

סיווג תמונות באמצעות למידת מכונה מבוססת PyTorch
במדריך זה נפתח מודל בינה מלאכותית המבוסס על רשת נוירונית שילמד את עצמו כיצד לסווג תמונות לקטגוריות. בינה פירושה שמתכנתים לא צריכים לקודד את כל המצבים האפשריים לתוכנה, ובמקום זאת ניתן לכתוב תוכנית שתגרום למחשב להבין בעצמו. רשת נוירונית היא ארכיטקטורה ממוחשבת המחקה את אופן הפעולה של המוח. הטכנולוגיות והטכניקות המשמשות לעבודה עם בינה מלאכותית נקראות למידת מכונה machine learning. כאשר הרשת הנוירונית מורכבת ממספר שכבות זו למידה עמוקה deep learning.
המודל
המודל מייצר רשת מסוג CNN, Convolutional Neural Network, המשמשת בעיקר לזיהוי של תמונות בגלל שהיא מתחשבת בממד הרוחב והגובה של הפריטים המרכיבים תמונה. הרשת שבה נהוג להשתמש לצורך קונבולוציה מתאפיינת במבנה מתכנס, שמאפשר לשכבות הראשונות לראות פרטים (דוגמת, עיגול או קו אופקי או אנכי) ולהרכיב תמונה כוללנית יותר בשכבות המאוחרות יותר (דוגמת, עין או פנים של אדם). הודות למבנה המתכנס השכבה האחרונה של הרשת "רואה" את התמונה הכללית, ומסיקה מה בתמונה.
המודל שאותו נפתח במדריך מבוסס על PyTorch, ספריית קוד פתוח של למידת מכונה, השימושית במיוחד לאפליקציות של ראייה ממוחשבת ועיבוד שפה טבעית.
להורדת הקוד אותו נפתח במדריך ואת התמונות מהם המודל ילמד
יבוא התלויות וקונפיגורציה
את הקוד פתחתי בסביבת colab של גוגל הזמינה לכולם ובחינם. נא להקפיד להגדיר את המשתנה Hardware accelerator שיהיה על GPU כשעובדים על אפליקציות CNN.
נייבא מספר ספריות בסיסיות:
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
from PIL import Image- Numpy משמשת לביצוע חישובים מהירים על מערכים וטנסורים.
- PyTorch היא ספרייה של למידת מכונה בה נשתמש ליצירת המודל.
- המודול torchvision מכיל כלים לעבודה עם תמונות בלמידה עמוקה.
- הספרייה Pillow משמשת לעבודה עם תמונות בפייתון.
נוודא שאנחנו עובדים על GPU עליו מותקן cuda:
# device configuration
print(torch.cuda.is_available())
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = torch.device("cuda:0")
print(device)התוצאה הרצויה:
True cuda:0
במשתנה device נשתמש בהמשך כדי לטעון את המודל והטנסורים על אותה מערכת.
מסד הנתונים
את התמונות במדריך קצרתי מאתר pixabay.com, והם שייכות ל-3 קטגוריות: צפרדעים, מכוניות ולטאות. בסט האימון 10 תמונות מכל קטגוריה, בסט הבקרה (ולידציה) 10 מכל קטגוריה, ובסט המבחן 5. כמות התמונות היא מאוד קטנה בשביל למידת מכונה מאפס ובכל זאת ננסה כי העיקר במדריך הוא עצם הלמידה. התמונות שקצרתי היו צבעוניות ברובם, בעלות גודל שונה, ופורמטים שונים (jpg, png, webp). את כל התמונות המרתי לפורמט png בגודל 100X100 פיקסלים בתהליך אותו תיארתי במדריך שימוש באוגמנטציה לצורך למידת מכונה, מתוכו השתמשתי בטנספורמר Resize לשינוי הגודל.
את התמונות העליתי ל-Google Drive, עם מבנה התיקיות הדרוש לבנייה אוטומטית של מסד הנתונים על ידי הקלאסtorchvision.datasets.ImageFolder:
└── car_frog_lizard
├── test
│ ├── car
│ ├── frog
│ └── lizard
├── train
│ ├── car
│ ├── frog
│ └── lizard
└── val
├── car
├── frog
└── lizard
להורדת הקוד אותו נפתח במדריך ואת התמונות מהם המודל ילמד
- תיקיית ה-root היא car_frog_lizard
- תיקיות המשנה הם 3 מסדי הנתונים כמקובל בלמידת מכונה: train, test, val כאשר סט ה- val ישמש להערכת המודל בזמן האימון, והסט test הוא holdout שנשתמש בו רק אחרי סיום תהליך האימון להערכת ביצועי המודל על תמונות אליהם הוא לא נחשף במהלך האימון.
- כל סט כולל 3 תיקיות שכל אחת מהם מחזיקה קלאס אחד שאליו אנו רוצים לסווג: car, frog, lizard.
