
רגרסיה קווית להערכת מחירי דירות באמצעות PyTorch ולמידת מכונה
רגרסיה משמשת למציאת המידה שבה נתון מספרי אחד משפיע על אחר. במדריך זה נמצא רגרסיה קווית המתארת את השינוי במחיר דירה ביחס לשטח באמצעות למידת מכונה בעזרת ספריית PyTorch.

PyTorch היא ספרייה המשמשת ללמידת מכונה בדומה ל-TensorFlow. משתמשים בה לראייה ממוחשבת ועיבוד שפה אנושית. המפתחים העיקריים שלה הם קבוצת המחקר של פייסבוק. PyTorch חביבה מאוד על קהילת חוקרי הבינה המלאכותית ולכן חשוב להכיר אותה אם רוצים להשתמש ולהבין קוד שנכתב על ידי המוחות הפוריים ביותר בתחום למידת מכונה.
המדריך הראשון בסדרה על PyTorch מיועד להיכרות עם הממשק של השפה, ועם המושגים והתהליכים הבסיסיים של למידת מכונה באמצעות הדוגמה של מציאת משוואת קו. זה נכון שיש שיטות פשוטות בהרבה למציאת רגרסיה אבל אנחנו רוצים ללמוד כיצד להשתמש ב-PyTorch, וזו הדוגמה הפשוטה ביותר שהצלחתי למצוא.
את המדריך, כמו גם את יתר המדריכים בסדרה על למידת מכונה, פיתחתי על סביבת Colab שהיא סביבה חינמית המאפשרת להריץ קוד של פייתון על השרתים של גוגל.
להורדת קובץ Jupyter Notebook אותו נפתח במדריך
תזכורת לגבי רגרסיה קווית (לינארית)
נוסחת הרגרסיה הקווית היא:
Y = m*X + B + ε
- Y - הערך אותו חוזה המודל
- m - שיפוע הקו הישר
- B - נקודת החיתוך עם ציר ה - Y
- ε - שגיאה אותה מנסה הרגרסיה לצמצם כמה שניתן
במדריך זה, ננסה לחזות את שווי הדירה (ציר Y) על פי שטח הדירה (ציר X) באמצעות רגרסיה קווית.
המטרה שלנו בפיתוח מודל מסוג רגרסיה קווית היא למצוא קו ישר המתאר את הנתונים באופן הטוב ביותר. התיאור הטוב ביותר הוא כאשר ההפרש בין המחיר הצפוי ע"י המודל ובין הערך בפועל הוא הקטן ביותר.
יבוא ספריות הקוד
נייבא את 3 ספריות הקוד השימושיות ביותר ללמידת מכונה:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt- Numpy מאפשרת לעבוד עם מערכים רב-מימדיים.
- Pandas לסידור ולסינון המידע בדומה לגיליון אקסל.
- Matplotlib ליצירת תרשימים.
נייבא בנוסף את ספריית PyTorch:
import torchאת המדריך פיתחתי על סביבת colab החינמית המאפשרת להריץ מודלים של למידת מכונה על המחשבים של גוגל.
נברר את פרטי סביבת העבודה שגוגל הקצו לי:
מה הגרסה של PyTorch ?
torch.__version__1.10.0+cu111
עם איזה מעבד אני עובד?
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)cpu
- מעבד רגיל מסוג CPU
- את המידע הזה אחסנתי למשתנה device כי כפי שנראה בהמשך המדריך חשוב לאחסן את הטנסורים והמודל על אותו המעבד, כדי למנוע מצב שחלק מאוחסן על ה- CPU וחלק אחר על ה- GPU.
יבוא וסקירת מסד הנתונים
מסד הנתונים בו נשתמש במדריך מכיל את המחיר של בתים שנמכרו במדינת סקרמנטו בארה"ב לצד פרטי השטח ונתונים נוספים המשפיעים על המחיר. להורדת מסד הנתונים.
נייבא את מסד הנתונים כ- dataframe של pandas:
df = pd.read_csv('./houses.csv',usecols=['sq__ft', 'price'])- נשתמש בעמודות שטח הבית (sq__ft) והמחיר מפני שאנחנו רוצים לחזות את מחירי הבתים על סמך משתנה אחד בלבד שטח הנכס.
