
זיהוי ספרות שכתב אדם על ידי בינה מלאכותית - פיתוח המודל
במדריך זה נלמד את המחשב לזהות ספרות הכתובות בכתב יד באמצעות מודל מבוסס בינה מלאכותית.
המודל מבוסס על רשת נוירונית שמייצרת בינה מלאכותית. בינה פירושה שמתכנתים לא צריכים לקודד את כל המצבים האפשריים לתוכנה, ובמקום זאת ניתן לכתוב תוכנית שתגרום למחשב להבין דברים בעצמו. בדוגמה שנפתח במדריך, המחשב ידע לזהות ספרות שמשתמש כותב על גבי צג המחשב, למרות שנאמן אותו באמצעות סט תמונות של ספרות שנוריד ממאגר תמונות סטנדרטי.
אבל מה זה רשת של נוירונים? המוח שלנו מורכב מנוירונים אבל במודל הממוחשב שאותו נסביר במדריך נוירון הוא מקום בזיכרון המחשב שמחזיק מספר. לפיכך, הרשת שעליה נדבר במדריך, מורכבת מכמה מספרים שמחוברים ביחד. תכף נראה איך זה עובד.
הרשת מסודרת מכמה שכבות של נוירונים. השכבה הראשונה קולטת את התמונה, והאחרונה פולטת את התוצאה. בין שתי השכבות קיימת שכבה חבויה אחת או יותר שבהם מתבצעת הלמידה.
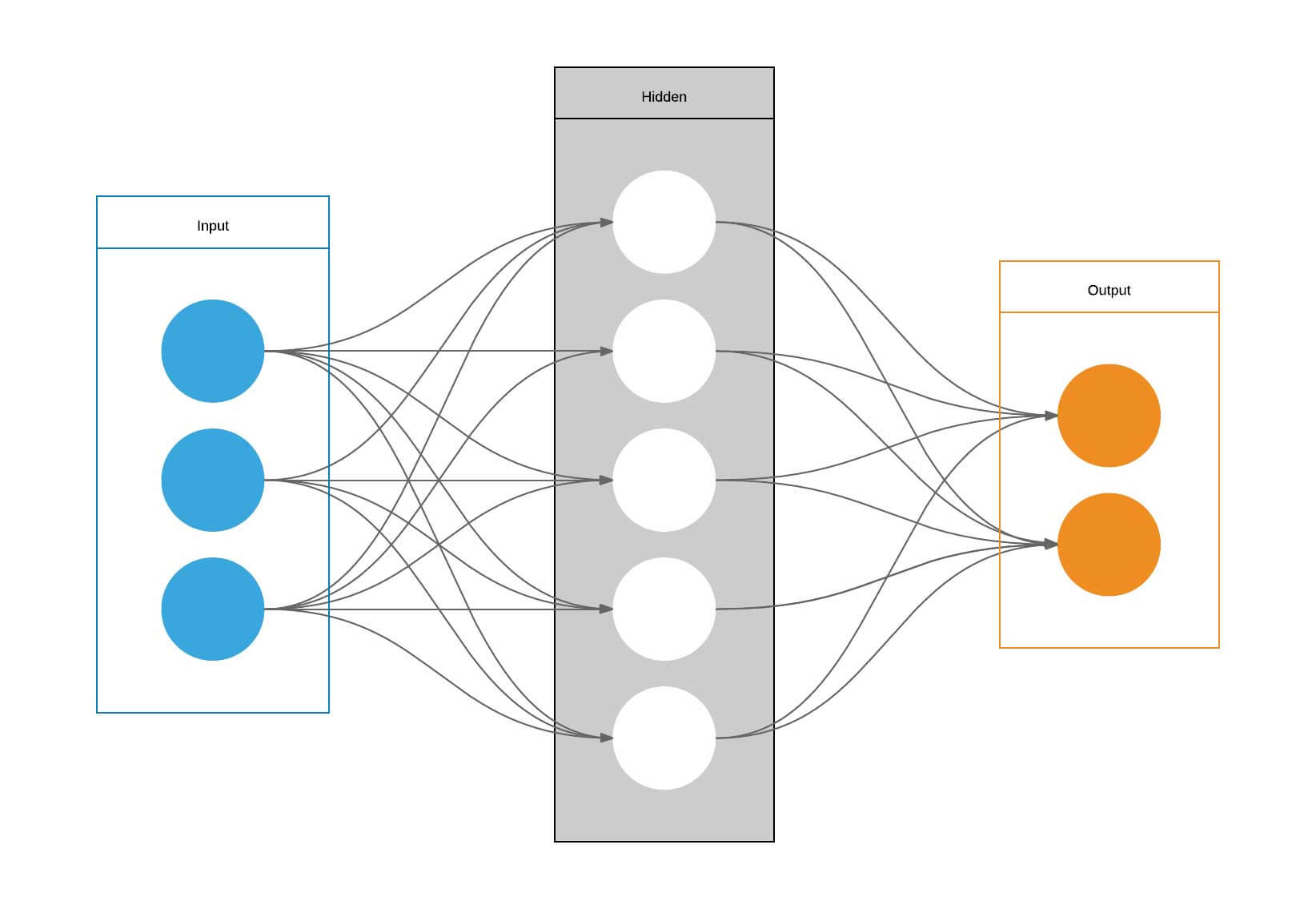
למידה משמעותה פיתוח היכולת לבצע משימה מוגדרת. בדוגמה שלנו, הלמידה משמעותה אימון הרשת לזהות ספרות שכתבו אנשים. כדי לרכוש את היכולת צריך לאמן את הרשת. במקרה שלנו, נציג לרשת 60,000 ספרות שנכתבו על ידי אנשים שונים, ואחרי שנסיים להציג את כל הספרות, נציג לרשת עוד 10,000 ספרות מסט ביקורת ששמרנו בצד, ונבקש ממנה לזהות את הספרות. במקרה של זיהוי נכון, הרשת תקבל פידבק חיובי, ובמקרה של זיהוי שגוי פידבק שלילי. נחזור על התהליך של הצגת 60,000 ספרות לאימון + 10,000 ספרות בקרה במשך 10 ריצות רצופות ונראה כיצד הרשת משפרת את אחוזי הדיוק בכל פעם.