נגדיר את התיקיות והקלאסים:
import os
IMG_DIR = '/content/google_drive/MyDrive/projects/cnn/car_frog_lizard/'
TRAIN_DIR = os.path.join(IMG_DIR, 'train')
VAL_DIR = os.path.join(IMG_DIR, 'val')
TEST_DIR = os.path.join(IMG_DIR, 'test')
CLASSES = ["car", "frog", "lizard"]נאסוף את נתיבי התמונות לרשימות כדי שנוכל להציג את התמונות וכך לוודא את הנתונים איתם נעבוד:
# loop over all the files and store img paths in 3 lists:
# training, validation and testing
img_list_train = []
img_list_val = []
img_list_test = []
for subdir, dirs, files in tqdm(os.walk(IMG_DIR)):
last_dir = subdir.split("/")[-1]
if last_dir in CLASSES:
cls = last_dir
op = subdir.split("/")[-2]
print(op+"/"+cls)
for file in files:
file_path = os.path.join(subdir, file)
# read PIL image
img = Image.open(file_path)
list = [cls, file_path, img]
if op == "train":
img_list_train.append(list)
elif op == "val":
img_list_val.append(list)
else:
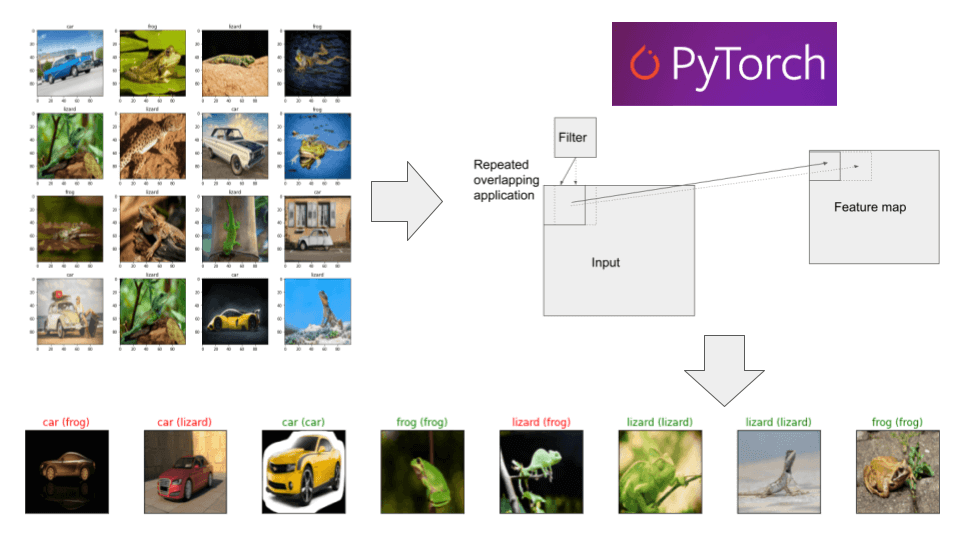
img_list_test.append(list)נציג 16 תמונות אקראיות מתוך סט האימון:
import random
def plot_imgs(imgs, nrows, ncols):
figsize = (12,12)
number_of_images = len(imgs)
figure = plt.figure(figsize=figsize)
for i in range(nrows*ncols):
ax = figure.add_subplot(nrows, ncols, i+1)
idx = random.randint(0, (number_of_images-1))
#print(imgs[25][1])
# show the image with the class
ax.set_title(imgs[idx][0])
img = Image.open(imgs[idx][1])
print(img)
ax.imshow(img)
plt.tight_layout()# randomly select 16 images and display them on a grid
plot_imgs(img_list_train, 4, 4)

- התמונות הם בצבע כך שיש להם 3 ערוצי צבע RGB - Red Green Blue
- התמונות הם בגודל אחיד של 100X100 פיקסלים בהתאם לדרישות הרשת הנוירונית לקלטים בעלי צורה זהה.
הכנת הנתונים ללמידת מכונה
הפונקציה torchvision.datasets.ImageFolder טוענת את הנתונים מתוך קבצי התמונות והופכת לטנסורים שרק איתם PyTorch יודע לעבוד. במהלך הטעינה התמונות עוברות טרנספורמציות שונות שמקלות ומאפשרות את העבודה איתם.
טנספורמרים הם פונקציות שניתן להפעיל על תמונות שזמינות לנו מהמודול torchvision.transforms. נשתמש בפונקציה Compose ליצירת pipeline - כאשר מסדרים פעולות ברשימה בסדר מסוים כשאח"כ אפשר לחזור ולהשתמש באותו pipeline בלי צורך לכתוב אותו מחדש בכל פעם.
במקרה שלנו, ה-pipeline קודם יתאים את ממדי התמונות ל-100X100 פיקסלים ורק בסוף ימיר לטנסורים. בתהליך יווצרו 3 סטים של נתונים בהתאם לחלוקה המקבלת בלמידת מכונה: אימון, וידוא ומבחן.
import torchvision.transforms as transforms
# to create a dataset based on a PyTorch class
# load the datasets with "torchvision.datasets"
# module which provides utility classes for building your own datasets
# here we use the "ImageFolder"
# to load the images from folders
IMG_SIZE = 100
transformations = [
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor()
]
train_dataset = torchvision.datasets.ImageFolder(
root = TRAIN_DIR,
# data transformation pipeline
# including: resizing and converting from image to tensor
transform = transforms.Compose(transformations)
)
val_dataset = torchvision.datasets.ImageFolder(
root = VAL_DIR,
transform = transforms.Compose(transformations)
)
test_dataset = torchvision.datasets.ImageFolder(
root = TEST_DIR,
transform = transforms.Compose(transformations)
)מה במסד הנתונים train_dataset?
Dataset ImageFolder
Number of datapoints: 30
Root location: /content/google_drive/MyDrive/projects/cnn/car_frog_lizard/train
StandardTransform
Transform: Compose(
Resize(size=(100, 100), interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
)
התמונות יווצרו בפועל רק בתנאי שנחלץ אותם מתוך האיטרטור train_dataset.
נמצה את אחד הפריטים במסד הנתונים:
# let's see a single sample (e.g. #3)
print('tensor: ', train_dataset[3][0])
print('label: ', train_dataset[3][1])tensor: tensor([[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]],
[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]],
[[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
...,
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.],
[0., 0., 0., ..., 0., 0., 0.]]])
label: 0
- כל פריט מכיל טנסור ותגית label מספר שהפונקציה יוצרת באופן אוטומטי.
