3==0) print "Aleerie"}}'התוצאה:
1
2
3
Aleerie
4
5
6
Aleerie
7
8
9
Aleerie
10לולאת while:
$ awk 'BEGIN { i = 1; while (i <= 10) {print "random # ", i, " is ", int(rand()*100) ; i++} }'- הלולאה מדפיסה ערכים רנדומליים באמצעות הפונקציה rand() של Awk
- הערכים הרנדומליים הם שברים עשרוניים בין 0 ל-1. הכפלה ב-100 והפיכה למספר שלם באמצעות הפונקציה int() מאפשרים לקבל מספרים בטווח שבין 0 ל-100.
התוצאה אצלי:
random # 1 is 38
random # 2 is 56
random # 3 is 34
random # 4 is 72
random # 5 is 83
random # 6 is 46
random # 7 is 59
random # 8 is 21
random # 9 is 37
random # 10 is 54
יש עוד הרבה מה ללמוד ולעשות. ממליץ מאוד להריץ את הפקודה man, ולקרוא את התיעוד הרשמי:
$ man awk
מדריכים נוספים בנושא לינוקס
סקריפט ראשון בשפת bash - שלום עולם כמובן!
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.