נציץ בשורות הראשונות של מסד הנתונים:
כמה שורות ועמודות?
df.shape
(985, 2)
- 985 דוגמאות של בתים מאופיינים על ידי שתי תכונות (שטח ומחיר).
מה ידוע על עמודות מסד הנתונים?
df.info()RangeIndex: 985 entries, 0 to 984 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sq__ft 985 non-null int64 1 price 985 non-null int64 dtypes: int64(2) memory usage: 15.5 KB
- עמודות מספריות int64 המתאימות לאנליזה שמטרתה מציאת קשר קווי בין עמודות.
נוודא שלא חסרים נתונים:
df.isnull().sum().sum() # 0- התוצאה היא אפס ולפיכך לא חסרים נתונים.
נתאר את מסד הנתונים באמצעות כמה ערכים סטטיסטיים:
df.describe()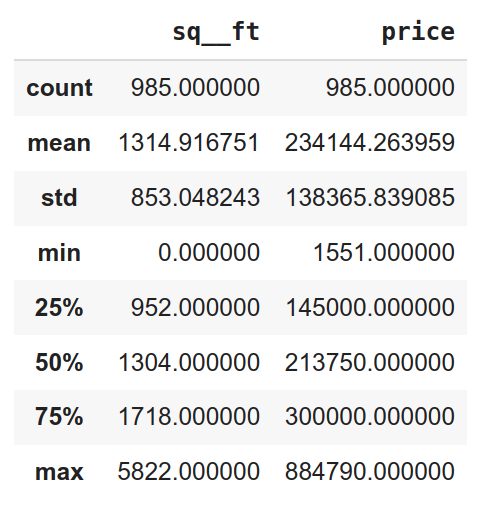
- המחיר הנמוך ביותר הוא 1551$ והגבוה 884,790$ עם ממוצע 234,144$
- השטח הנמוך הוא 0 והגבוה 5822 עם ממוצע 1314 (122 מ"ר)
הנתונים מאופיינים בשונות רבה ותוצאות קיצוניות דוגמת מחיר 0 מלמדות על הצורך לנקות את הנתונים כדי שאפשר יהיה לעבוד איתם.
אנחנו מצפים למתאם בינוני לפחות בין שטח הנכס למחיר. נבדוק אם זה המצב בנתונים שלנו.
# Find the correlation
df.corr()['sq__ft'].sort_values()price 0.333897 sq__ft 1.000000 Name: sq__ft, dtype: float64
קורלציה נמוכה של 33% בלבד בניגוד לציפייה שלנו שיהיה קשר חזק יותר בין גודל הבית ומחירו. למה?
נציג את הנתונים בגרף כדי לנסות להבין מה השתבש:
plt.plot(df['sq__ft'], df['price'], 'o')
plt.ylabel('Price')
plt.xlabel('Square foot')
plt.title('Price vs square foot')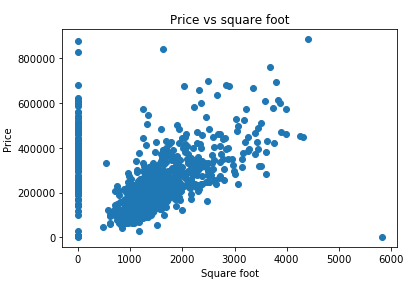
הכנת הנתונים ללמידת מכונה
לא כל הנתונים סבירים. לדוגמה, מקרים שבהם שטח הדירה אפסי או נתון חריג עבור שטח דירה גדול במיוחד ומחיר נמוך בצורה יוצאת דופן. נסנן דוגמאות חריגות (outliers) כדי שלא יפריעו למציאת הקשר בין שטח ומחיר.
