

פונקציות אופטימיזציה וכיצד לבחור את הפונקציה המתאימה ביותר למודל?
אחרי שבמדריך הקודם מצאנו את הפרמטרים האופטימליים לבניית רשת נוירונית המשמשת לזיהוי ספרות הכתובות בכתב יד. במדריך הנוכחי ננסה לשפר את דיוק המודל ואולי אף את משך הזמן שאורך תהליך הלמידה באמצעות שינוי הפונקציות המשמשות לאופטימיזציה של התהליך. בדרך נלמד אודות פונקציות האופטימיזציה המשמשות בלמידת מכונה וגם נמצא את הפונקציות שנותנות את התוצאות הטובות ביותר עבור המודל שלנו.
כדי להבין מהי אופטימיזציה צריך קודם כל לענות על השאלה "מה לומדת המכונה?". התשובה היא שהמכונה מפתחת מודל שמנפק תחזיות על סמך הנתונים שהוא קולט. בשפה מתמטית, הפונקציה F מקבלת פרמטרים X ופולטת תחזיות Y.
Y = F(X)
לדוגמה, קולטת שטח בתים ושכונת מגורים ופולטת את תחזית המחיר. המחשב לומד בתהליך להתאים את הפרמטרים של הפונקציה. לדוגמה, אם הקשר בין שטח דירה ומחיר הוא לינארי אז המודל לומד את השיפוע ונקודת החיתוך עם ציר ה-Y שמתארות באופן הטוב ביותר את המחירים במציאות.
ככל שהתחזית יותר קרובה למציאות כך המודל נחשב לטוב יותר. בתהליך הלמידה פונקציית עלות cost function מחשבת את שיעור השגיאה, המרחק בין התחזית שיצר המודל לבין הערכים בפועל. ככל ששיעור השגיאה נמוך יותר המודל נחשב לטוב יותר.
תהליך הלמידה מצמצם את פונקציית העלות למינימום בתהליך שנקרא gradient descent (מורד הגרדיאנט) שהוא אלגוריתם שתפקידו לצמצם את שיעור השגיאה למינימום. חוזרים על התהליך מספר פעמים (epochs) עד שהמודל מגיע לנקודה שהוא לא מצליח להשתפר יותר (זו נקודת ההתכנסות convergence).
השאלה היא באיזה כיוון הפונקציה צריכה לנוע כדי להגיע למינימום וגם באיזה קצב. כי אם השיפוע הוא מתון והפונקציה מתקדמת בצעדים קטנים מדי תהליך הלמידה עלול לארוך יותר מדי זמן. ואם השיפוע הוא תלול והפונקציה נעה בצעדים גדולים היא עלולה לפספס את המינימום.
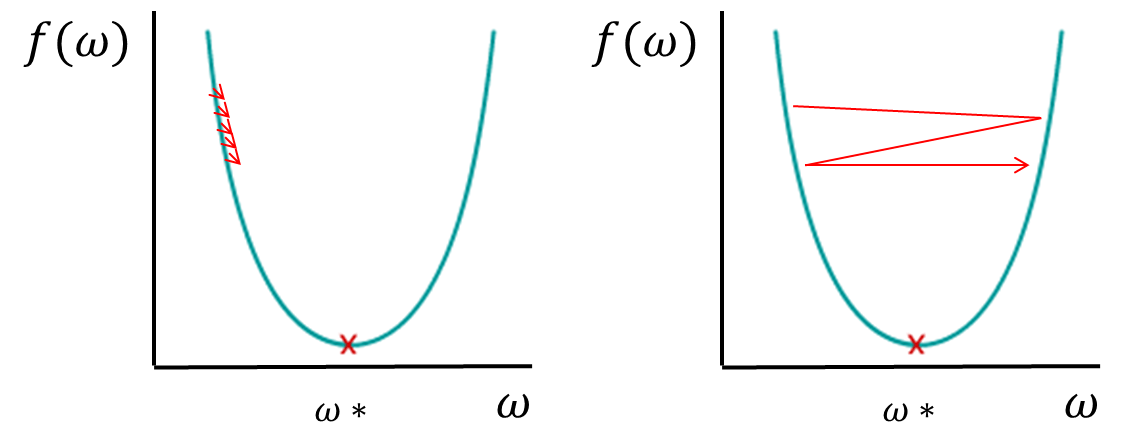
הפתרון הוא שימוש בפונקציות אופטימזיציה שתפקידם להתאים את גודל הצעד למתלול השיפוע. להקטין את הצעדים כשהמדרון תלול ולהגדיל אותם כשהמדרון רדוד. גודל הצעדים מכונה קצב למידה (Learning rate).
