
בחירת הרכב המודלים ללמידת מכונה באופן אוטומטי על ידי ספריית Auto Sklearn
אתה מכיר את הנושא של למידת מכונה? כבר השתמשת בבינה מלאכותית לפתרון בעיות? אבל שברת את הראש באילו מודלים להשתמש ובאילו פרמטרים. אם זה אתה. אז כדאי שתכיר את תחום האוטומציה של למידת מכונה - חבילות קוד שבוחרות בשבילך את הרכב ensemble המודלים והפרמטרים המתאימים ביותר לביצוע המשימה שעל הפרק. במדריך זה, נכיר את auto-sklearn - ספרייה שמרכיבה למענך אנסמבל אלגוריתמים המספק את התוצאות הטובות ביותר.

מסד הנתונים
אחד ממסדי הנתונים הקלאסיים בהם משתמשים בלמידת מכונה הוא ה-iris dataset. השאלה שהוא מציג היא כיצד לסווג ל-3 זנים של אירוסים על פי אורך ורוחב עלי הכותרת. נשתמש במסד הנתונים כדי להדגים מציאת הרכב אלגוריתמים מסווג classifier בעזרת ספריית auto-sklearn.

את מסד הנתונים iris dataset הכולל 150 דוגמאות של שלושה זני אירוסים ייבאתי מ- archive.ics.uci.edu/ml/datasets/iris. כל רשומה כוללת את שם הזן, ואת אורך ורוחב עלי הכותרת.
להורדת המחברת עליה מתבסס המדריך
יבוא התלויות
נייבא את 4 הספריות הבסיסיות הבאות תוך שנקפיד על התקנת הגרסה הישנה של pandas:
!pip3 install 'pandas==0.25.3' --force-reinstall
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')- Numpy מקלה את העבודה עם מערכים רב-מימדיים.
- Pandas משמשת לסידור ולסינון המידע בדומה לגיליון אקסל.
- Matplotlib ליצירת גרפים.
- Seaborn מתבססת על Matplotlib, ומקלה על יצירת גרפים מתקדמים.
את המדריך פיתחתי בסביבת Colab המאפשרת לבצע למידת מכונה על השרתים של גוגל בחינם.
ספריית auto-sklearn בוחרת באופן אוטומטי הרכב ensemble של אלגוריתמים ופרמטרים לפתרון הבעיה. נתקין את הספרייה על פי המוסבר בתיעוד הרשמי של הספרייה:
!sudo apt-get install build-essential swig
!curl https://raw.githubusercontent.com/automl/auto-sklearn/master/requirements.txt | xargs -n 1 -L 1 pip3 install
!pip3 install auto-sklearn
from autosklearn.classification import AutoSklearnClassifierנייבא תלויות נוספות:
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
import pickle- הפונקציה train_test_split תפצל את מסד הנתונים לקבוצת אימון ובקרה.
- הפונקציות accuracy_score ו- confusion_matrix ישמשו להערכת דיוק המודל.
- נייצא את הרכב המודלים והפרמטרים הטוב ביותר לקובץ pickle לשימוש בסביבת ייצור.
יבוא סט הנתונים ועיבוד מקדים
בניגוד לספריות אחרות, auto-sklearn כמעט ולא עושה עיבוד מקדים preprocessing של הנתונים מלבד one hot encoding. מדריך זה אני לא נכנס לעומק של הכנת סט הנתונים כיוון שאת רוב הצעדים אני משחזר על פי מה שעשיתי במדריך "סיווג לקבוצות באמצעות למידת מכונה".
נייבא את סט הנתונים:
# Load the dataset to panda's dataframe
df = pd.read_csv('iris.data')4 העמודות הראשונות מכילות את מדידות האורך והרוחב של עלי הכותרת. על פיהם ננסה לסווג את זן הפרח המופיע בעמודה החמישית:
x = df.iloc[:,:4]
y = df.iloc[:,4]כיוון ש auto-sklearn מתקשה לעבוד עם ערכים טקסטואליים נמפה את שמות הזנים לערכים מספריים:
species_names = y.unique()
species_namesהתוצאה:
array(['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'], dtype=object)
# map the labels to numbers
dct = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
y_cat = y.replace(dct)מעכשיו ועד להערכת ביצועי המודל במקום ב-y, שמות הזנים, נשתמש ב-y_cat, הערכים המספריים, שהם:
y_cat.unique()array([0, 1, 2])
נפצל את הדוגמאות לקבוצת אימון ובקרה:
# Split into train and test groups
x_train, x_test, y_train, y_test = train_test_split(x, y_cat, test_size=0.5, random_state=42)
למידת מכונה אוטומטית באמצעות auto-sklearn
הפונקציה AutoSklearnClassifier בוחרת באופן אוטומטי את הרכב ensemble האלגוריתמים והפרמטרים המתאים ביותר לסיווג. אחרי שאנו מגדירים אותה נשתמש בפונקציה fit למציאת המודל ולביצוע הסיווג:
automl = AutoSklearnClassifier(
time_left_for_this_task=240,
per_run_time_limit=60
)
automl.fit(x_train, y_train, dataset_name='iris')AutoSklearnClassifier מקבלת מספר פרמטרים:
- time_left_for_this_task - מספר השניות לביצוע המשימה כולה
- per_run_time_limit - זמן הריצה המקסימלי של כל אחד מהאלגוריתמים
- include_estimators - רשימה של אלגוריתמים שהמודל צריך לבחון (אם ריק אז בוחן את כולם)
- exclude_estimators - רשימת אלגוריתמים שאין להכליל במודל
- פרמטרים נוספים מתוארים בתיעוד.
