
בחירת המודל המשמש ללמידת מכונה
המדריך Keras Tuner - לבחירת ההיפר-פרמטרים למודל למידת מכונה עוסק גם הוא באופטימיזציה של היפר-פרמטרים למודל ומציע להשתמש באלגוריתם של גוגל במקום בלולאות פייתון.
במדריך קודם למדנו להשתמש במודל מבוסס קונבולציה (convolution) על מנת לסווג תמונות, אולם לא הסברנו את הנימוקים לבחירת ההיפר-פרמטרים של הרשת, דוגמת מספר הנוירונים בשכבה חבויה או בחירת פונקציית אקטיבציה. במדריך זה נסביר כיצד ניתן לבחור את ההיפר-פרמטרים המתאימים ביותר למשימה אותה רשת נוירונית צריכה למלא.
המדריך Keras Tuner - לבחירת ההיפר-פרמטרים למודל למידת מכונה עוסק גם הוא באופטימיזציה של היפר-פרמטרים למודל ומציע להשתמש באלגוריתם של גוגל במקום בלולאות פייתון.
מהם הפרמטרים לבחירת הרשת הנוירונית המוצלחת ביותר?
ישנם שני פרמטרים עיקריים לבחירת מודל מוצלח:
- מידת loss. אני שואפים למידת loss נמוכה כמה שניתן.
- מידת ההתאמה. אנחנו שואפים להתאמה טובה (good fit) המתבטאת במידת שגיאה נמוכה ודוגמאות ביקורת טובות באותה מידה או קצת פחות מאשר הדוגמאות שהמודל מאומן עליהם.
אנחנו שואפים להתאמה טובה (good fit), ושואפים להימנע מהתאמת יתר, או ממידה נמוכה מדי או לא ידועה של התאמה.
התאמה נמוכה (underfit) היא מצב שבו מידת השגיאה גבוהה עבור דוגמאות האימון והביקורת. מצב אשר יכול לנבוע כתוצאה ממחסור בדוגמאות או כתוצאה ממודל (=קוד) שהוא לא מספיק טוב.
התאמת יתר (overfit) היא מצב שבו דוגמאות הביקורת מראות מידה שגיאה גבוהה משמעותית מדוגמאות האימון. מצב זה קשור בלמידה טובה מדי של דוגמאות האימון שבאה על חשבון היכולת להכליל ולמצוא דפוסים בדוגמאות אחרות. בדומה למצב שתלמיד משנן את החומר למבחן ללא הבנה.
התאמה לא ידועה (unknown fit) כשמידת השגיאה בדוגמאות האימון גבוהה אך נמוכה עבור דוגמאות הביקורת.
הגישה למציאת המודל הטוב ביותר
במאמר זה אנחנו מעוניינים למצוא את ההיפר-פרמטר הטוב ביותר עבור מספר הנוירונים בשכבות, קונבולוציה ו-dense עבור אותו מודל שפתחנו במדריך קודם (לחץ לקריאת המדריך).
כדי למצוא את מספר הנוירונים הטוב ביותר נאמן את המודל עם מספרים שונים של נוירונים, ונמצא את המודל הטוב ביותר מבחינת loss שגם מהווה התאמה טובה (good fit).
את מספר הנוירונים נגדיר באמצעות 2 רשימות:
- מספר הנוירונים בשכבת הקונבולוציה (מערך filters)
- מספר הנוירונים בשכבת ה-Dense (מערך units)
filters = [8,16,32]
units = [16,32,64]מספרי הנוירונים נמוכים יחסית והם נבחרו כדי לאפשר למודל לרוץ משך זמן סביר.
בכל רשימה 3 מספרים על פי מספר הנוירונים בשכבה. מפני שיש לנו שתי רשימות מספר האפשרויות יהיה 9.
ניתן להוריד את קוד המדריך בקישור הבא:
את המודל נגדיר בתוך פונקציה (baseline_model) שתקבל את מספר הנוירונים כפרמטר:
# Early stopping
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=1,
verbose=1,
mode='auto')
# create model
def baseline_model(num_filters, num_units):
# It is very important to clear the memory between each session run
K.clear_session()
model = Sequential()
model.add(Convolution2D(num_filters, (3, 3), activation='relu', input_shape=(1,28,28),
data_format='channels_first'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(num_units, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return modelאת הקריאה לפונקציה (baseline_model) נבצע בתוך לולאות שרצות על הרשימות:
for filter in filters:
for unit in units:
# Name the test model
name = 'test_filters_{}_units_{}'.format(filter, unit)
print(name)
# build the model
model = baseline_model(filter, unit)
# Fit the model
history = model.fit(X_train, y_train, validation_data=(X_test, y_test),
epochs=100, batch_size=32, verbose=1, callbacks=[es])
# Plot the history
plot_history(history,name,'acc')
plot_history(history,name,'loss')
# Print the summary values
val_loss, val_acc = model.evaluate(X_test,y_test)
summary = 'Summary: val_loss: {}, val_acc: {}'.format(val_loss, val_acc)
print(summary)המתודה fit() מחזירה את האובייקט History שמתעד את המידע שנאסף במהלך האימון. לדוגמה, תיעוד של תהליך אימון הכולל 5 epochs:
history.history{'loss': [0.580147385597229, 0.29688480496406555, 0.24299059808254242, 0.2060498148202896, 0.17938044667243958], 'accuracy': [0.8296666741371155, 0.9117500185966492, 0.9283833503723145, 0.9388333559036255, 0.9466333389282227], 'val_loss': [0.29744672775268555, 0.23718319833278656, 0.1998429298400879, 0.16826747357845306, 0.14391694962978363], 'val_accuracy': [0.9135000109672546, 0.9301999807357788, 0.9440000057220459, 0.9510999917984009, 0.9573000073432922]}
מתוך הלולאה נדפיס את הערך הסופי של ה-loss וה-accuracy עבור סט הביקורת (validation).
