
רגרסיה לינארית באמצעות Keras
לגרסה חדישה של המדריך המשתמשת ב-TensorFlow 2 לחצו על הקישור רגרסיה קווית באמצעות TensorFlow
רגרסיה לינארית משמשת למציאת הקשר בין נתונים מספריים. במדריך זה נמצא את המתאם (קורלציה) בין שטח בית ומחירו באמצעות למידת מכונה ובעזרת ספריית Keras. הנתונים במדריך נלקחו ממסד נתונים של בתים שנמכרו במדינת סקרמנטו בארה"ב.
לחץ להורדת הקוד שאותו נפתח במדריך
![]()
תזכורת לגבי מודל לינארי
מודל לינארי הוא קו ישר בתוך מערכת צירים. מאפייני המודל הליניארי הם שניים: שיפוע ונקודת חיתוך עם ציר ה-Y. זו משוואת הקו הישר.
Y = m*X + B
- m - שיפוע הקו הישר
- B - נקודת החיתוך עם ציר ה - Y

משוואת הקו הישר מתאימה ערך של Y לכל ערך של X.
המשתנה שאותו אנחנו מנסים לחזות נמצא על ציר ה-Y. הוא המשתנה התלוי. במקרה שלנו, ננסה למצוא את המחיר.
על ציר ה-X נמצאים המשתנים הבלתי תלויים (הפיצ'רים). לדוגמה, שטח הדירה.
המשוואה :
Y = m*X + B
מתאימה לתיאור של פיצ'ר אחד. לדוגמה, מחיר על פי שטח הדירה.
כשיש לנו שני פיצ'רים (שני משתנים בלתי תלויים), לדוגמה שטח וגם מספר חדרים, נוסיף ציר z, ואז משוואת הקו הישר תראה כך:
Y = m1*X + m2*Z + B
כל פיצ'ר מתייחס לציר אחד ומצויד בשיפוע משלו.
המודל שאנו מפתחים הוא משוואת הקו הישר.
המטרה שלנו באימון המודל היא למצוא קו ישר המתאר את הנתונים באופן הטוב ביותר. התיאור הטוב ביותר הוא כאשר ההפרש בין המחיר הצפוי ע"י המודל ובין הערך בפועל הוא הקטן ביותר.
אחרי שנמצא את המודל (משוואת הקו הישר) נציב לתוכו נתונים של דירות ונעריך עד כמה התחזיות דומות לנתונים בפועל.
ייבוא הספריות שישמשו במדריך
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt- ספריית Numpy של Python מאפשרת לעבוד עם מערכים רב-ממדיים, ומספקת פונקציות לביצוע פעולות של אלגברה לינארית הנדרשות לפתרון הבעיות המתמטיות בתהליך הלמידה.
- Pandas משמשת לסידור ולסינון מידע בדומה לגיליון אקסל.
- Matplotlib משמשת להצגת מידע בגרפים.
ייבוא מסד הנתונים
מסד הנתונים המשמש במדריך מסכם את מחירם של בתים שנמכרו בסקרמנטו. תוכלו להוריד אותו מכאן.
df = pd.read_csv('../data/sacramentorealestatetransactions.csv',usecols=['sq__ft', 'price'])במדריך זה נשתמש רק בעמודת שטח הבית (sq__ft) והמחיר.
סקירת הנתונים וניקוי דוגמאות חריגות
נסקור את הנתונים לפני שנכנס לתהליך הלמידה כדי להימנע מהפתעות בהמשך:
# See the database before doing anything
df.set_index('sq__ft')
df.shape(985, 2)
התוצאה היא שני טורים ו-985 שורות.
נדפיס את המידע על עמודות מסד הנתונים באמצעות:
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 985 entries, 0 to 984 Data columns (total 2 columns): sq__ft 985 non-null int64 price 985 non-null int64 dtypes: int64(2) memory usage: 15.5 KB
מספר שווה של נתונים ועמודות הכוללות נתונים מספריים. בדיוק מה שאנחנו צריכים בשביל קורלציה.
נוודא שלא חסרים נתונים:
df.isnull().sum().sum()0
התוצאה היא 0, ולכן לא חסרים נתונים.
