
גירוד דפי רשת (Web scraping) באמצעות פייתון
גירוד דפי רשת היא טכנולוגיה שמאפשרת לנו להעתיק את תוכנם של דפי אינטרנט ומקורות מידע ברשת למאגרי הנתונים שברשותנו. במדריך זה נלמד לגרד דפי רשת באמצעות ספריית BeautifulSoup של פייתון וכיצד לאחסן את המידע שהורדנו במסד הנתונים ועל קבצי csv במחשב/ בשרת שלנו.

אזהרה חשובה לפני שאנחנו מתחילים! גירוד דפי רשת נחשב לעיסוק שנוי במחלוקת שעלול לגרום לבעיות משפטיות ואחרות. לכן, לפני שאתם משתמשים בטכנולוגיה הקפידו לברר עם האתר שהוא אכן מרשה את גירוד הדפים, ודאגו לווסת את קצב הגירוד כדי לא להשבית את האתר שאתם מגרדים.
מהטעם שגירוד דפי רשת אינו בהכרח חוקי, נלמד לגרד דף שהקמתי על השרת במחשב האישי. אתם מוזמנים להוריד את קוד ה-HTML של הדף, כמו גם את כל הקוד שנפתח במדריך מכאן. השתמשו בדף ה-HTML כדי לתרגל את הנלמד במדריך.
* המדריך מסביר תהליך מורכב למדי ולכן כדאי להוריד את הקוד המלא כך שאם תלכו לאיבוד יהיה לכם תמיד לאן לחזור כדי לראות כיצד הדברים מתחברים.
כך נראה דף האינטרנט אותו נגרד במדריך:
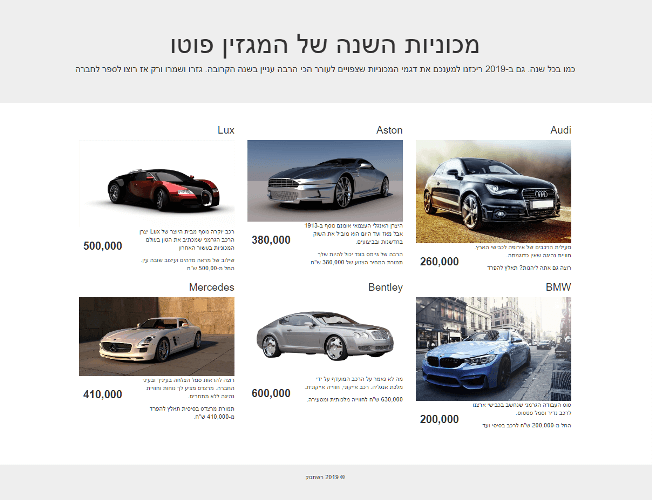
הדף כולל שש תיבות שכל אחת מכילה עבור דגם אחד של מכונית הכולל את שם הדגם, תמונה, תוכן ומחיר.
סקירת מבנה הדף
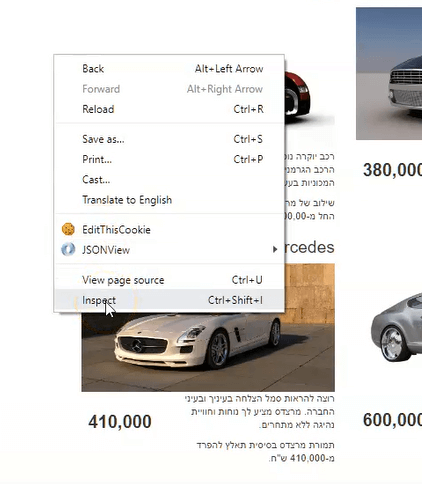
לפני שאפשר לגרד את תוכנו של דף, צריך להבין את מבנה ה-HTML. זה חשוב מפני שאנו רוצים למצות מתוך שפע המידע שנמצא באתר רק את המידע הרלוונטי לצרכינו. גלשו לאתר מדפדפן כרום, הקליקו על הלחצן הימני בעכבר ומהתפריט שיפתח לחצו על Inspect. בקונסולה שתפתח תראו את האלמנטים מהם מורכב הדף.
בלשונית Elements של הקונסולה אפשר לראות שהתיבות יושבות בתוך קישורים (תגית HTML מסוג a). נלחץ על אחד החיצים כדי לראות את תוכנו של הקישור. בתוך הקישור ישנם חיצים נוספים. לחיצה על כל אחד מהחיצים הפנימיים תחשוף את המבנה המלא של האלמנט.