אבל מה גורם לרשת ללמוד? התשובה היא שכל חלק של הרשת מתמחה בזיהוי של דפוס מסוים, והשילוב של החלקים הוא שנותן את התוצאה. לדוגמה הספרה 1 מורכבת מקו אנכי שאותו יזהו אותם חלקים של הרשת הנוירונית שמתמחים בזיהוי קווים אנכיים. אותו חלק של הרשת שמתמחה בזיהוי קווים אנכיים יכול לשמש גם לזיהוי הספרה 9. רק שבמקרה זה נדרשת גם הפעלה של חלק אחר של הרשת שמזהה לולאה. רק חיבור של שני חלקי הרשת יכול להבחין בין הספרות 1 ל-9. כלומר, החלקים השונים ברשת מתמחים בזיהוי חלקים שונים שמשתלבים ביניהם כדי לתת את התמונה הכוללת.
וזה מביא אותנו לשאלה מדוע שחלקים מסוימים של הרשת יזהו דפוס מסוים ולא אחר, למה שנוירונים מסוימים יזהו לולאה ואחרים קו? כל קשר בין נוירון לבין הנוירון בשכבה הבאה מקבל משקל (weight). ואם סכום המשקלים הוא גבוה משמעותית עבור מאפיין מסוים בתמונה (דוגמת קו או לולאה) אז אותו חלק של הרשת הנוירונית הופך למומחה בזיהוי המאפיין.
סכום המשקלים יכול לקבל כל ערך אבל נרצה שהערך יהיה בין 0 ל-1. ולשם כך, נהוג להשתמש בפונקציה סיגמואידית (לוגריתמית), אשר דוחסת את הערכים שהיא מקבלת לטווח שבין 0 ל-1. הערכים ששואפים ל-1 הם הסבירים והערכים הקרובים ל-0 אינם סבירים.
הפונקציה הסיגמואידית היא דוגמה לפונקצית אקטיבציה, ותפקידה לברור את החלקים המשמעותיים לרשת מכל הרעש. בדרך כלל, פונקציית האקטיבציה היא לוגריתמית ולא לינארית כדי שניתן יהיה לפענח באמצעותה דפוסים מורכבים שלא ניתן לתאר באמצעות קו ישר בלבד. במידה ובעיית הרעש מתמידה בכל הקישורים שמזינים את הנוירון אז הרשת מוסיפה הטייה (bias). לדוגמה, אם רמת הרעש התמידית היא 5 אז הרשת מפחיתה 5 מסכום המשקלים לפני שהיא מכניסה את הסכום לתוך פונקצית האקטיבציה.