נתאר את מדדי מרכז באמצעות:
df.describe()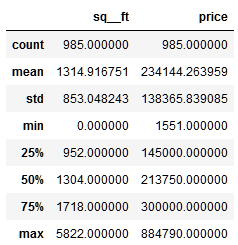
ועכשיו נמצא את מידת הקורלציה בין שטח הבית והמחיר:
# Find the correlation
df.corr()['sq__ft'].sort_values()price 0.333897 sq__ft 1.000000 Name: sq__ft, dtype: float64
קורלציה נמוכה של 33% בלבד בניגוד לציפייה שלנו שיהיה קשר חזק יותר בין גודל הבית ומחירו. למה?
נציג את הנתונים בגרף וננסה להבין מה מקור השיבוש:
plt.plot(df['sq__ft'], df['price'], 'o')
plt.ylabel('Price')
plt.xlabel('Square foot')
plt.title('Price vs square foot')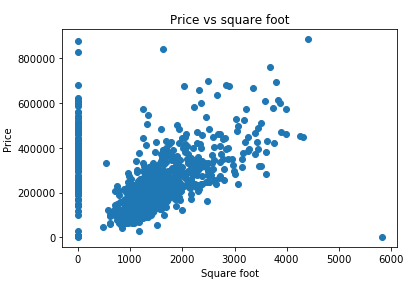
לא כל הנתונים סבירים. לדוגמה, מקרים שבהם שטח הדירה אפסי או נתון חריג בעלת שטח דירה גדול במיוחד ומחיר נמוך בצורה יוצאת דופן. נסנן אותם כדי שלא יפריעו למציאת המתאם בין שטח ומחיר הדירה.
# Remove outliers
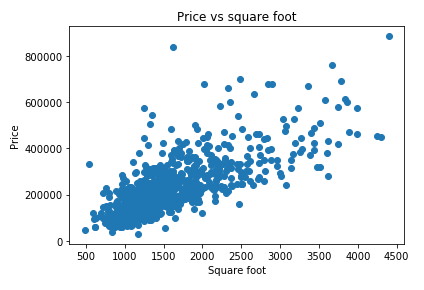
filtered_data = df[(df.sq__ft > 10) & (df.sq__ft < 5000)]נמצא את הקורלציה בסט הנתונים לאחר הסינון:
filtered_data.corr()['sq__ft'].sort_values()price 0.728642 sq__ft 1.000000 Name: sq__ft, dtype: float64
ואכן המתאם גבוה משמעותית יותר ועומד על 72.8%.
נשרטט את סט הנתונים לאחר הסינון:
למידת מכונה באמצעות Keras
נייבא את הספריות שישמשו אותנו לצורך למידת המכונה:# Import the libraries for the machine learning
from keras.models import Sequential
from keras.layers import Dense, Activation
from keras.optimizers import Adam
from keras.callbacks import EarlyStopping
from sklearn.model_selection import train_test_splitהמודל מבצע למידת מכונה באמצעות שכבות של נוירונים. Keras משתמש במודל מסוג Sequential שעורם שכבות של נוירונים זו על גבי זו כשלכל שכבה יש input, output.
יש רק שכבה אחת במודל כי זה לא מודל עמוק אלא רדוד.
את האופטימיזציה נעשה בשיטת Adam. אופטימיזציה היא התהליך שמעדכן את הפרמטרים W (שיפוע הישר) ו-B (נקודת החיתוך עם ציר ה-y) במטרה לצמצם כמה שניתן את מידת השגיאה.
נגדיר את המודל:
model = Sequential()
# Convert the value from the input (square foot) to the output (price)
# The model receives 1 input and outputs a single value
model.add(Dense(1, input_shape=(1,)))
# We expect the model to be linear
model.add(Activation('linear'))- השכבה Dense פולטת output (y) אחד עבור כל ערך input (x) שהיא מקבלת. עבור כל ערך יחיד של שטח דירה השכבה תפלוט מחיר אחד.
input_shape=(1,)מכיוון שהמודל יכול לקבל ריבוי של x עבור ערכי y שהוא מיועד לפלוט.- שכבת האקטיבציה היא לינארית כיוון שאנחנו מצפים לקשר לינארי. ככל שהבית גדול יותר כך יעלה המחיר.