מה צורת הטנסור?
# what's the tensor shape
print(train_dataset[3][0].size())torch.Size([3, 100, 100]) # ([channels, height, width])
כדי לראות את שמם של ה-labels נשתמש ב-attribute classes:
# list the labels' names
train_dataset.classes['car', 'frog', 'lizard']
הפונקציה הבאה מחזירה את שם הקטגוריה על פי הערך המספרי שנעביר לה:
def get_class_from_index(dataset, idx):
# dictionary that maps class names to indexes
dict = dataset.class_to_idx
# replace dictionary keys with values
new_dict = {value:key for (key,value) in dict.items()}
if idx in new_dict:
return new_dict[idx]
return Noneלדוגמה:
print('label: ', train_dataset[3][1], get_class_from_index(train_dataset, train_dataset[3][1]))label: 0 car
טעינת הנתונים באמצעות DataLoader
שימוש בקלאס DataLoader של PyTorch מאפשר לנו לפצל את מסד הנתונים לאצוות mini-batches במקום לטעון את כל הנתונים בו זמנית ולהסתכן בכך שהמחשב יקרוס תחת העומס. בנוסף, הקלאס מאפשר לערבב shuffle את הנתונים או להכניס לקאש.
ניצור DataLoader נפרד עבור כל אחד משלוש מסדי הנתונים:
BATCH_SIZE = 8
# create train dataloader
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size = BATCH_SIZE,
shuffle = True
)
# create validation dataloader
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size = BATCH_SIZE,
shuffle = True
)
# create test dataloader
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size = BATCH_SIZE,
shuffle = True
)
המודל
תהליך הלמידה מורכב מ-3 שלבים:
-
בניית המודל כולל מבנה הקלט (input) והפלט (output), מספר השכבות ברשת הנוירונית, וכיו"ב.
-
בחירת פונקציות loss ואופטימיזציה optimizer.
-
אימון המודל נעשה במסגרת של epochs. בכל epoch מריצים את כל דוגמאות האימון, מחשבים את ההפרש loss בין הערכים בפועל לתחזיות המודל, ומעדכנים את המודל כדי לצמצם את ההפרש loss כמה שניתן.
המודל מורכב משני חלקים:
החלק הראשון feature extractor הכולל את שכבות הקונבולוציה ממצה את המידע מתוך התמונות.
החלק השני הוא classifier שתפקידו לסווג את התמונות לקטגוריות.
החלק הראשון, ה-feature extractor מורכב מבלוק אחד או יותר, כל בלוק עשוי משכבה אחת או שתיים של קונבולוציה שאחריה שכבת pooling:
Conv-Pool
או:
Conv-Conv-Pool
נוסף לשכבת קונבולוציה ו-pooling ניתן לשלב שכבות מנרמלות. דוגמת: dropout.
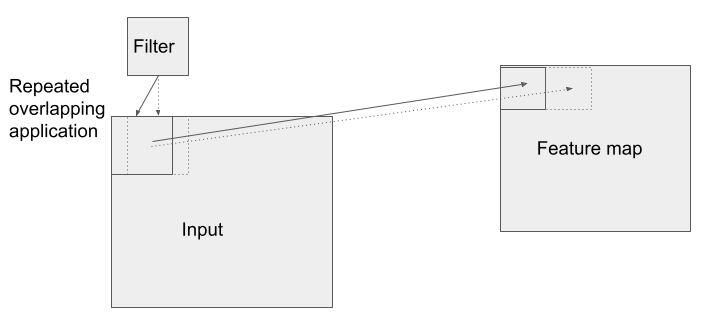
השכבה אשר נתנה למודל את שמו היא שכבת קונבולוציה convolution במסגרתה מריצים מספר פילטרים על כל אחת מהתמונות. לשכבה צריך להוסיף פונקצית אקטיבציה. במודל שלנו זה ReLU. כל פילטר עובר על התמונה בסדרת צעדים strides המזיזים אותו בכל פעם בפיקסל בודד (או יותר). התוצאה היא סדרה של ייצוגים חופפים של התמונה המכונים feature maps כאשר כל פילטר מנפק feature map יחיד. עבור משימות של למידה מתמונות נשתמש בפילטרים דו ממדיים Conv2d אשר מביאים בחשבון את 2 הממדים, הרוחב וגובה, של התמונות.
כל שכבת קונבולוציה כוללת מספר פילטרים (נקראים גם kernels) העובדים במקביל על המידע.
הפילטרים לא קולטים את כל התמונה בבת אחת כי הם קטנים מדי ועל כן הם מתקדמים בצעדים. בדרך כלל, זה צעד 1 בודד לאורך מימד הרוחב או הגובה של התמונה. הפילטר מתחיל לפעול מהפינה השמאלית העליונה של התמונה, ואח"כ נע בצעד 1 ימינה וגם במיקום החדש הוא פועל. כאשר הוא מסיים את השורה העליונה הוא יורד פיקסל אחד לשורה שמתחת שגם עליה הוא פועל משמאל לימין. הפעולה חוזרת על עצמה עד שהפילטר מגיע לפינה הימנית התחתונה של התמונה.
הפעולה שמבצע הפילטר נקראת קונבולוציה והיא כופלת dot product מטריקס דו-ממדי של משקולות (ערכים מספריים) של הפילטר בערכי המידע שמקורם בתמונה.
הפילטרים מזהים דפוסים patterns בתמונה. לדוגמה, קווים אנכיים או עיגולים קטנים. היישום של אותם פילטרים קטנים לאורכה ולרוחבה של התמונה מאפשר זיהוי של הדפוסים לא משנה היכן הם נמצאים כי לרשת זה לא משנה היכן הדפוסים נמצאים אילא עצם ההמצאות שלהם היא הקובעת.