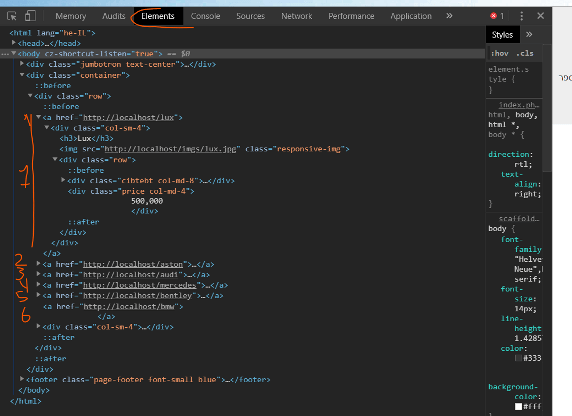
כל קישור כולל: כותרת h3, תמונה, div של תוכן הכולל 2 פסקאות טקסט ומחיר.
מבנה התיקיות
תיקיית הפרויקט צריכה לכלול שני קבצי פייתון ותיקייה אחת. שני הקבצים הם:
- main.py – שבו נכתוב את רוב הקוד
- db.py – שיאפשר לנו לתקשר עם מסד הנתונים
בנוסף, תכיל תיקיית הפרויקט תיקייה ששמה csvs שתכיל את קבצי ה-csv שיאחסנו את המידע שאותו נגרד.
גירוד הדף באמצעות BeautifulSoup
כל מה שאנחנו עומדים לבצע מתאפשר הודות לשתי ספריות של פייתון. נוסיף את הקוד הבא לקובץ main.py
import urllib.request
from bs4 import BeautifulSoup- urllib.request – מאפשר לעבוד עם כל מה שניתן להגיע אליו באמצעות כתובות אינטרנט (דפי אינטרנט ו-json).
- BeautifulSoup – מאפשר את גירוד הדפים בפועל.
את החבילות ניתן להתקין באמצעות pip משורת הפקודות או הטרמינל:
$ pip install beautifulsoup4
$ pip3 install urllib3נגדיר את ה-url שאותו אנחנו מעוניינים לגרד, וניגש לכתובת האינטרנט באמצעות urllib:
url = 'https://localhost/index.html'
source = urllib.request.urlopen(url)את המידע המוחזר צריך להעביר לטיפולה של ספריית BeautifulSoup כדי שתפרק את המידע לאלמנטים שאנחנו יכולים לגשת אליהם באמצעות פקודות פשוטות:
soup = BeautifulSoup(source,'html.parser')ועכשיו, אנחנו יכולים לגשת לאלמנטים בקלות. לדוגמה, הפקודה הבאה ממצה מהדף את כל הנתיבים לתמונות:
tags = soup.find_all('img')
for tag in tags:
print(tag.get('src'))פקודה אחרת יכולה לשלוף את כל הטקסטים הנמצאים בפסקאות בין התגיות p:
tags = soup.find_all('p')
for tag in tags:
print(tag.getText())אם רוצים גישה לכל הקישורים שהקלאס שלהם הוא field-item:
links = self.soup.find_all('a',{'class': 'field-item'})הספרייה BeautifulSoup כוללת עוד הרבה מתודות מועילות עליהם תוכלו לקרוא בתיעוד הרשמי.
ייבוא ספריות נוספות לקובץ main.py
הקלאס שלנו מיועד לגרד את הדף ולמצות את התוכן שלו לתוך קובץ csv כמו גם למסד הנתונים.
נייבא 3 ספריות נוספות שישמשו אותנו לתוך הקובץ main.py:
# utf8 support
import codecs
# regular expressions
import re
# time dependent functions
import time- codecs – יאפשר לנו לעבוד עם שפות אקזוטיות דוגמת עברית.
- re – יאפשר לנו להשתמש בביטויים רגולריים, לצורך ניקוי התוכן.
- time – בשביל פונקציות התלויות בזמן.
בסוף השלב הזה, כך צריך להראות קובץ main.py
import urllib.request
from bs4 import BeautifulSoup
# utf8 support
import codecs
# regular expressions
import re
import time
מסד הנתונים והטבלת cars
מסד הנתונים שאני עובד אתו הוא מסוג mysql , והקמתי אותו על השרת האישי שלי. למסד הנתונים קראתי test, והוא כולל את הטבלה cars שלתוכה נזין את המידע שנמצה מהדף.
זה הקוד שבאמצעותו יצרתי את הטבלה במסד הנתונים:
--
-- Table structure for table `cars`
--
CREATE TABLE `cars` (
`id` int(10) NOT NULL,
`name` varchar(100) DEFAULT '',
`img` varchar(120) NOT NULL DEFAULT '',
`content` text CHARACTER SET utf8mb4 NOT NULL,
`price` int(8) NOT NULL,
`created_at` datetime DEFAULT CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Indexes for table `cars`
--
ALTER TABLE `cars`
ADD PRIMARY KEY (`id`);
--
-- AUTO_INCREMENT for table `cars`
--
ALTER TABLE `cars`
MODIFY `id` int(10) NOT NULL AUTO_INCREMENT;הטבלה כוללת עמודות שמכילות את דגם המכונית, תמונה, תוכן, מחיר וזמן הזנת התוכן לראשונה.