כל הערכים המתקבלים כתוצאה מהאימון הם הגורמים להסתגלות המערכת לזיהוי הדפוסים שהיא נדרשת ללמוד. לפיכך, למידת מכונה היא היכולת של רשת נוירונים למצוא את כל המשקלים וההטיות המתאימים ביותר כדי לפתור את הבעיה.
המודל
המודל מייצר רשת CNN, Convolutional Neural Networkׁׁ, שהיא השימושית ביותר לזיהוי של תמונות בגלל שהיא מסוגלת להתחשב בממד הרוחב והגובה של הפריטים מהם מורכבת התמונה. הרשת שבה נהוג להשתמש לצורך קונבולציה מתאפיינת במבנה מתכנס, שמאפשר לנוירון להרכיב תמונה כוללנית יותר מהנוירונים בשכבה הקודמת כיוון שהוא ניזון ממספר נוירונים בשכבה שלפניו. הודות למבנה המתכנס השכבה האחרונה של הרשת רואה את התמונה הכללית, ומסיקה מה רואים בתמונה.
מודלים של קונבולוציה המשמשים לסיווג מורכבים משני חלקים:
- בסיס קונבולוציה convolutional base המורכב מבלוקים של קונבולוציה
- שאחריו מגיע החלק המסווג של הרשת
כלים ושיטות
המודל נכתב באמצעות TensorFlow ספרייה של למידת מכונה הכתובה בשפת Python.
אימון המודל נעשה על סט נתונים מפורסם ששמו MNIST הכולל 70,000 תמונות של ספרות כתובות בכתב יד.
פיתוח המודל
נתחיל מייבוא הספריות שאותם נצטרך לצורך פיתוח המודל:
import numpy
import matplotlib.pyplot as plt
from tensorflow import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras import layers- Numpy - היא ספרייה של פייתון לעבודה עם מערכים רב מימדיים.
- ב- Matplotlib - ליצירת גרפים ותרשימים.
- TensorFlow ו-Keras בשביל למידת מכונה.
את הנתונים אנחנו טוענים מ-MNIST, סט של 70,000 תמונות של ספרות שכתבו אנשים שעברו סטנדרטיזציה לגודל של 28 על 28 פיקסלים בצבעים אפורים. את הנתונים נטען באמצעות פונקציה שמספקת ספריית TensorFlow.
ערכי ה-x הם התמונות של הספרות, וערכי ה-y הם שמם של הספרות, כשאנחנו מפצלים את סט התמונות לקבוצת אימון (train) וקבוצת בקרה (test).
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()את התמונות נעצב מחדש לתמונות בממדים 28X28 פיקסלים כדי שיתאימו להזנה לרשת נוירונית convolutional. שלב זה נדרש מפני שהתמונות MNIST פרוסות לרוחב של 728X1. לצורך הזנה לרשת נאורונית רגילה שאינה convolutional
# reshape to be [samples][pixels][width][height][channels_number]
# float32 is the data type that keras expects
img_width=28
img_height=28
X_train = X_train.reshape(X_train.shape[0], img_width, img_height, 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], img_width, img_height, 1).astype('float32')נוודא את הצורה של סט נתוני האימון והמבחן לאחר שינוי הצורה:
print(X_train.shape)
print(X_test.shape)(60000, 28, 28, 1) (10000, 28, 28, 1)
- הערך הראשון הוא מספר הדוגמאות (60,000 לאימון ו-10,000 לבדיקה).
- שני הערכים הבאים הם רוחב וגובה שהם 28 פיקסלים בהתאם לממדי התמונות שאנחנו מקבלים מ-MNIST.
- הערך הרביעי הוא מספר הערוצים של הצבע. בדרך כלל נזדקק לשלושה (rgb), אבל התמונות שלנו אפורות אז נסתפק ב-1.
- את הערכים הפכנו לסוג float32 כדי להגביל את דיוק הפיקסלים ולהפחית את הדרישות מהמחשב שמריץ את התוכנה.
כדאי לנרמל את הנתונים כדי לייצב את הרשת ולקצר את תהליך הלמידה. נרמול מקובל הוא לפי ערכי מינימום ומקסימום. כיוון שישנם 255 גוונים אפשריים של אפור נחלק כל אחד מסט הערכים ב-255 ונקבל ערך שהוא בין 0 ל-1.
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255את ערכי התוצאות האפשריות נקודד בשיטת one hot encode, שבה סט התוצאות האפשריות מקודד למערך של אפסים עם פריט אחד שערכו 1 במקום שמייצג את מיקומה היחסי של הספרה במערך.