הדפוסים שהפילטרים מזהים לא נקבעים מראש אילא נרכשים על ידי הרשת כחלק מתהליך הלמידה.
התוצר של מכפלת הפילטר במידע שמקורו בתמונה הוא מערך דו-מימדי המכונה feature map.
את ה-feature map מעבירים לפונקציית אקטיבציה לא לינארית, דוגמת ReLU.
לסיכום, שכבת הקונבולוציה קולטת מידע שמקורו בתמונה, היא עוברת על התמונה עם מספר פילטרים ומייצרת ייצוג של התמונה באמצעות feature map.
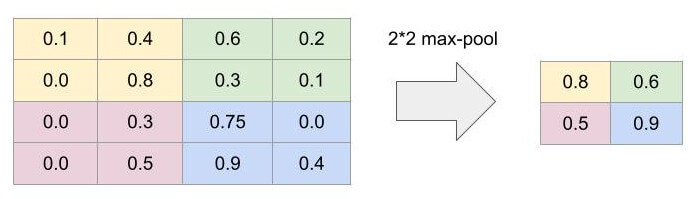
שכבה נוספת אותה מוסיפים אחרי שכבות הקונבולוציה היא שכבת דגימה pooling layer המצמצמת כל ריבוע שממדיו 2X2 פיקסלים אותם קיבלה מהקונבולוציה לריבוע בודד. שכבה זו היא פשוטה ביותר, ואינה כוללת פונקצית אקטיבציה. במודל שלנו נשתמש ב-max pooling אשר לוקח מכל ריבוע של 4 פיקסלים את הערך הגבוה ביותר ואותו הוא מעביר לשכבה הבאה. מטרת השכבה היא לצמצם את כמות הפרטים ועל ידי כך לאפשר למודל לראות יותר מהתמונה הכללית וגם להפחית את השימוש במשאבי מחשוב.
הדוגמה הבאה מדגימה הפיכה של דוגמה של 16 פיקסלים ל-4 באמצעות max pooling:
שכבת dropout היא שכבה מנרמלת אשר שומטת באקראי אחוז קטן מהמידע שמקורו בפילטרים. המטרה היא למנוע מהמערכת להיתפס לפרטים ועל ידי כך להגביר את היכולת להסיק דפוסים כלליים מספיק מסט האימון כדי להשתמש בהם אחר כך לסיווג דוגמאות שהמערכת לא נחשפה אליהם בזמן האימון.
החלק השני, ה-classifier מסווג את התמונות לקטגוריות באמצעות רשת נוירונית רגילה מסוג dense שבה כל נוירון בודד מחובר לכל אחד מהנוירונים בשכבה הבאה.
על מנת להעביר את המידע מהחלק הראשון של הרשת, המשתמש בפילטרים דו ממדיים של קונבולוציה, לחלק השני, המשתמש ברשתות נוירוניות רגילות, צריך לשטח את המידע לוקטור שגובהו פיקסל בודד באמצעות פונקצית flatten.
שכבת ה-classifier מורכבת ממספר שכבות dense שהאחרונה בהם כוללת את אותו מספר של נוירונים כמספר הקטגוריות. במקרה שלנו, 3 נוירונים.
כך נראה קוד המודל אשר משתמש בפונקציות של PyTorch:
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self):
# initialize super class
super(CNN, self).__init__()
# 1. feature extractor
self.cnn = nn.Sequential(
# first CNN block
nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, padding='same'),
nn.Dropout(p=0.1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3, padding='same'),
nn.Dropout(p=0.1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# second CNN block
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, padding=1),
nn.Dropout(p=0.1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
# third CNN block
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, padding=1),
nn.Dropout(p=0.1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
# 2. classifier
self.classifier = nn.Sequential(
nn.Linear(9216, 1000),
nn.Linear(1000, 96),
nn.Linear(96, 3)
)
def forward(self, x):
x = self.cnn(x)
# flatten all dimensions except batch
x = torch.flatten(x, 1)
x = self.classifier(x)
return xהחלק הראשון, ה-feature extractor מורכב משני בלוקים של קונבולוציה.
כל בלוק של קונבולוציה מורכב מ-2 שכבות קונבולוציה ושכבת max pooling 1. אחרי כל פילטר קונבולוציה הוספתי שכבה מנרמלת של droput השומטת 10% מהמידע באקראי.
הפילטרים של הקונבולוציה הם דו ממדיים nn.Conv2d כי בתמונות קיימים שני ממדים: אורך וגובה.
לשכבת הקונבולוציה קיים פרמטר kernel הם ממדי הפילטר. הממדים צריכים להיות אי-זוגיים, 3X3, 5X5 או 7X7 כדי שיהיה פיקסל מרכזי השומר את מיקום האקטיבציה. עבור תמונות קטנות מ-128X128, עדיף להשתמש במימדים קטנים של הפילטר ולכן השתמשתי ב-3X3.
הפרמטרים in_channels ו- out_channels קובעים את מספר הערוצים. כיוון שהתמונות הם צבעוניות מספר הערוצים ההתחלתי הוא 3 (כי דרושים שלושה ערוצי צבע: RGB - אדום, ירוק וכחול). ככל שהרשת מעמיקה מגדילים את מספר הערוצים כדי לקלוט יותר דפוסים.