קלאס Db להתקשרות עם מסד הנתונים
הקלאס Db מאפשר לעשות שני דברים בלבד. לייצר קשר עם מסד הנתונים באמצעות המתודה connect, ולהתנתק באמצעות disconnect.
העתיקו והדביקו את הקוד הבא בתוך הקובץ db.py אשר בתיקיית הפרויקט:
import pymysql.cursors
import pymysql.err
class Db:
connection = None
def __init__(self,host,user,password,db):
try:
self.connection = pymysql.connect(host=host,user=user,password=password,db=db,charset='utf8mb4',cursorclass=pymysql.cursors.DictCursor,autocommit=True)
except pymysql.err.InternalError as e:
print(e)
def connect(self):
return self.connection
def disconnect(self):
self.connection.close()
הקלאס WebScraper וגירוד הדף
נחזור לקובץ main.py, ונייבא את הקלאס Db בהמשך לספריות שכבר ייבאנו:
from db import Dbנפתח את הקלאס WebScraper שיכיל את המתודות שלנו לגירוד הדף:
class WebScraper:
def __init__(self, db, url):
self.url = url
self.db = db
self.source = urllib.request.urlopen(self.url)
self.soup = BeautifulSoup(self.source,'html.parser')
self.cars = []- מיד בהקמה של האובייקט מהקלאס נעביר לו את המידע על מסד הנתונים db ועל ה-url שצריך לגרד.
- BeautifulSoup יפרסס את המידע המגורד מה-url.
- המשתנה cars יכיל את רשימת המידע על המכוניות אותו מיד נגרד מהדף.
המתודה scrapeCars מפרקת את המידע אותו גרדנו מהדף לאלמנטים שאנחנו יכולים לאחסן במסד הנתונים.
def scrapeCars(self):
cars = []
links = self.soup.find_all('a',{'class': 'field-item a-container'})
for link in links:
# get the headline from the text of the h3 tags
headline = link.find('h3').text
# get the img sources
img = link.find('img').get('src')
# get the content by extracting the text
# and cleaning the new lines
# with the help of regex
content = link.find('div',{'class':'cibtebt'}).get_text()
content = re.sub(r'[\s\,]+', ' ', content)
# extract the digits from the price with regex
price = link.find(class_='price').get_text()
price = re.sub('[^0-9]', '', price)
# collect into the list of cars
cars.append([headline, img, content, price])
self.cars = cars
return self- נמצא את כל הקישורים בדף השייכים לקלאס field-item a-container
- נעבור על הקישורים באמצעות לולאה, ומכל קישור נמצה את הכותרת, התוכן והתמונה. לשם כך נעזר בביטויים רגולריים.
- את המידע שמיצינו נוסיף לרשימת cars.
- הפונקציה מחזירה self כדי שנוכל לשרשר אותה.
הפונקציה saveToFile לוקחת את הרשימה cars, ומאחסנת בקובץ csv.
def saveToFile(self):
filename = './csvs/data_{}.csv'.format(time.strftime("%Y%m%d-%H%M%S"))
try:
f = codecs.open(filename, 'w', 'utf-8')
headers = 'name, img, content, price'
f.write(headers)
# Inside a loop
for car in self.cars:
f.write('\n')
f.write(', '.join(car))
f.close()
except:
print('Cannot write into the folder')
return self- שם הקובץ כולל את התאריך בו הוא נוצר.
- בגלל שאנחנו עובדים עם עברית נקפיד לעבוד עם קידוד utf-8
- נעבור על רשימת המכוניות בתוך לולאה ונהפוך כל פריט ברשימה לשורה בקובץ ה-csv.
הפונקציה saveToDb מזינה את המידע מרשימת המכוניות למסד הנתונים:
def saveToDb(self):
con = self.db.connect()
if con is not None:
for car in self.cars:
cur = con.cursor()
now = time.strftime("%Y-%m-%d-%H:%M:%S")
sql = "INSERT INTO cars VALUES (NULL, %s, %s, %s, %s, %s)"
cur.execute(sql, (car[0],car[1],car[2],car[3],now))
db.disconnect()
הרצת הקוד שפתחנו
בתוך הקובץ main.py אבל מתחת לקלאס, נגדיר את ה-url ואת פרטי הגישה למסד הנתונים:
url = 'https://localhost/index.html'
db = Db(host='localhost',user='root',password='',db='test')נריץ את הקוד לעיל באמצעות השורה הבאה:
WebScraper(db, url).scrapeCars().saveToFile().saveToDb()הקוד יוצר את האובייקט שמגרד את הדף ומיד קורא למתודות אשר שומרות את המידע לקובץ csv ולמסד הנתונים.
לכל המדריכים בסדרה ללימוד פייתון
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.