
מבוא לעיבוד שפה באמצעות Gensim ו-Word2Vec
Gensim היא חבילה של פייתון לעיבוד שפות אנושיות (NLP, Natural Language processing) באמצעות למידת מכונה. במדריך הזה הסבר והדגמה פשוטה של היכולת של מודול של Gensim ששמו word2vec להפוך מילים לוקטורים (וקטוריזציה) לצורך למידת מכונה, למה צריך את זה בכלל, ומדוע (בינתיים) לא כדאי לבקש מהמחשב להכין לנו קפה?

בעיה מרכזית שהמחשב צריך לפתור כדי לבצע למידת מכונה על טקסט היא שהתהליך דורש ביצוע פעולות חשבוניות על וקטורים. לכן, אחד הדברים הראשונים שנעשה, כהכנה ללימוד שפה, הוא להמיר את המילים מהם מורכב הטקסט לוקטורים שמתארים מילים (וקטוריזציה). התוצאה של התהליך היא word embedding רשימה שממפה מילים לוקטורים.
Word embeddings היא רשימה שממפה מילים לוקטורים.
Word2Vec הם אלגוריתמים שמייצרים Word embeddings
Word2Vec הם אלגוריתמים שמייצרים Word embeddings.
הוקטורים ש- Word2Vec מייצר מאפשרים למחשב לזהות מילים שמשמעותם דומה. לדוגמה, למצוא את המילים הדומות ל"תפוח" בתוך טקסטים. לבני האדם קל לעשות את הקשר ולהבין שהמילים "אגס", "פרי" ו"מתוק" קשורים לתפוח אבל למחשב המשימה אינה פשוטה והיא מצריכה אימון על מסד נתונים ענק שהעיבוד שלהם דורש משאבי מחשוב גדולים.
אחת הדרכים הפשוטות להפוך מילים לוקטורים הוא על סמך ההקשר שבו הם נמצאות מתוך הנחה שמילים המופיעות בסמיכות הם דומות יותר. לדוגמה, ניתן לספור את השכיחות של מילים שונות בספר כלכלה ובספר מתמטיקה, ולקבל רשימה כזו:
|
מילה |
ספר כלכלה |
ספר מתמטיקה |
|---|---|---|
|
וקטור |
80 |
120 |
|
תפוקה |
120 |
12 |
|
אמצעי ייצור |
50 |
0 |
|
פיתגורס |
1 |
78 |
|
נעלם |
2 |
250 |
|
משוואה |
70 |
90 |
כל שורה בטבלה מקבילה לוקטור שמתאר מילה אחת ייחודית.
מזה גם אנחנו יכולים לראות שהמילים "נעלם" ו"פיתגורס" קרובים יותר כי הם מרבים להופיע בספר המתמטיקה ואינם שכיחים בספר הכלכלה.
word2vec הופך מילים לווקטורים באמצעות מודל מבוסס למידת מכונה.
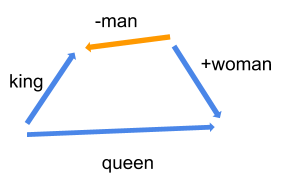
באופן דומה, word2vec עושה וקטורים ממילים אבל באמצעות מודל למידת מכונה. הוקטורים הם מאוד ארוכים וכוללים מאות ואף אלפי עמודות כך שזה לא משהו שבני אדם יכולים לקרוא אבל המחשב יכול, ובזכות הווקטורים שמייצגים מילים המחשב יכול לדמות הבנה של שפה אנושית. דוגמה קלסית היא ביצוע פעולות מתמטיות על וקטורים של מילים שמראה ש "מלך" פחות "גבר" ועוד "אישה" שווה "מלכה".
שלושת האלגוריתמים העיקריים המשמשים ל-word embedding הם : Word2Vec, GLoVe, FastText. במדריך זה נפתח מודל מבוסס אלגוריתם Word2Vec באמצעות ספריית Gensim.