ממדי הפילטר תלויים בפרמטרים:
- מספר הערוצים של הקלט in_channels
- מספר הערוצים של הפלט out_channels
- וממדי הפילטר kernel
כאשר הפילטר עובר על התמונה ייתכן ונשארים אזורים שהוא לא מכסה בקצוות. דבר הגורם לאובדן מידע ולהתכווצות התמונות ככל שהרשת מונה יותר שכבות קונבולוציה. כדי למנוע את הבעיה נהוג להשתמש ב- padding לריפוד הקצוות. לצורך כך כדאי להשתמש בפרמטר padding של פילטר הקונבולוציה. אפשר להעביר לפרמטר את מספר הפיקסלים (1, 2) ובמקרה זה השתמשתי בערך same כדי ש- PyTorch יעשה את החישוב בכמה פיקסלים לרפד כדי לא לאבד מידע.
הפרמטר stride אומר לפילטר כמה עליו לדלג בכל פעם. הערך ברירת המחדל הוא 1 שמשמעותו שהפילטר "צועד" בכל פעם פיקסל 1.
בשביל שכבות pooling משתמשים ב-kernels שגודלם 2X2 או 3X3. במקרה זה אני משתמש ב-2. גודל הצעד, הפרמטר stride אומר לשכבה כמה פיקסלים לנוע בכל פעם.
נאתחל את המודל על ה-GPU:
model = CNN()
model.to(device)
תהליך הלמידה
את ההיפר-פרמטרים של הלמידה מצאתי על ידי עריכת מספר ניסויים, והם דומים למה שראיתי בעבודות על רשתות קונבולוציה.
LEARNING_RATE = 1e-4
NUM_EPOCHS = 100- קצב למידה נמוך של 0.0001
- אין לי בעיה להגדיר מספר גבוה של epochs כיוון שתיכף נראה שאני משתמש בפונקצית early fitting כדי לעצור את המודל כשהוא מגיע לרוויה.
נגדיר את הפונקציות loss ו- optimizer.
import torch.optim as optim
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)- פונקצית loss מסוג Cross Entropy משמשת לבעיות של סיווג. במקרה שלנו, נרצה לסווג תמונות לאחת מ-3 קטגוריות: car, frog, lizard. הסתברות האמת עבור תמונה של מכונית היא [1, 0, 0] והסתברות הניבוי עבור התמונה שמפיקה הרשת הוא, לדוגמה, [0.6, 0.08, 0.32]. ככל שהתפלגות הסתברות האמת והניבוי קרובים יותר ערך ה- loss קטן יותר.
- Adam היא פונקציית אופטימיזציה אדפטיבית שמראה יתרונות על פני אלגוריתמים לא אדפטיביים, דוגמת SGD במגוון יישומים.
אימון המודל נעשה במסגרת של epochs. בכל epoch מריצים את כל דוגמאות האימון, מחשבים את ההפרש loss בין הערכים בפועל לתחזיות המודל, ומעדכנים את המודל כדי לצמצם את ההפרש loss כמה שניתן.
כל epoch מורכב מ-4 שלבים:
- Forward pass - המודל מקבל את הנתונים של מסד נתוני האימון training dataset, עורך חישובים ומנפק תוצאה שהינה תחזית משוערת. פונקציית loss נכנסת לפעולה ומחשבת את ההפרש בין ניבויי המודל ובין ערכי האמת. כיוון שהבעיה שמעניינת אותנו היא סיווג אנו משתמשים בפונקצית loss מסוג Cross Entropy.
- Backward pass - מחשב את הנגזרות החלקיות של ה-loss.
- עדכון המשקולות על סמך הגרדיאנטים במטרה לצמצם את ה- loss.
- חוזרים על שלושת הצעדים מספר פעמים מוגדר מראש או עד להתכנסות המודל - שלב שבו המודל למד מספיק מנתוני האימון אבל לא יותר מדי כדי שיוכל להכליל ממה שלמד על מידע שאליו לא נחשף במהלך האימון.
הגדרתי למודל מספר מקסימלי גבוה של epochs שהוא יכול לרוץ, בשאיפה שמה שיפסיק את התהליך היא פונקצית Early stopping שתעקוב אחרי הנתונים ותמנע לימוד יתר מנתוני האימון overfitting. הפונקציה עוקבת אחרי ערכי ה-loss של סט נתוני הוולידציה, ובמידה וערך זה אינו פוחת במהלך מספר epochs ברצף תהליך האימון מופסק אוטומטית. בשביל Early stopping של המודל אני משתמש בקלאס קיים שהורדתי מ-https://github.com/Bjarten/early-stopping-pytorch השומר עותק של המודל בכל פעם שערך ה-loss פוחת כך שניתן לטעון אח"כ את המודל המאומן ביחד עם המשקולות trained model with weights שהוא פיתח בתהליך כדי ליישם מחוץ למסגרת האימון. צריך להעביר לקלאס פרמטר patience המגדיר את מספר ה-epochs הרצוף שאחריו צריך להפסיק את תהליך הלמידה.
PATIENCE = 7בשלב זה, הגדרנו את כל מה שדרוש בשביל לאמן את המודל. הפונקציה הבאה מאמנת את המודל ב- mini-batches:
# train in mini-batches
def train_and_validate(num_epochs, train_loader, val_loader):
# track losses
# the training loss as the model trains
train_losses = []
# the validation loss as the model trains
valid_losses = []
# the average training loss per epoch as the model trains
avg_train_losses = []
# the average validation loss per epoch as the model trains
avg_valid_losses = []
# initialize the early_stopping object
early_stopping = EarlyStopping(patience=PATIENCE, verbose=True)
# loop over the dataset multiple times
for epoch in range(num_epochs):