הפונקציה הבאה מסכמת את המודל:
model.summary()Layer (type) Output Shape Param # ============================================== dense_2 (Dense) (None, 1) 2 ______________________________________________ activation_2 (Activation) (None, 1) 0 ============================================== Total params: 2 Trainable params: 2 Non-trainable params: 0
- צורת ה-output היא 2 כיוון שהתוצאה של המודל היא שני הפרמטרים שיפוע ונקודת החיתוך עם ציר ה-y.
נקמפל את המודל באמצעות TensorFlow מכיוון שזו ברירת המחדל שבה משתמש Keras:
# Adam optimizer with learning rate of 10 (After some triabl and error I find it to be the best learning rate)
model.compile(Adam(lr=10), loss='mean_squared_error')מטרת תהליך הלמידה היא להגדיל את מידת הדיוק של המודל. המדד להתקדמות תהליך הלמידה (מכונה cost function או loss) הוא באמצעות mean_squared_error. גודל הצעדים שהתהליך יעשה בכל חזרה הוא 10 (learning rate) כי זה הערך שנותן את מידת הדיוק הגבוה ביותר כפי שגיליתי בניסוי מקדים שערכתי לפני שכתבתי את המדריך (אתם יכולים לנסות למצוא ערך טוב יותר על ידי שינוי גודל הצעד.
נגדיר את ערכי ה-X וה-y:
X = filtered_data[['sq__ft']].values
y = filtered_data['price'].valuesנפצל את הדוגמאות לקבוצת אימון (train) ומבחן (test):
# Split the data to test and train group
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)פונקציית EarlyStopping תעצור את תהליך הלמידה במידה ואינו מתקדם. השאלה היא באיזה שלב לעצור את תהליך הלמידה כי אם נריץ מספר נמוך מדי של epochs התחזיות של המודל לא יהיו טובות כי המערכת לא למדה מספיק, ואם נריץ יותר מדי פעמים המערכת תתקשה להכליל היות שהיא למדה יותר מדי טוב את הנתונים ששימשו לאימון המודל ולפיכך תתקשה להסיק מהנתונים שעליהם היא התאמנה לנתונים אחרים שהיא לא ראתה. התשובה היא הקצאת חלק מהדוגמאות לקבוצת ביקורת, והשוואת מידת הדיוק של קבוצת הביקורת עם קבוצת הנתונים המשתמשים לאימון המודל בכל epoch. במידה ודיוק המודל עבור קבוצת הדוגמאות המשמשות ללימוד היא גבוהה משמעותית יותר מקבוצת הביקורת נראה שהמודל למד יותר מדי וזה הזמן לעצור. כשאנחנו עובדים עם Keras אנחנו משתמשים בפונקציה EarlyStopping כדי לעצור את תהליך הלמידה בדיוק בזמן.
# The EarlyStopping callback stops the learning process if the loss doesn't improve
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=2,
verbose=2,
mode='auto')המדד שאחריו אנחנו עוקבים הוא loss ואחרי שני סיבובים, epochs, שהמדד לא מתקדם תהליך הלמידה יעצור. השם שאנחנו נותנים לערך המנוטר עבור דוגמאות הביקורות הוא val_loss כדי להבחין בין המדד עבור קבוצת הדוגמאות שמהם המודל לומד (שם המדד מכונה loss) לבין הדוגמאות שאנחנו שומרים בצד. בשני המקרים תהליך הלמידה עוקב אחרי המדד loss. רק השם שונה.
אחרי כל ההכנות, הפונקציה הבאה עושה את הלמידה בפועל:
# The training in which tensorflow finds the optimal parameters is done here
model.fit(X_train,
y_train,
batch_size=32,
epochs=200,
validation_data=(X_test,y_test),
callbacks=[es])
loss הוא הערך שהשיפור בו מודד את מידת ההתקדמות של תהליך הלמידה עבור קבוצת הלמידה, ו val_loss עושה את אותו דבר עבור דוגמאות הביקורת. בסוף כל epoch התוכנה חוזרת לדוגמאות הביקורת עם המודל ומעריכה את מידת ההתקדמות על קבוצת הביקורת.