ניתן לחלק את פונקציות האופטימיזציה לשתי משפחות. אדפטיביים לעומת לא אדפטיביים.
פונקציות שאינם אדפטיביות שומרות על קצב למידה קבוע, לא משנה כמה תלול המדרון. לדוגמה, הפונקציה SGD שבה קצב הלמידה קבוע מראש.
הפונקציות האדפטיביות משנות את קצב הלמידה לפי שיפוע המדרון. לקבוצה זו שייכות הפונקציות AdaGrad ו-RMSprop.
פונקציה אדפטיבית אחרת היא Adam עם היתרון הנוסף שהיא משתמשת ב EMA-, קיצור של Exponentially Moving Average שמביאה בחשבון את ממוצע ה-epochs הקודמים.
ניתן לקרוא על פונקציות האופטימזציה לעיל ודומות להם בתיעוד הרשמי של keras.
איזו פונקציית אופטימיזציה היא המדויקת ביותר עבור המודל שלנו?
הקוד במדריך זה הוא המשך ישיר של קוד שפתחתי במדריך הקודם שעסק במציאת מבנה הרשת באופן ניסיוני.ניתן להוריד את הקוד המלא מכאן.
לקחתי את רשימת פונקציות האופטימיזציה מהדף הרשמי של keras:
from keras import optimizers
optimizers = [
'sgd',
'RMSprop',
'Adagrad',
'Adadelta',
'adam',
'Adamax',
'Nadam'
]הרצתי את כול הפונקציות בתוך הלולאה הבאה שמזינה את המודל אותו פיתחנו במדריך הקודם:
for optimizer in optimizers:
K.clear_session()
# Name the test model
name = 'test_optimizers_{}'.format(optimizer)
print(name)
# build the model
model = baseline_model(filters, units, optimizer)
# Fit the model
history = model.fit(X_train, y_train, validation_data=(X_test, y_test),
epochs=100, batch_size=32, verbose=1, callbacks=[es])
# Plot the history
plot_history(history,name,'acc')
plot_history(history,name,'loss')
# Print the summary values
val_loss, val_acc = model.evaluate(X_test, y_test)
summary = 'Summary: val_loss: {}, val_acc: {}'.format(val_loss, val_acc)
print(summary)- שימו לב שבין ריצה לריצה מתבצע ניקוי של הזיכרון באמצעות K.clear_session()
התוצאות
את התוצאות המלאות של ההרצה ניתן לראות במסמך המצורף. להלן תקציר התוצאות:
|
שיטת אופטימיזציה |
epochs |
accuracy |
|---|---|---|
|
SGD |
5 |
0.57 |
|
RMSprop |
6 |
0.98 |
|
Adagrad |
30 |
0.98 |
|
Adadelta |
6 |
0.99 |
|
Adam |
9 |
0.95 |
|
Adamax |
17 |
0.99 |
|
Nadam |
5 |
0.99 |
- Adadelta הוא שיפור של Adagrad.
- Adamax ו- Nadamהם שיפור של Adam.
- SGD הלא אדפטיבי מציג ביצועים נמוכים ביותר (0.57).
- האדפטיביים (RMSprop, Adagrad, Adam) מציגים ביצועים טובים בהרבה עם 95%-99% אחוזי דיוק.
- Adam הוא הכי פחות מדויק בין האדפטיביים.
- Adagrad הוא יותר מדויק אבל דורש את המספר הרב ביותר של epochs.
- Adagrad ו-Adam הם פחות מדויקים מהגרסאות המשופרות שלהם.
- Adadelta ו- Nadam המשופרים נותנים את התוצאה המדויקת ביותר (99%) עם מספר נמוך של epochs.
סיכום
האופטימייזר שבו משתמשים משפיע על דיוק התוצאות ועל משך תהליך הלמידה. לדוגמה, בניסוי שערכנו אופטימייזרים אדפטיביים (RMSprop, Adagrad, Adam) הצליחו לדייק הרבה יותר מאשר האלגוריתם הלא אדפטיבי (SGD). לפיכך, ניתן לשפר את תהליך הלמידה על ידי בחירת האופטימייזר האופטימלי.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.