בדוגמה שלנו, אפשריות 10 ספרות (סט שנע בין 0 ל-9), ולפיכך נשתמש במערך של 10 פריטים כדי לייצג כל ספרה.
לדוגמה, קידוד של הספרה 0 יעשה באמצעות 1 במיקום השמאלי ביותר ואחריו 9 פריטים שערכם 0.
[1,0,0,0,0,0,0,0,0,0]
ובשביל לקודד את הספרה 1 רק הפריט השני משמאל יקבל את הערך 1.
[0,1,0,0,0,0,0,0,0,0]
לקידוד עצמו אחראית הפונקציה to_categorical של ספריית numpy:
# one hot encode outputs
from keras.utils.np_utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
num_classes = y_test.shape[1]נציץ בתוצאה:
y_train[0]array([0., 0., 0., 0., 0., 1., 0., 0., 0., 0.], dtype=float32)
לפני שנפתח את המודל עצמו, נריץ את הפונקציה הבאה כדי לראות דוגמה של התמונות שירדו עם הספרייה:
def plot_images(images, labels):
# Create figure with 2x2 sub-plots.
fig, axes = plt.subplots(2, 2)
fig.subplots_adjust(hspace=0.3, wspace=0.3)
# plot 4 images
for i, ax in enumerate(axes.flat):
# Plot image
ax.imshow(images[i].reshape([28,28]), cmap=plt.get_cmap('gray'))
# Plot label
for idx, val in enumerate(labels[i]):
if(val == 1):
ax.set_xlabel('Label : %d' % idx)
plt.show()
plot_images(X_train[0:4], y_train[0:4])זו התוצאה, הצגת 4 התמונות הראשונות בסט התמונות:

אימון המודל
נאמן את המודל בתוך פונקציה:
def make_model():
model = Sequential()
# input
model.add(layers.Input(shape=(28, 28, 1)))
# conv block 1
model.add(layers.Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.2))
# conv block 2
model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.2))
# flatten
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
# classify
model.add(layers.Dense(num_classes, activation='softmax'))
return modelהשכבה החבויה היא שכבת הקונבולוציה (convolution) שנתנה לשיטה את שמה. שכבה זו מריצה 32 פילטרים בגודל 3*3 פיקסלים על כל תמונה. הפילטרים הם הנאורונים של השכבה הכוללים פונקצית אקטיבציה (relu). כל פילטר עובר על כל התמונה בסדרה של צעדים strides שמזיזים אותו בכל פעם בפיקסל 1 בודד. התוצאה היא סדרה של ייצוגים חופפים של התמונה המכונה feature map. כל פילטר מנפק ייצוג אחד של התמונה, ולפיכך במקרה שלנו התוצאה של שכבת הקונבולוציה היא 32 feature maps.
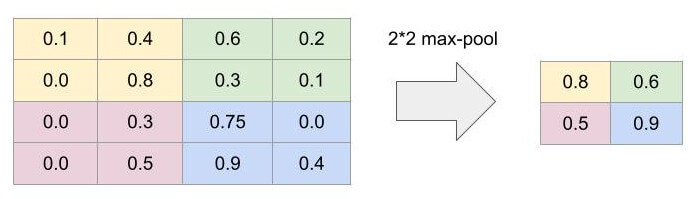
השכבה הבאה היא שכבת דגימה (pooling layer) שתפקידה לצמצם כל ריבוע פיקסלים שממדיו 2*2 פיקסלים שנמסר לה על ידי השכבה הקודמת לריבוע בודד. שכבה זו היא פשוטה ביותר, אינה כוללת פונקצית אקטיבציה, ובדרך כלל הריבועים אינם חופפים. ברשת שלנו, אנו משתמשים בסוג max pooling שלוקח מכל ארבעה פיקסלים את הערך הגבוה ביותר ואותו הוא מעביר לשכבה הבאה. מטרת ה-pooling היא להפוך את הדוגמאות לפחות קונקרטיות ועל ידי כך לעודד הכללות שיקלו על המודל זיהוי דוגמאות שלא נכללו בסט האימון. יתרון נוסף הוא בכך שהתמונה הופכת לפחות מורכבת וכתוצאה מכך פוחתים משאבי המחשוב הדרושים ללמידה.
התמונה הבאה מדגימה את העיקרון של max pooling:
שכבת ה-dropout שומטת באקראי 20% מהמידע מהשכבה הקודמת. המטרה היא למנוע מהמערכת ללמוד יותר מדי טוב את הדוגמאות כדי למנוע את ירידת היכולת לזהות ספרות שלא נכללו בסט הדוגמאות ששימשו לאימון.