# Remove the outliers
filtered_data = df.loc[(df.sq__ft > 10) & (df.sq__ft < 5000)]
df = filtered_dataעם כמה נתונים נשארנו?
df.shape(813, 2)
נוודא שאכן הצלחנו בהסרת החריגים:
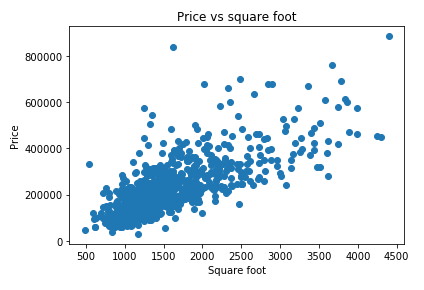
מה הקורלציה לאחר הסינון שעשינו?
df.corr()['sq__ft'].sort_values()price 0.728642 sq__ft 1.000000 Name: sq__ft, dtype: float64
- קיים מתאם בינוני-גבוה בשיעור של 73% בין שטח הנכס ומחיר.
- הסרת הנתונים החריגים גרמה לחיזוק הקורלציה בין שטח ומחיר.
נפריד את הנתונים לשני סטים: אימון ו- holdout.
- קבוצת אימון (train group) עליה נאמן את המודל
- קבוצת (holdout) שלא נשתמש בה בשום אופן בתהליך האימון, ורק אחרי שנסיים את אימון המודל נבחן באמצעותה את איכות המודל.
# separate a holdout set to evaluate the model at the end
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(filtered_data.sq__ft,
filtered_data.price,
test_size=0.1,
random_state=42)- הפונקציה train_test_split פיצלה את הדוגמאות לשתי קבוצות בתהליך אקראי כאשר 90% מהדוגמאות הוקצו לקבוצת האימון והיתר לקבוצת holdout.
Dataset
ב-PyTorch את מסד הנתונים מחזיקים בתוך קלאס פייתוני מסוג Dataset המחזיק רשימה list שבה כל פריט הוא tuple אשר מורכב מפיצ'רים ותגיות (features and labels) .
קלאס מסוג Dataset צריך ליישם 3 מתודות:
- __ init __(self) - המכיל בתוכו את המידע הדרוש ליצירת רשימת הטאפלים המאחסנת את מסד הנתונים. לדוגמה, שני טנסורים. אחד לפיצ'רים והשני לתגיות features and labels של מסד הנתונים.
- __ get_item __(self, index) - מאפשר את האינדוקס של מסד הנתונים כדי שאפשר יהיה לגשת לפריטים אחר כך לפי מספר האינדקס שלהם.
- __ len __(self) - מכיל את מספר הפריטים במסד הנתונים.
ניצור קלאס Dataset משלנו כדי לעבוד עם מסד הנתונים של מחירי הדירות:
# create a dataset based on a PyTorch class
from torch.utils.data import Dataset
class HouseDataset(Dataset):
def __init__(self):
# data loading
self.data = torch.unsqueeze(torch.from_numpy(X_train.values), 1)
self.labels = torch.unsqueeze(torch.from_numpy(y_train.values), 1)
def __getitem__(self, index):
# dataset[index] to get the index-th item
return self.data[index], self.labels[index]
def __len__(self):
# size of dataset
return len(self.labels)הקלאס מחזיק שני טנסורים: אחד בשביל הפיצ'רים והשני בשביל התגיות (features and labels)
נאתחל את מסד הנתונים:
# Initialize dataset
dataset = HouseDataset()עבור כל אינדקס שנעביר לו הקלאס יחזיר את הטאפל המתאים. לדוגמה, כדי שיחזיר את הדוגמה הראשונה:
print(dataset[0])
(tensor([1450]), tensor([228000]))
כמה דוגמאות במסד הנתונים?
print(len(dataset))
731
חלוקת הנתונים המשמשים לאימון לשניים
בשלב זה נחלק את הנתונים המשמשים לאימון המודל לשני סטים:
- סט אימון train dataset שישמש לאימון המודל.
- סט וידוא validation dataset נפרד שישמש להערכת ביצועי המודל במהלך האימון.
באמצעות המתודה random_split של PyTorch:
# split randomly into train and validation datsets
from torch.utils.data.dataset import random_split
train_set_size = int(len(dataset) * 0.7)
val_set_size = len(dataset) - train_set_size
train_dataset, val_dataset = random_split(dataset, [train_set_size, val_set_size])אנחנו משתמשים בשני סטים להערכת ביצועי המודל:
- validation בו נשתמש להערכת ביצועי המודל במהלך האימון.