נשרטט את התחזית שהפיק תהליך הלמידה (y_pred) כנגד הנתונים בפועל (X):
plt.plot(filtered_data['sq__ft'], filtered_data['price'], 'o')
plt.ylabel('Price')
plt.xlabel('Square foot')
plt.title('Price vs square foot')
plt.plot(X,y_pred,color='red')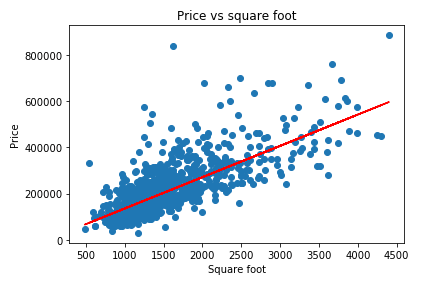
הקו האדום הם הערכים שהמודל חוזה המתוארים באמצעות קו ישר.
נראה את הפרמטרים של משוואת הקו הישר שהמודל מצא:
# Print the parameters that the process found
W, B = model.get_weights()W הוא שיפוע הקו
# Weight is the slope of the line
Warray([[ 144.62713623]], dtype=float32)
B היא הנקודה שבה הקו חוצה את ציר ה-y
# The bias is the point at which the line crosses the y-axis
Barray([ 158.30099487], dtype=float32)
סיכום
במדריך זה למדנו להשתמש במודל פשוט של -Keras כדי למצוא קורלציה בין שני גדלים, גודל דירה ומחיר.
קיימות שיטות פשוטות יותר למציאת רגרסיה לינארית מאשר למידת מכונה אבל אותנו מעניין ללמוד והדוגמה במדריך היא הפשוטה ביותר שאני יכול לחשוב עליה. הכוח והיופי של למידת מכונה שניתן להגיע לפתרון שאלות מורכבות הכרוכות בהבנת היחסים בין ריבוי של שחקנים, כפי שנלמד במדריכים הבאים בסדרה.
למרות שלא נכנסתי לזה במדריך הנוכחי אחרי שאנחנו מוצאים את המודל הליניארי חשוב לוודא שהוא אכן מתאר את הנתונים באופן משמעותי כי יכול להיות שנמצא קשר אבל הוא לא יהיה משמעותי בגלל סיבות שונות, ובהם גודל מדגם קטן מדי או מספר גדול מדי של משתנים בלתי תלויים.
כדי לבחון האם המודל מצליח לתאר את הנתונים משתמשים ב-R² שאומר לנו איזה חלק של השונות בנתונים מצליח להסביר המודל. במידה והמודל לא מתאר בכלל את הנתונים אז הערך של R² יהיה אפס או אפילו שלילי. ככל שהמודל מצליח להתאים יותר לנתונים כך הערך של R² יהיה גבוה יותר. במידה והמודל מתאר בצורה מדויקת את הנתונים הערך של R² יהיה 1.
הבעיה עם R² שאנחנו יכולים לקבל ערכים גבוהים שלו למרות שהמודל שלנו לא מוצלח. לדוגמה, דרך 2 נקודות ניתן להעביר משוואת ישר אחת בלבד, ולכן R² עבור מודל המבוסס על 2 דוגמאות יהיה 1, אבל בפועל המדגם קטן מכדי שנוכל ללמוד ממנו על העולם. בעיה אחרת היא שככל שישנם יותר משתנים בלתי תלויים (צירי X) כך ה-R² עלול לגדול כי במקרה הטוב הפרמטרים שלא מתארים בכלל את המודל לא יוסיפו ל-R², ובמקרה הרע הם יגרמו לו להיות גבוה יותר.
כדי לפתור את הבעיות עם R² משתמשים בערך P כדי לבדוק האם המודל שלנו משמעותי. לצורך חישוב p-value לוקחים בחשבון את השונות (כמו R²) ובנוסף את גודל המדגם ואת מספר המשתנים. ככל שכמות הדוגמאות גדולה יותר ומספר המשתנים נמוך יותר כך נקבל ערכי P טובים יותר. ערכי P נעים בין 0 ל-1. ככל שהם שואפים ל-0 כך התוצאות משמעותית יותר. מקובל שערכים נמוכים מ-0.05 נחשבים למשמעותיים כי הם מבטאים סיכוי של 5% שהתוצאה היא אקראית.
בקובץ הבא תוכלו למצוא את כל הקוד של המדריך ותוספות חשובות הכוללות R² ו-p-value עבור המודל שמצאנו במדריך כמו גם השוואת ביצועי המודל שלנו למודלים של ספריות ידועות בתחום לחץ להורדת הקובץ.
במדריך הבא נמשיך בפיתוח המול ונרחיב אותו כדי שיכלול מספר משתנים כמותיים.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.