בלוק של קונבולוציה כולל שכבת קונבולוציה (convolution) שאחריה שכבת דגימה (pooling). ניתן לשלב בתוך בלוק הקונבולציה שכבת dropout.
מודל בדרך כלל מכיל יותר מאשר בלוק קונבולוציה אחד. המודל במדריך כולל 2 בלוקים.
הסיווג בפועל של התמונות נעשה על ידי רשת נוירונית רגילה (feed forward net) מסוג Dense.
כדי להעביר את המידע מהבלוקים של הקונבולוציה לרשת הנוירונית הרגילה אנחנו משתמשים בפונקצית flatten שתפקידה לשטח את המידע לוקטור (שכבה שגובהה פיקסל 1 בודד).
שכבת ה-dense מכילה 128 פיקסלים בלבד (במקום ה-784, 28*28 איתם התחלנו) ובה כל נוירון מחובר לכל אחד מהנוירונים בשכבה הבאה.
השכבה האחרונה היא שכבת הפלט ובה 10 נוירונים בלבד לפי מספר התוצאות האפשריות. כל נוירון מייצג ספרה אחת בודדת (0-9), והערך שהנוירון מקבל נע בטווח שבין 0 ל-1. ערך קרוב ל-0 הוא מצביע על אפשרות שאינה סבירה וככל שהערך קרוב ל-1 האפשרות הופכת לסבירה יותר. בשכבת הפלט פועלת פונקצית אקטיבציה מסוג softmax הגורמת לכך שסכום ההסתברויות של הנוירונים בשכבה יהיה 1. הודות לפונקצית האקטיבציה תמיד נקבל שאחד מ-10 הנאורנים בשכבה הוא הפתרון הסביר ביותר לדוגמה שהזנו לרשת הנאורונית.
עקרונות מנחים בבניית CNN
קיימים כמה עקרונות מנחים בבניית מודלים של למידת מכונה מבוססי CNN:
מתחילים מהארכיטקטורה הכי פשוטה ואם היא לא נותנת את התוצאה המקווה מוסיפים שכבות ופילטרים כמה שצריך כדי לשפר את ביצועי המודל.
רשת CNN מורכבת משניים:
- אזור שלומד את פרטי התמונה feature extraction
- ואחריו אזור מסווג classifier
CNN עשויים משכבת קונבולוציה שאחריה שכבת pooling:
Conv-Pool
או 2 שכבות קונבולוציה שאחריהם שכבת pooling:
Conv-Conv-Pool
-
שכבת הקונבולוציה (convolution) המכונה גם פילטר filter צריכה להיות בעלת גודל אי-זוגי. לדוגמה, 3X3 או 5X5. בגלל שלצורה זו תמיד יש פיקסל מרכזי אשר שומרת את מיקום האקטיבציה אחרי פעולת השכבה. על פי העיקרון של "הכי פשוט שעדיין עובד" נעדיף פילטרים קטנים של 3X3 ורק אם אין ברירה נשתמש בפילטרים גדולים יותר.
-
בשכבות הביניים נתחיל ממספר פילטרים קטן בשכבת הקונבולוציה הראשונה ובשכבות הבאות נגדיל את מספר הפילטרים. לדוגמה, מתחילים מ-32 פילטרים בשכבת הקונבולוציה הראשונה, בשכבה הבאה 64, 128 בשלישית וכיו"ב.
-
כדאי להשתמש ב-padding="same" על מנת לשמור על גודל התמונה שנוטה להתכווץ בתהליך וגם כדי לשמור את המידע בשוליים של התמונה.
בשביל שכבות pooling משתמשים ב-kernels שגודלם 2X2 או 3X3. עדיף להתחיל בקטן מ-2X2 ורק אם אין ברירה להגדיל את הממדים.
מתחילים מרשת קטנה ופשוטה ואם היא לא מספקת את התוצאות מוסיפים שכבות עד שהמודל מגיע לרוויה -overfit - כאשר המודל מתקשה משמעותית יותר לסווג את נתוני קבוצת המבחן.