# train
# one mini-batch at a time
# the actual training
# set model to "train" mode
# for layers/parts of the model that behave differently
# during training and valuation time.
# e.g., to turn on Dropouts Layers, BatchNorm Layers etc.
model.train()
for batch in train_loader:
# clear the gradients of all optimized variables
optimizer.zero_grad()
# extract each batch list [data, labels]
x_batch, y_batch = batch
#print(x_batch.shape)
#print(y_batch)
# send to the same device as the model
x_batch = x_batch.to(device) # data
y_batch = y_batch.to(device) # labels
# forward pass: make predictions by passing inputs to the model
yhat = model(x_batch)
# computes loss with softmax
loss = loss_fn(yhat, y_batch)
# backward pass: compute gradient of the loss with respect to model parameters
loss.backward()
# perform a single optimization step (parameter update)
optimizer.step()
# record training loss
train_losses.append(loss.item())
# once finished training
# it's time for evaluation
# for validation we must turn off gradient computation
# set model to validation mode
model.eval()
with torch.no_grad():
for batch_val in val_loader:
x_val, y_val = batch_val
# send to the same device as the model
x_val = x_val.to(device) # data
y_val = y_val.to(device) # labels
# forward pass: make predictions
yhat_val = model(x_val)
# find validation loss
loss_val = loss_fn(yhat_val, y_val)
# record validation loss
valid_losses.append(loss_val.item())
# track training/validation statistics
train_loss = np.average(train_losses)
valid_loss = np.average(valid_losses)
avg_train_losses.append(train_loss)
avg_valid_losses.append(valid_loss)
epoch_len = len(str(num_epochs))
print('epoch_len', epoch_len)
print_msg = (f'[{epoch:>{epoch_len}}/{num_epochs:>{epoch_len}}] ' +
f'train_loss: {train_loss:.4f} ' +
f'valid_loss: {valid_loss:.4f}')
print(print_msg)
# clear lists to track next epoch
train_losses = []
valid_losses = []
# early_stopping needs the validation loss to check if it has decreased,
# and if it has, it will make a checkpoint of the current model
early_stopping(valid_loss, model)
if early_stopping.early_stop:
print("Early stopping")
break
# load the last checkpoint with the best model
model.load_state_dict(torch.load('checkpoint.pt'))
return model, avg_train_losses, avg_valid_lossesנריץ את הפונקציה שמאמנת את המודל:
# train
model, train_loss, valid_loss = train_and_validate(NUM_EPOCHS, train_loader, val_loader)- משך האימון הוא לכל היותר 100 epochs או עד ל-early stopping.
- בכל epochs רצים שני תהליכים. אחרי שמסתיים התהליך הראשון, תהליך הלמידה, רץ תהליך ולידציה.
- בתהליך הלמידה חשוב להפעיל את המתודה model.train() כדי ששכבות המודל יעבדו בהתאם. לדוגמה, שכבות Dropout, batchNorm. מצד שני, בתהליך הולידציה נשתמש במתודה model.eval()
חשוב לעשות את תהליך הוולידציה באופן שלא ישפיע על חישוב הגרדיאנטים ולשם כך נשתמש ב:
.no_grad()- כיוון שהאימון הוא במבנה של mini-batches בתוך הלולאה הראשית רצות לולאות נוספות אשר שולפות את ה-batches מה- DataLoader.
הפונקציה לאימון המודל אספה את ערכי ה-loss עבור סט התמונות של האימון והוולידציה. עקומת הלמידה הבאה מתארת את הנתונים:
# visualize the loss as the network trained
fig = plt.figure(figsize=(10,8))
plt.plot(range(1,len(train_loss)+1),train_loss, label='Training Loss')
plt.plot(range(1,len(valid_loss)+1),valid_loss,label='Validation Loss')
# find position of lowest validation loss
minposs = valid_loss.index(min(valid_loss))+1
plt.axvline(minposs, linestyle='--', color='r',label='Early Stopping Checkpoint')
plt.xlabel('epochs')
plt.ylabel('loss')
plt.ylim(-0.2, 1.5) # consistent scale
plt.xlim(0, len(train_loss)+1) # consistent scale
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.show()
fig.savefig('loss_plot.png', bbox_inches='tight')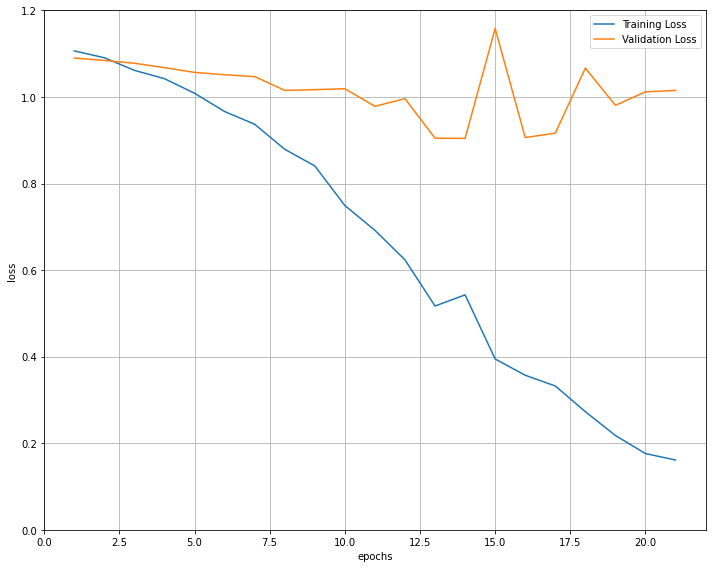
- עקומת הלמידה משווה את ה-loss של האימון לעומת הוולידציה.