- holdout בו נשתמש להערכת ביצועי המודל רק בסוף תהליך האימון.
Dataloader
במקרים מאוד פשוטים אפשר לאמן את המודל על כל מסד הנתונים בדרך כלל מסדי הנתונים הם גדולים מכדי שמעבד המחשב יוכל לעכל אותם בבת אחת ולכן אין לנו ברירה אלא לאמן את המודל כל פעם על מספר מצומצם של דוגמאות במבנה של אצוות קטנות mini-batch. בכל סיבוב של למידת מכונה epoch ישנה לולאה שרצה ומריצה בכל פעם מספר מצומצם של דוגמאות מתוך כל הדוגמאות. כאשר הלולאה רצה כמה פעמים שצריך כדי להריץ את כל הדוגמאות במסגרת ה- epoch.
במקום לכתוב את הקוד ליישום mini-batches בעצמנו אנחנו יכולים להיעזר בקלאס DataLoader של PyTorch שיעשה בשבילנו את העבודה.
כדי ליישם את הקלאס DataLoader נעביר לו את הפרמטרים: מסד הנתונים dataset, גודל ה batch_size, ואם לערבב את הדוגמאות באופן אקראי shuffle.
ניצור שני DataLoaderים נפרדים עבור סט האימון ו- validation:
from torch.utils.data import DataLoader
# call the DataLoader to get mini-batches
# separately for the training and the validation datasets
train_loader = DataLoader(dataset=train_dataset, batch_size=16)
val_loader = DataLoader(dataset=val_dataset, batch_size=16)התוצאה היא iterator של פייתון ועל כן ניתן לגשת למידע באמצעות:
next(iter(train_loader))
למידת מכונה באמצעות PyTorch
תהליך הלמידה מורכב מ-3 שלבים:
- בניית המודל כולל מבנה הקלט (input) והפלט (output), מספר השכבות ברשת הנוירונית, וכיו"ב.
- בחירת פונקציות loss ואופטימיזציה optimizer.
-
אימון המודל נעשה במסגרת של epochs. בכל epoch מריצים את כל דוגמאות האימון, מחשבים את ההפרש loss בין הערכים בפועל לתחזיות המודל, ומעדכנים את המודל כדי לצמצם את ההפרש loss כמה שניתן.
כל epoch כולל 4 שלבים:
- Forward pass - המודל מקבל את הנתונים הבלתי תלויים של קבוצת האימון עורך חישובים באמצעות הרשת הנוירונית ומנפיק פלט שהוא תחזית משוערת לגבי התוצאות. ואז פונקציית loss נכנסת לפעולה ומחשבת את ההפרש בין תחזית המודל ובין הערכים בפועל עבור קבוצת האימון. בדוגמה שלנו, המודל הוא קווי ולכן התוצאות שהוא מנפק הם תוצאה של העברת ערך X דרך הפונקציה:
a + bX
את התוצאות האילו משווה פונקציית loss לערכי y הידועים לנו עבור קבוצת האימון. כיוון שהמודל לינארי פונקציית loss היא Mean Square Error (MSE) המחשבת את ריבוע ההפרש בין ניבויי המודל (ŷ) לערכים האמיתיים (y) חלקי מספר הדוגמאות:MSE = 1/N * Σ(y - ŷ)^2
- Backward pass - חישוב הנגזרות החלקיות של ה- loss ביחס לפרמטרים. במקרה שלנו, אילו שני פרמטרים הנובעים ממשוואת הישר (a ו- b). חישוב הנגזרת מלמד כיצד כמות אחת משתנה כשעושים שינוי קטן בכמות אחרת. במקרה שלנו, כיצד ה- MSE loss משתנה ביחס לשינויים בשני הפרמטרים a ו- b.