צריך לכוונן את ההיפר-פרמטרים של הרשת, כולל: מספר epochs, קצב הלמידה learning rate, פונקציות האקטיבציה activation functions, וכיו"ב
הרצת המודל
נקמפל את המודל:
# Build and compile the model
model = make_model()
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])בקומפילציה של המודל השתמשנו בפונקציית אופטימיזציה מסוג Adam שמגדילה את ההתאמות האוטומטיות ש- TensorFlow עושה לפרמטרים של המודל במטרה למצוא את הערך המינימלי של ההפרש loss בין הערכים שמצא המודל וערכי האמת. פונקצית אופטימיזציה מסוג Adam עושה התאמות גדולות במשקלים weights כאשר ה- loss הוא גבוה והתאמות קטנות כאשר ה- loss הוא נמוך. גודל ההתאמות הוא חשוב מפני ששינויים גדולים מדי יכולים לגרום לפספוס המינימום בעוד שינויים קטנים מדי יגרמו למשך האימון להתארך יתר על המידה.
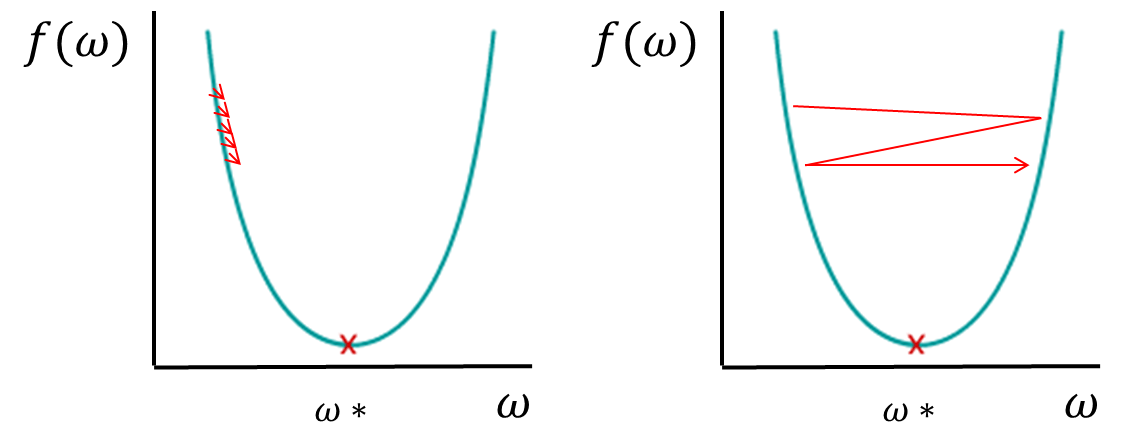
כשמחפשים את המינימום גודל צעד גדול מדי יגרום לפספוס בעוד גודל צעד קטן מדי יגרום למשך אימון המודל להתארך יתר על המידה
כדי לאמן את המודל נריץ אותו 10 פעמים על כל התמונות, וכדי להימנע מלהכביד על המחשב יותר מדי נזין את התמונות באצוות של 100.
# Fit the model
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=10, batch_size=100)
הערכת ביצועי המודל
נעריך את ביצועי המודל על קבוצת המבחן:
results = model.evaluate(x_test, y_test, verbose=0)
print(f"loss: {results[0]}")
print(f"accuracy:" {results[1]}")לאחר 10 ריצות אימון קיבלתי 99% אחוזי דיוק בזיהוי של דוגמאות בקבוצת המבחן.
להורדת הקוד אותו פיתחנו במדריך
בחינת המודל בשטח
את המודל ייצאתי באמצעות tensorflow.js וקיבלתי שני קבצים בהם אני משתמש בתור ה-api של האפליקציה כפי שהסברתי במדריך אחר זיהוי ספרות שכתב אדם באמצעות בינה מלאכותית. ב-30 הניסיונות שעשיתי הגעתי ל-100% זיהוי עבור ספרה בודדת שכתבתי על מסך המחשב בכתב ידי. כשקשקשתי במקום לכתוב ספרה המודל זיהה בטעות את הקישקוש כספרה. לא מפתיע בהתחשב בעובדה שהמודל שפיתחנו במדריך יודע לזהות רק ספרות.
לסיכום
המודל במדריך מבוסס על רשת נוירונית מתכנסת CNN שהיא המקובלת ביותר לזיהוי תמונות על ידי מחשב בגלל היכולת לזהות פרטים מסדר גבוה ככל שנוספות שכבות לרשת. במדריכים הבאים בסדרה נראה כיצד להשתמש במודלים קיימים שאומנו על ידי גדולי המומחים בתחום כדי לסווג תמונות.
לכל המדריכים בנושא של למידת מכונה
נכתב במקור ב- 06.10.2018 ושוכתב ב-13.06.2022 כדי שיוכל לעבוד עם הגרסאות החדשות של Keras
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.