1. ייבוא הספריות שישמשו במדריך
הקוד במדריך פותח על גבי פלטפורמת colab של גוגל.
from gensim.models.word2vec import Word2Vec
from multiprocessing import cpu_count
import gensim.downloader as api
2. ייבוא מסד הנתונים שעליו נאמן את המודל וטוקנזציה
# Download the dataset
dataset = api.load("text8")
# Tokenize
data = [d for d in dataset]- מסד הנתונים text8 כולל את מיליארד הבייטים הראשונים של וויקיפדיה באנגלית.
- מיד אחרי שייבאנו את מסד הנתונים חילקנו אותו למערך של טוקנים (מילים בודדות) שעליהם נבצע את למידת המכונה בתהליך שנקרא טוקניזציה.
תמיד מעניין לסקור את מסד הנתונים לפני שמשתמשים בו.
len(data)1701
רק 1701 מילים במסד הנתונים. נראה לי מעט ביחס למסד נתונים של שמונה גיגה.
type(data[0])list
אז כל אחת מ-1701 הרשימות היא רשימה בפני עצמה.
מעניין מה אורכם של הרשימות.
print(len(data[0]))
print(len(data[1699]))
print(len(data[1700]))10000 10000 5207
1700*10000+5207=17,005,207
יותר מ-17 מיליון מילים.
מעניין איך הם מסודרות, איך הם כתובות.
print(data[0][0:20])
print(data[1700][0:20])['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english'] ['find', 'list', 'of', 'once', 'popular', 'beliefs', 'or', 'beliefs', 'which', 'are', 'today', 'more', 'or', 'less', 'widespread', 'which', 'are', 'proven', 'false', 'or']
אילו ערכים של וויקפדיה. מסודרים בסדר המילים המקורי. ללא סימני פיסוק וכל האותיות קטנות. כל מילה ברשימה נקראת אסימון (token).
3. נאמן את המודל
# Train Word2Vec model
model = Word2Vec(data, min_count = 0, workers=cpu_count())המודל מבוסס על אלגוריתם Word2Vec.
4. הערכת המודל על דוגמאות שלנו
מעניין עד כמה המודל שאימנו מצליח להבין שפה אנושית. אבל קודם מעניין לראות את הוקטור שפיתח המודל עבור מילה מסוימת שבחרתי באקראי:
# What is the vector for a specific word
model['computer']array([-0.4556992 , -1.3862419 , -1.8048558 , -0.99020433, -1.8391104 ,
-1.2232118 , 1.6570348 , -0.5733954 , 1.301653 , 0.7046181 ,
3.5673776 , 1.4294931 , 1.7671193 , 2.9676414 , -1.0262669 ,
-0.5415519 , 1.5530779 , -0.31864733, 2.1040018 , 2.4623108 ,
0.1254964 , 0.14440827, -1.022954 , -0.49929366, 1.2939268 ,
0.48723364, -0.08392578, -0.4165755 , 1.6926756 , -0.8817703 ,
-2.5548038 , -1.6914276 , 2.784908 , 3.1269388 , -2.4126492 ,
-0.3693157 , 1.984339 , 0.61644703, -4.5196004 , -1.9094042 ,
0.6563388 , 0.21732877, -0.47493523, -0.33547932, -0.9218038 ,
1.8590525 , 1.9552816 , 2.9326048 , -2.5484583 , -0.9174693 ,
-0.9689221 , 3.6791236 , -0.76825094, 0.39009356, 0.14539249,
0.09960414, 0.24469626, -0.29692438, 0.31805772, -0.15215315,
0.46852365, -0.9507698 , -1.0477052 , 2.5365412 , -0.53734595,
-0.06571991, -0.7088819 , 0.01710024, 1.8660653 , 1.0688304 ,
1.1716064 , 0.26592818, -2.1123452 , -1.5442512 , 2.626128 ,
1.8971505 , 0.7942581 , 0.10705332, -2.5659127 , -0.62169796,
-3.7376935 , -2.4376974 , 1.5072051 , 0.25494763, 4.2154155 ,
1.2217032 , -0.02796807, -2.158551 , -2.5484815 , -1.5887915 ,
-0.6711285 , 0.22806092, -1.4221463 , 2.538666 , 0.8001251 ,
-1.3699907 , -0.85555667, 2.5453928 , -1.7741997 , 2.1562831 ],
dtype=float32)
מה זה? הוקטור שמייצג עבור word2vec את המשמעות הסמנטית של המילה כי המיקום של המילה ביחס לשאר המילים במרחב של 100 ממדים מאפשר להסיק את משמעותה על סמך מידת קרבתה למילים אחרות.