- Update weights - עדכון המשקולות על פי ערך הגרדיאנטים במטרה לצמצם את ה-loss. במקרה שלנו, עדכון הפרמטרים a ו- b. העדכון נעשה באופן שמרני כאשר את הגרדיאנט כופלים בפקטור המכונה קצב למידה learning rate.
- חוזר חלילה - חוזרים על ארבעת שלבי התהליך תוך שמשתמשים בפרמטרים המעודכנים.
בניית המודל
ב-PyTorch המודל model הוא קלאס פייתוני. למידת מכונה נעשית במסגרת של רשת נוירונית המורכבת משכבות layers. PyTorch מצויד במגוון של שכבות. אחת האפשרויות היא linear layer בה נשתמש לאימון הרגרסיה הקווית:
# build the network
import torch.nn as nn # neural network module
input_size = 1
output_size = 1
# we only need a single layer for the linear regression
# the model converts the value of the input (area) to the output (price)
# thus, the model gets 1 input and outputs a single value
# we expect the model to be linear
model = nn.Linear(input_size, output_size).to(device)- המודול torch.nn מכיל מגוון קלאסים המייצגים שכבות ברשת נוירונית. אחת מהם היא שכבה לינארית שמתאימה למודל הרגרסיה הקווית שאנחנו מנסים על הנתונים.
- הקלאס nn.Linear() מקבל בתור פרמטרים את מבנה הקלט והפלט.
- תפקיד המודל להמיר את פיצ'ר 1, שטח, אותו הוא מקבל כקלט לפלט 1 שהוא המחיר, ומזה נובעת צורת הקלט והפלט, שניהם שווים 1. .
נשתמש במתודה הבאה להערכת ביצועי המודל:
plot(val_dataset)
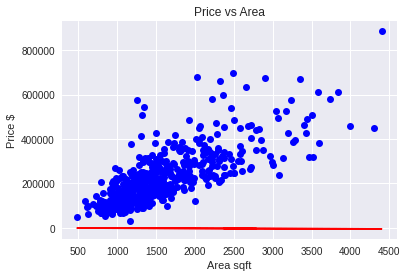
- הנתונים הם בכחול וקו הרגרסיה שמצא המודל הוא באדום.
- המודל טרם עבר תהליך של אימון ולכן לא מצליח למצוא רגרסיה מתאימה לנתונים.
Loss
כדי לחשב את ה-loss עבור רגרסיה משתמשים בריבוע השגיאה הממוצע Mean Square Error (MSE). אנחנו יכולים לפתח את הקוד לחישוב ה- loss - בעצמנו אבל גם בזה עדיף להשתמש בפונקציות קיימות של PyTorch:
# for linear regression use the loss function MSELoss
# that computes the Mean Squared Error(MSE)
# between the labels and predictions
loss_fn = nn.MSELoss()
Optimizer
כדי לעדכן את הפרמטרים אנחנו משתמשים באופטימייזר optimizer של PyTorch הלוקח בחשבון את הפרמטרים, קצב הלמידה learning rate ונתונים נוספים בעדכון הפרמטרים בהתאם לאלגוריתמים ידועים בתחום למידת מכונה דוגמת:
- SGD - Stochastic Gradient Descent
- Adam
במקרה זה, נשתמש באופטימייזר מסוג Adam עם קצב למידה 0.1:
import torch.optim as optim # optimizing algorithms. e.g: SGD, Adam
learning_rate = 0.1
# torch.optim is a package implementing various optimization algorithms.
# here I use the Adam optimizer with a learning rate of 0.1
# since this combination gave me the best results
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)- הסיבה שבגללה בחרתי ב-Adam ובקצב למידה 0.1 היא שזה מה שנתן לי את התוצאות הכי טובות בניסוי מקדים.