בנוסף, נקרא לפונקציה שתאפשר לנו לשרטט את התפתחות הפרמטרים loss ו-accuracy לאורך האימון:
def plot_history(history,name,metric):
label_val = 'val_%s' % metric
train = history.history[metric]
test = history.history[label_val]
# Create count of the number of epochs
epoch_count = range(1, len(train) + 1)
# Visualize loss history
plt.plot(epoch_count, train, 'r-')
plt.plot(epoch_count, test, 'b--')
plt.legend(['Train', 'Test'])
plt.xlabel('Epoch')
plt.ylabel(metric)
plt.title('%s : %s' % (metric,name))
plt.show()
תוצאות
את התוצאות של הרצת הקוד סיכמתי באמצעות הטבלה להלן שבה ניתן לראות את שני ההיפר-פרמטרים: filters, מספר נוירונים בשכבת הקונבולוציה, units , מספר הנוירונים בשכבה Dense. לצד תוצאות הרצת המודל במצבים השונים: מספר epochs, משך הזמן בשניות שנידרש לאימון המודל (running_time), וערכי ה-loss וה-accuracy עבור דוגמאות הביקורת (validation).
| מס"ד | filters | units | epochs | running_time (sec) | val_loss | val_acc |
|---|---|---|---|---|---|---|
| 1 | 8 | 16 | 8 | 480 | 0.1055 | 0.9689 |
| 2 | 8 | 32 | 7 | 420 | 0.0856 | 0.9739 |
| 3 | 8 | 64 | 4 | 250 | 0.088 | 0.9732 |
| 4 | 16 | 16 | 9 | 900 | 0.08 | 0.976 |
| 5 | 16 | 32 | 5 | 530 | 0.072 | 0.9778 |
| 6 | 16 | 64 | 5 | 540 | 0.073 | 0.9765 |
| 7 | 32 | 16 | 5 | 930 | 0.0816 | 0.9739 |
| 8 | 32 | 32 | 6 | 1140 | 0.086 | 0.9743 |
| 9 | 32 | 64 | 5 | 965 | 0.069 | 0.9786 |
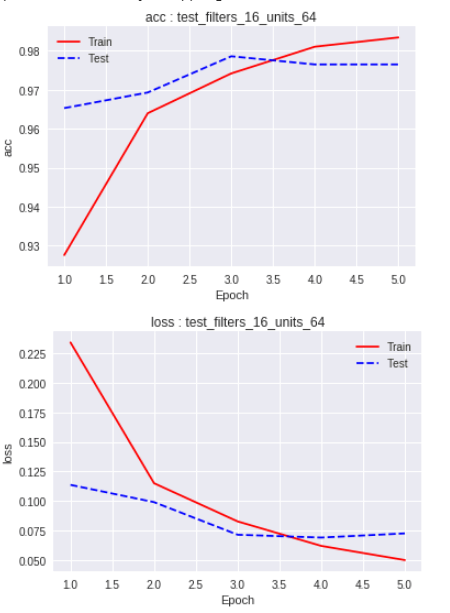
ערך ה-loss הנמוך ביותר מתקבל עבור המקרה התשיעי (32 נוירונים בקונבולציה ו-64 ב-Dense), אבל בתרשים המצ"ב נראה שערך ה-loss נמוך משמעותית יותר עבור דוגמאות האימון מאשר דוגמאות הביקורת. מזה אנו יכולים להסיק שהמודל למד יותר מדי טוב את דוגמאות האימון, ועל כן הוא לא מצליח להכליל לדוגמאות הביקורת. זה מצב של overfit שאינו רצוי לנו, ולפיכך לא כדאי לנו להשתמש במודל.
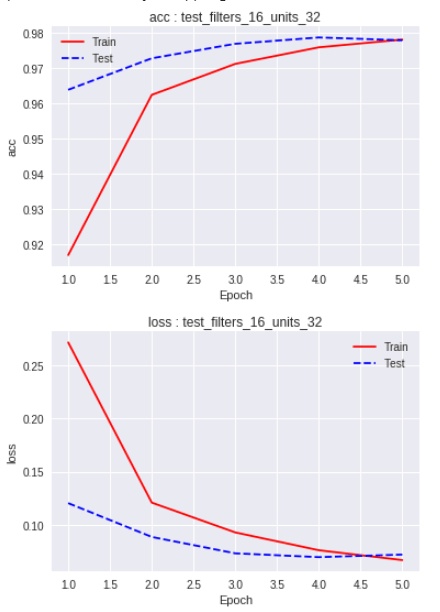
ערך loss נמוך ניתן לראות גם במקרה החמישי (16 נוירונים בקונבולציה ו-32 ב-Dense). מלבד ערך loss נמוך ניתן לראות בתרשים שערך ה-loss של קבוצת הביקורת כמעט זהה לזה של קבוצת האימון שזה המצב הרצוי המעיד על התאמה טובה.
סיכום
במדריך זה ראינו כיצד להתאים היפר-פרמטרים של מודל כדי למצוא את המודל הטוב ביותר באמצעות הרצת תרחישים שונים והשוואת התוצאות בשני אופנים: ערך loss ומידת ההתאמה (fit). כפי שניתן למצוא את ההיפר-פרמטרים הטובים ביותר עבור מספר נוירונים ניתן להשתמש באותה הגישה להתאמת היפר-פרמטרים נוספים דוגמת מספר מספר שכבות הקונבולוציה, מספר שכבות dense, ופונקציות אקטיבציה שונות.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.