len(model['computer'])100
הפיכת המילים לוקטורים מאפשרת ל-word2vec לחשב את מידת הדמיון הסמנטי בין המילים. לדוגמה, נמצא מילים דומות ל-computer:
model.most_similar('computer')[('computers', 0.7448275089263916),
('programmer', 0.7379027605056763),
('computing', 0.7248053550720215),
('digital', 0.6966275572776794),
('hardware', 0.6950956583023071),
('console', 0.68471360206604),
('calculator', 0.680589497089386),
('simulation', 0.6802507638931274),
('software', 0.6783767938613892),
('graphics', 0.6690623760223389)]
לא רע בכלל.
ננסה לבדוק את המודל על מילה שבטוח שאין בוויקיפדיה באנגלית:
model.most_similar('לא שייך')והתוצאה היא הודעת שגיאה:
KeyError: "word 'לא שייך' not in vocabulary"
מהסיבה שהאלגוריתם אומן על מילון שלא כולל את הביטוי המבוקש, ולכן הוא לא קיים ביקום שלו.
אפשר ללכת הפוך ולברר את מידת הדמיון בין שתי מילים:
model.similarity('computer', 'digital')0.6966277
האם מידת הדמיון היא רבה או מועטה?
model.similarity('computer', 'stone')-0.020096581
זה גם מאפשר לנו לענות על שאלת השאלות ממנה התחלנו את המדריך. האם המודל ידע להבחין בין קפה לתה?
model.similarity('coffee', 'tea')0.8239475
אולי בכל זאת נוכל לסמוך על המחשב שידע להבדיל בין קפה לתה.
אפשר לבטא יחסים יותר מורכבים דוגמת: "מלך" פחות "גבר" ועוד "אישה" שווה "מלכה".
model.most_similar(positive=['woman','king'], negative=['man'])[('queen', 0.6735000014305115),
('empress', 0.6230182647705078),
('son', 0.6148408651351929),
('prince', 0.6136608123779297),
('scots', 0.6015072464942932),
('throne', 0.6004026532173157),
('princess', 0.5982245802879333),
('elizabeth', 0.5977342128753662),
('emperor', 0.5941356420516968),
('mary', 0.5928153395652771)]
ניתן למצוא את המילה יוצאת הדופן מתוך רשימה של מילים:
model.doesnt_match("train auto car vehicle software".split())'software'
סיכום
word2vec הוא אלגוריתם שמשמש במשימות של עיבוד שפה טבעית כדי ללמוד את המשמעות הסמנטית של מילים דרך הפיכת מילים לוקטורים של מספרים שאיתם המחשב יכול לעבוד (Embedding). חסרון גדול של השיטה שהיא מנפיקה וקטור אחד לכל מילה, והוקטור הזה אמור לתפוס את המשמעויות השונות של המילה ללא תלות בתפקיד שהיא ממלאת במשפט. זה יכול להיות בעייתי כי משפט כמו "אישה נעלה נעלה נעלה נעלה את הדלת בפני בעלה" יראה כמו ג'יבריש למודל. מודלים חדישים יותר כדוגמת ELMO ו-BERT מצליחים לייצר וקטורים שונים לאותה מילה בהתאם לתפקיד שהמילה ממלאת במשפט, ולכן הם מצליחים יותר במשימות של עיבוד שפה.
אולי גם זה יעניין אותך?
למידת מכונה - סיווג טקסטים באמצעות sklearn
פיתוח מודל לאנליזת סנטימנט באמצעות למידת מכונה ו-
שימוש ב-word embedding שאומן מראש במודל Keras לסיווג טקסטים
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.