אימון המודל
בשלב זה, הגדרנו את כל מה שדרוש בשביל לאמן את המודל. הפונקציה הבאה מאמנת את המודל ב- mini-batches:
# train in mini-batches
def train_and_validate(num_epochs, train_loader, val_loader):
# track data
epochs = []
losses = []
val_losses = []
current_best_loss = np.inf
early_stopping_counter = 0
early_stopping_patience = 3
for epoch in range(num_epochs):
# training
# one mini-batch at a time
for x_batch, y_batch in train_loader:
# send to the same device as the model
x_batch = x_batch.float().to(device)
y_batch = y_batch.float().to(device)
# the actual training
# set model to "train" mode
# for layers/parts of the model that behave differently
# during training and valuation time.
# e.g., to turn on Dropouts Layers, BatchNorm Layers etc.
model.train()
# make predictions
yhat = model(x_batch)
# computes loss
loss = loss_fn(y_batch, yhat)
# backward pass:
# back propagation and calculate the gradients
loss.backward()
# updates the weights
optimizer.step()
# before the next iteration we have to be careful
# we need to empty our gradients
# because each time we call the backward function this sums up the gradients
# into the ".grad" attribute
# so we need to empty it
# never forget this!!
optimizer.zero_grad()
# once finished training
# it's time for evaluation
# for validation we must turn off gradient computation
with torch.no_grad():
# several mini-batches in a single epoch
for x_val, y_val in val_loader:
# send to the same device as the model
x_val = x_val.float().to(device)
y_val = y_val.float().to(device)
# set model to "validation" mode
# for layers/parts of the model that behave differently
# during training and valuation
# e.g., to turn off Dropouts Layers, BatchNorm Layers etc.
model.eval()
# make predictions
yhat = model(x_val)
# find validation loss
val_loss = loss_fn(y_val, yhat)
# track epochs and losses
epochs.append(epoch+1)
losses.append(loss.item())
val_losses.append(val_loss.item())
# Early stopping
if val_loss < current_best_loss:
current_best_loss = val_loss
early_stopping_counter = 0
else:
early_stopping_counter += 1
if early_stopping_counter >= early_stopping_patience:
print("early stopping")
break
print(f'epoch {(epoch+1)}/{num_epochs}, val_loss: {val_loss.item()}')
print("finished training")
return epochs, losses, val_losses- האימון נעשה במסגרת epochs כאשר הלולאה הראשית רצה כמה סיבובים שנגדיר לפונקציה.
- בכל epochs רצים שני תהליכים. אחרי שמסתיים התהליך הראשון, תהליך הלמידה, רץ תהליך ולידציה.
- בתהליך הלמידה חשוב להפעיל את המתודה model.train() כדי ששכבות המודל יעבדו בהתאם. לדוגמה, שכבות Dropout, batchNorm. מצד שני, בתהליך הולידציה נשתמש במתודה model.eval()
חשוב לעשות את תהליך הוולידציה באופן שלא ישפיע על חישוב הגרדיאנטים ולשם כך נשתמש ב:
with torch.no_grad()- כיוון שהאימון הוא במבנה של mini-batches בתוך הלולאה הראשית רצות לולאות נוספות אשר שולפות את ה-batches מה- DataLoader.
נאמן את המודל במהלך 100 מחזורי אימון:
# train
num_epochs = 100
epochs, losses, val_losses = train_and_validate(num_epochs, train_loader, val_loader)הפונקציה בה השתמשנו לאימון המודל אספה בנוסף את הערכים של ה-loss עבור סט האימון והוולידציה. נתאר את הנתונים בגרף:
plt.title('Loss')
plt.xlabel('Epochs')
plt.plot(epochs, val_losses, 'b', label="validation")
plt.plot(epochs, losses, 'r', label="train")
plt.legend()
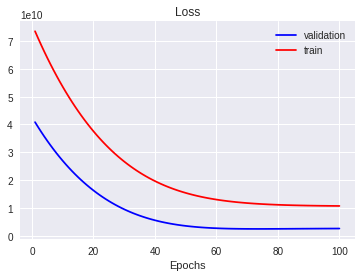
- מהגרף אפשר ללמוד שה-loss יורד עד ל-epoch 60, ואחר כך מתייצב.
במקרה שלנו, למידת המכונה היא מאוד מהירה וזולה אבל יש מודלים המצריכים שעות רבות להרצה ובהם עדיף לעצור את הלמידה כשה-loss מתייצב על ערך מינימלי כדי לחסוך במשאבים.