- בעוד עקומת האימון יורדת ומראה שהמודל מצליח ללמוד ממסד נתוני האימון, עקומת הבקרה נשארת יציבה, מה שמראה שסט התמונות ששימשו לבקרה אינו דומה מספיק לסט האימון ועל כן המודל מתקשה להכליל ממה שלמד במסגרת האימון לתמונות הבקרה. את התוצאה אפשר להסביר בעובדה שסט התמונות הוא קטן מאוד (10 תמונות לאימון ולולידציה מכל קטגוריה) מה שמקשה על יכולת הלמידה של המודל.
- המודל ששמר קלאס ה- early stopping הוא של epoch מספר 13 שבו ה- validation loss היה 0.9, הנמוך ביותר בתהליך. בהמשך הערך לא ירד אבל הודות לשימוש בקלאס EarlyStopping יש לנו קובץ שמור של המודל המאומן שהשיג את התוצאות הטובות ביותר.
הערכת המודל
אחרי שסיימנו לאמן את המודל אנחנו יכולים להוציא ממנו הערכות על קטגוריות אליהם משתייכות תמונות אליהם הוא לא נחשף בתהליך האימון. לדוגמה, תמונות סט ה- holdout ששמרנו בצד.
נעריך את מידת הדיוק של המודל על תמונות סט ה- holdout:
# initialize lists to monitor test loss and accuracy
test_loss = 0.0
class_correct = [0. for i in range(10)]
class_total = [0. for i in range(10)]
model.eval() # prep model for evaluation
for batch_test in test_loader:
x_test, y_test = batch_test
if len(y_test.data) != BATCH_SIZE:
break
x_test = x_test.to(device) # data
y_test = y_test.to(device) # labels
# forward pass: compute predicted outputs by passing inputs to the model
yhat_test = model(x_test)
# calculate the loss
loss = loss_fn(yhat_test, y_test)
# update test loss
test_loss += loss.item()*x_test.size(0)
# convert output probabilities to predicted class
_, pred = torch.max(yhat_test, 1)
# compare predictions to true label
correct = np.squeeze(pred.eq(y_test.data.view_as(pred)))
# calculate test accuracy for each object class
for i in range(BATCH_SIZE):
label = y_test.data[i]
class_correct[label] += correct[i].item()
class_total[label] += 1
# calculate and print avg test loss
test_loss = test_loss/len(test_loader.dataset)
print('Test Loss: {:.6f}
'.format(test_loss))
for i in range(10):
if class_total[i] > 0:
print('Test Accuracy of %5s: %2d%% (%2d/%2d)' % (
str(i), 100 * class_correct[i] / class_total[i],
np.sum(class_correct[i]), np.sum(class_total[i])))
else:
#print('Test Accuracy of %5s: N/A (no training examples)' % (CLASSES[i]))
pass
print('
Test Accuracy (Overall): %2d%% (%2d/%2d)' % (
100. * np.sum(class_correct) / np.sum(class_total),
np.sum(class_correct), np.sum(class_total)))Test Loss: 0.443042 Test Accuracy of 0: 100% ( 2/ 2) Test Accuracy of 1: 66% ( 2/ 3) Test Accuracy of 2: 66% ( 2/ 3) Test Accuracy (Overall): 75% ( 6/ 8)
- מידת הדיוק הכללי היא 75%, בגלל שהמודל הצליח לשייך נכונה 6 מתוך 8 תמונות.
הקוד הבא מציג 8 תמונות מסט ה- holdout לצד הסיווגים שמצא המודל:

- התגיות הירוקות מציינות את המקרים בהם המודל הצליח בסיווג והאדומות את הזיהוי השגוי.
דיוק המודל עומד על 75% שהוא גבוה משמעותית מהסיכוי לסווג באקראי לאחת משלוש קטגוריות (33%) אבל אנחנו רוצים יותר.
איך לשפר את התוצאות?
בעיה עיקרית באימון רשתות נוירונים הוא מחסור בדוגמאות. במקרה שלנו השתמשנו במספר קטן של 10 תמונות בלבד מכל קטגוריה לאימון המודל. לא תמיד קל לאסוף תמונות נוספות הרבה יותר פשוט להגדיל את כמות התמונות באמצעות אוגמנטציה augmentation תהליך להגדלת כמות התמונות באמצעות הוספת עותקים שיש בהם שינויים קטנים מהמקור דוגמת: סיבוב התמונה, הטייה, משחק בצבעים ובבהירות. במדריך שימוש באוגמנטציה לפתרון הבעיה של מחסור בתמונות ללמידת מכונה תקבלו הסבר כיצד ניתן לייצר תמונות נוספות בעזרת PyTorch.
במידה ואוגמנטציה לא עוזרת צריך לשפר את המודל. תמיד אפשר לקבל השראה מארכיטקטורות CNN שפרסמו מדענים מובילים , דוגמת: AlexNet, VGG16, ResNet, Inception ואחרים שניתן לראות באתר paperswithcode.com. מודלים אילו עברו אימון על מסדי נתונים ענקיים, דוגמת: CIFAR 10 הכולל 60,000 תמונות או ImageNet המכיל 14,197,122 תמונות, וזכו בתחרויות יוקרתיות או שפורסמו בז'ורנלים מדעיים מובילים.
אפשר לקבל השראה אבל הרבה פעמים פשוט יותר לקחת מודלים מאומנים קיימים שפתחו מיטב המוחות בתחום ולהתאים אותם לצרכינו כי מסתבר שרשתות מוצלחות יכולות להכליל ממה שהם לומדות למשימות אחרות של סיווג. התחום שבו לוקחים מודל שאומן למטרות מסוימות ומשתמשים בו למטרות אחרות נקרא למידת העברה transfer learning הוא מפותח מאוד. לדוגמה, ניתן להוריד את המודלים ואת המשקלות שלהם מהאתר של PyTorch והשימוש בהם הוא קל ופשוט, כפי שנראה בסעיף הבא.