הפונקציה fit בוחנת הרכבים שונים של מודלים ועושה את הסיווג בפועל על סט האימון.
התוצאות
הפונקציה sprint_statistics מציגה סטטיסטיקות של סט האימון:
automl.sprint_statistics()auto-sklearn results: Dataset name: iris Metric: accuracy Best validation score: 1.000000 Number of target algorithm runs: 88 Number of successful target algorithm runs: 87 Number of crashed target algorithm runs: 1 Number of target algorithms that exceeded the time limit: 0 Number of target algorithms that exceeded the memory limit: 0
- לדוגמה, מה מידת הדיוק המקסימלית באימון, כמה אלגוריתמים המודל הריץ. כמה אלגוריתמים הוא הספיק לסיים (רק 87 מתוך 88 עקב מגבלת הזמן).
הספרייה מוצאת אנסמבל של מודלים שפותר את הבעיה. מהו הרכב המודלים?
automl.show_models()התוצאה היא רשימה ארוכה ולא בהכרח מובנת של מודלים שפותרים ביחד את הבעיה. זה האנסמבל אותו נייצא לשימוש עתידי בסוף המדריך.
כדי לקבל תחושה אודות הרכב המודלים שהתהליך מצא, נברר איזה מודל עשה את העבודה הטובה ביותר:
automl.cv_results_['params'][np.argmax(automl.cv_results_['mean_test_score'])]{'balancing:strategy': 'weighting',
'classifier:__choice__': 'lda',
'classifier:lda:n_components': 220,
'classifier:lda:shrinkage': 'auto',
'classifier:lda:tol': 0.0013824567992319003,
'data_preprocessing:categorical_transformer:categorical_encoding:__choice__': 'one_hot_encoding',
'data_preprocessing:categorical_transformer:category_coalescence:__choice__': 'minority_coalescer',
'data_preprocessing:categorical_transformer:category_coalescence:minority_coalescer:minimum_fraction': 0.00021328932075284388,
'data_preprocessing:numerical_transformer:imputation:strategy': 'mean',
'data_preprocessing:numerical_transformer:rescaling:__choice__': 'minmax',
'feature_preprocessor:__choice__': 'nystroem_sampler',
'feature_preprocessor:nystroem_sampler:coef0': 0.039972474835314076,
'feature_preprocessor:nystroem_sampler:gamma': 0.01017810882899714,
'feature_preprocessor:nystroem_sampler:kernel': 'sigmoid',
'feature_preprocessor:nystroem_sampler:n_components': 295}
- אלגוריתם lda עשה את העבודה הטובה ביותר.
בחינת המודל
נבחן את יכולות האנסמבל על ידי סיווג דוגמאות הבקרה:
# Get the Score of the final ensemble
predictions = automl.predict(x_test)מה מידת הדיוק?
acc_test = accuracy_score(y_test, predictions)
print(f"Accuracy score: {acc_test}")Accuracy score: 0.9733333333333334
- דומה לביצועי המודל על דוגמאות האימון.
הבעיה עם מדידת דיוק accuracy שההערכה היא כללית. על פני כל הקבוצות. כדי לברר אילו שגיאות המודל עשה נשתמש ב- Confusion matrix.
cf_matrix = confusion_matrix(y_test, predictions)
print(cf_matrix)התוצאה:
[[29 0 0] [ 0 23 0] [ 0 2 21]]
עלולה לבלבל אז אשתמש במפת חום:
ax= plt.subplot()
sns.heatmap(cf_matrix, annot=True, ax = ax, fmt='d', cmap='Blues', cbar=False)
# labels, title and ticks
ax.set_title('Confusion Matrix')
ax.set_xlabel('Predicted labels')
ax.set_ylabel('True labels')
ax.xaxis.set_ticklabels(species_names)
ax.yaxis.set_ticklabels(species_names)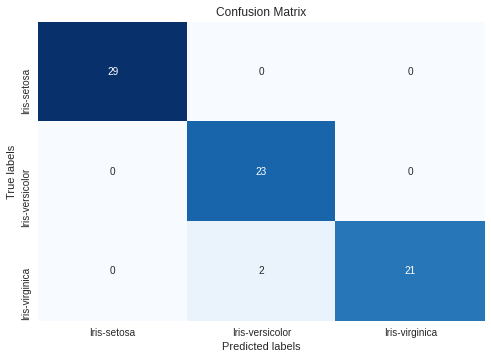
ייצוא המודל
אחרי שספריית AutoSklearn מצאה הרכב של מודלים לפתור את הבעיה שמעניינת אותנו, כדאי לשמור את ההרכב לשימוש עתידי. נייצא את ההרכב לקובץ pickle לשימוש בעתיד:
# export the ensemble of models to be deployed in the pipeline
import pickle
x = automl.show_models()
results = {'ensamble': x}
pickle.dump(results, open('iris.pickle','wb'))
סיכום
AutoSklearn היא ספרייה שמוצאת בשבילנו את הרכב ensemble המודלים הטוב ביותר לצורך למידת מכונה מתוך האלגוריתמים של sklearn. במדריך זה הדגמתי את היכולות לאיתור מודלים מסווגים, וניתן להשתמש באותה הספרייה גם לצורך מציאת רגרסיה, כפי שמסביר התיעוד הרשמי.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.