הפונקציה הבאה תשרטט את קו הרגרסיה שהמודל מצא:
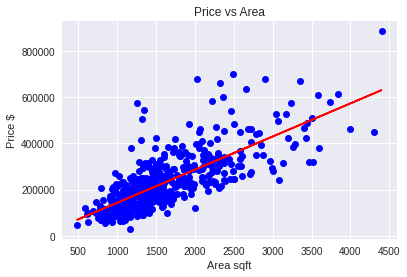
- אפשר לראות שהמודל מצא משוואת רגרסיה מתאימה לנתונים.
איזה פרמטרים המודל מצא כתוצאה מתהליך האימון?
for name, param in model.named_parameters():
print(name, f'{param.item():.4f}')weight 143.1771 bias 148.6809
- שיפוע הרגרסיה = 143
- החיתוך עם ציר ה-y = 149
הערכת המודל
יש לנו מודל ועכשיו אנחנו יכולים להוציא ממנו הערכות של מחיר על סמך נתונים אותם נזין לתוכו. לדוגמה, נתונים שמקורם בסט ה- holdout שלא נגענו בו בכל תהליך האימון:
xt = torch.tensor(X_test.values, dtype=torch.float32, device=device).unsqueeze(dim=1)
yt = torch.tensor(y_test.values, dtype=torch.float32, device=device)
yPred = model(xt)נעריך את הפרדיקציות של המודל על ידי השוואה עם המחירים בפועל באמצעות R^2 R-squared אשר מוצאת את אחוז השונות המוסברת על ידי המודל.
from sklearn.metrics import r2_score
print('R-squared for testing dataset: %.2f' % r2_score(y_test, yPred.detach().numpy()))R-squared for testing dataset: 0.37
- המודל מנפק את התחזיות בטנסורים הכוללים את חישוב הגרדיאנט. המתודה detach() מסירה את התכונה.
- הפכתי את הטנסורים של PyTorch למערכים של Numpy איתם sklearn יודע לעבוד.
נשווה את תוצאות המודל שפיתחנו באמצעות PyTorch עם מודל של sklearn שבו נהוג להשתמש בשביל חישוב רגרסיה קווית:
#https://scikit-learn.org/stable/auto_examples/linear_model/plot_ols.html#sphx-glr-auto-examples-linear-model-plot-ols-py
from sklearn import linear_model
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(X_train.values.reshape(-1, 1), y_train.values.reshape(-1, 1))
# Make predictions using the testing set
y_pred1 = regr.predict(X_test.values.reshape(-1, 1))
# Explained variance score: 1 is perfect prediction
from sklearn.metrics import r2_score
print('R-squared for testing dataset: %.2f' % r2_score(y_test, y_pred1))
print(f'sklearn linearRegression bias: {regr.coef_[0]}')
print(f'sklearn linearRegression intercept: {regr.intercept_}')R-squared for testing dataset: 0.38 sklearn linearRegression bias: [136.87573237] sklearn linearRegression intercept: [12969.09269086]
- שיעור השונות המוסברת על ידי המודל של sklearn הוא מעט גבוה יותר (0.38) ממה שמצא המודל אותו פיתחנו במדריך (0.37)
סיכום
למידת מכונה עם PyTorch היא לא הדרך המקובלת למצוא רגרסיה קווית. בשביל זה מספיק גליון אקסל או פונקציה של sklearn כשהכלל המנחה הוא שיש להשתמש בכלי הפשוט ביותר לביצוע המשימה שעדיין מצליח לעשות את העבודה. אבל למטרת המדריך, שהיא ללמד למידת מכונה באמצעות PyTorch מהיסוד כדאי היה להתחיל מהדוגמה הכי פשוטה שיכולתי לחשוב עליה.
הכלל המנחה הוא שיש להשתמש בכלי הפשוט ביותר לביצוע המשימה שעדיין מצליח לעשות את העבודה.
מדריכים נוספים על למידת מכונה שעשויים לעניין אותך:
10 דברים שחובה להכיר כשעובדים עם טנסורים של pytorch
מודלים ללמידת מכונה של SciKit-Learn
רגרסיה קווית באמצעות TensorFlow 2
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.