להורדת הקוד אותו פיתחנו במדריך ואת התמונות מהם המודל למד
שימוש במודל מאומן ResNeXt-50
את רשימת המודלים המאומנים ניתן לראות בתיעוד של PyTorch בדף MODELS AND PRE-TRAINED WEIGHTS . משם ניסיתי מספר מודלים ובחרתי להציג את התוצאות של המודל ResNeXt-50 שנתן את התוצאות הטובות ביותר.
ResNeXt-50-32x4d הוא מודל מאומן המונה 25 מיליון פרמטרים שאומן על מסד התמונות ImageNet המונה 14,197,122 תמונות.
השימוש במודל המאומן הצריך מעט מאוד שינויים לקוד, כשעיקר השינוי הוא החלפת המודל אותו כתבתי במודל המאומן.
1. כדי להכין את מסד הנתונים התאמתי את גודל התמונות ל-224X224 והוספתי טרנספורמר שמנרמל את הטנסורים:
# required for a pre-trained model
IMG_SIZE = 224
transformations = [
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.ToTensor(),
# required for a pre-trained model
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
]2. את המודל אותו כתבתי החלפתי במודל המאומן:
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
class PreTrainedCNN(nn.Module):
def __init__(self):
# initialize super class
super(PreTrainedCNN, self).__init__()
self.pretrained = models.resnext50_32x4d(pretrained=True)
# freeze the parameters so we use the already trained weights
for param in self.pretrained.parameters():
param.requires_grad = False
# the only part that the model needs to learn is the last output of
# the fully connected part of the net
# that needs to classify to 3 classes
in_feats = self.pretrained.fc.in_features
self.pretrained.fc = nn.Linear(in_feats, 3)
def forward(self, x):
x = self.pretrained(x)
return x
model = PreTrainedCNN()
model.to(device)- את המשקולות של המודל המאומן הקפאתי כדי לשמור את המידע שהמודל אוצר בתוכו מתהליך האימון.
- את השכבה האחרונה החלפתי בשכבת פלט לינארית המסווגת ל-3 קטגוריות כי זה מה שדרוש לנו.
- מעבר לעובדה שהמודל המאומן שהורדנו הוא גדול ומורכב מאוד יש בו שכבות נורמליזציה מסוג batch normalization אשר מנרמלות את הנתונים העוברים בין שכבות הנוירונים ועל ידי כך מייצבות את הרשת ותורמות להאצת תהליך האימון.
להורדת הקוד בו השתמשתי במודל מאומן
כך נראית עקומת הלמידה:
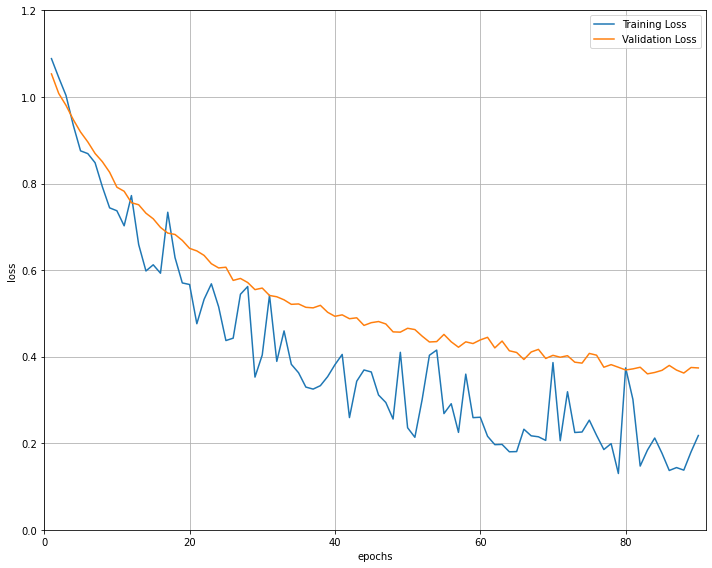
- עקומות ה-loss של סט האימון והבקרה יורדות שניהם מה שמראה שהמודל לומד.
- עקומת ה-loss של סט האימון יורד יותר מסט הבקרה מה שמלמד על overfitting.
- את הרעש בעקומת האימון אני נוטה לייחס גם כן ל- overfitting - המודל מורכב מדי בשביל הנתונים. אולי בגלל שהתחלתי מתמונות של 100X100 פיקסלים בעוד הרשת דורשת תמונות גדולות הרבה יותר.
בסיום אימון המודל הרצתי אותו על סט ה-holdout. אילו התוצאות:
Test Loss: 0.185157 Test Accuracy of 0: 100% ( 3/ 3) Test Accuracy of 1: 66% ( 2/ 3) Test Accuracy of 2: 100% ( 2/ 2) Test Accuracy (Overall): 87% ( 7/ 8)

- 87% דיוק. גבוה משמעותית ממה שקיבלנו עם המודל שכתבתי (75%).
להורדת הקוד בו השתמשתי במודל מאומן
המסקנה היא שאם זה לא תרגיל לימודי או שיש סיבה ממש טובה לכתוב את קוד הרשת הנוירונית שלנו עדיף להשתמש במודל מאומן. זה מאריך את החיים של המתכנת ;-) וידידותי לסביבה.
גם זה יעניין אותך
סיווג תמונות באמצעות מודל מאומן VGG16 וספריית TensorFlow
YOLO - בינה מלאכותית שמזהה עצמים מרובים בתמונות
רגרסיה קווית להערכת מחירי דירות באמצעות PyTorch ולמידת מכונה
לכל המדריכים בסדרה על למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.