
20 פעולות שאתה חייב להכיר כשאתה עובד עם Pandas של Python
Pandas היא ספרייה של Python המשמשת לניתוח של מידע. במדריך זה ריכזתי עבורכם את המושגים והפקודות השימושיים ביותר.

המושגים הבסיסיים
Data Frame - מידע שמסודר בעמודות ושורות. בדומה למסד נתונים SQL, SPSS או גליון אקסל.
Series - עמודה אחת ב-Data Frame.
1. כיצד לייבא את pandas?
import pandas as pd
2. כיצד לייבא קובץ csv?
במדריך אני משתמש בקובץ cars.csv, שאותו אתם יכולים להוריד מכאן: להורדה.
כדי לקרוא את הקובץ:
df = pd.read_csv('cars.csv')כדי לקרוא רק חלק מהעמודות:
df = pd.read_csv('cars.csv', usecols=['model', 'price', 'description'])כדי לעשות parsing של עמודות התאריכים:
df = pd.read_csv('cars.csv', parse_dates=['date'])parse_date מקבל מערך של שמות העמודות.
3. כיצד להתמודד עם מידע חסר?
פעמים רבות מה שחסר אילו הם שמות העמודות או שנרצה לשנות את השמות. לשם הגדרת שמות העמודות נגדיר את התכונה `columns` של ה-DataFrame. לדוגמה:
df.columns = ['model', 'price', 'description', 'date']
תוכנות סטטיסטיות, ובייחוד למידת מכונה, מתקשות להתמודד עם נתונים חסרים. לכן, כדאי לאתר ולנקות את הנתונים החסרים.
נתחיל מזיהוי הנתונים החסרים.
לספירת מספר ה-NaN בכל סט הנתונים:
df.isnull().sum().sum()למציאת מספר ה-NaN לפי עמודות:
df.isnull().sum()model 0 price 4 description 0 date 0 dtype: int64
במידה וחסרים ערכים ניתן להשלים אותם, לדוגמה, אם חסר מידע בתאים בעמודת price נשלים אותו ל-0.
df.price = df.price.fillna(0)את הערכים החסרים ניתן להשלים באמצעות החציון.
med = df.price.median()
df.price = df.price.fillna(med)אפשרות נוספת להתמודדות עם בעיית המידע החסר היא למחוק את כל השורות שחסר בהם מידע.
df = df.dropna(axis=0)
4. כיצד להמיר את סוג הנתונים בעמודות?
כשרוצים להמיר את העמודה price לסוג נתונים int:
df.price = df.price.astype('int')אפשר גם לסוג float.
ומועיל במיוחד הוא הפיכה לסוג datetime.
df.date = pd.to_datetime(df.date)
5. כיצד לקבוע את עמודת האינדקס?
pandas מאנדקס את סט הנתונים לפי סדר השורות החל מ-0 ועד למספר השורות בסט. כדי להגדיר את האינדקס על עמודה אחרת, לדוגמה, עמודת date:
df.set_index('date', inplace=True)- inplace=True כדי שישנה את ה-data frame הקיים במקום ליצור אוביקט חדש. אם לא היינו משתמשים בזה אז היינו צריכים להציב את האובייקט החדש חזרה כדי ש-df אכן ישתנה. כך עושים את זה ללא ה-inplace:
df = df.set_index('date')נשתמש ב-reset_index כדי להחזיר את האינדקס המקורי.
df.reset_index(inplace=True)
6. כיצד לסקור את המידע ב-Data Frame?
כדי להציץ ב-5 השורות הראשונות של ה-data frame:
df.head()
ניתן להציץ במספר שונה של שורות, לדוגמה 10 שורות:
df.head(10)אפשר לבחור לראות רק השורות האחרונות של סט הנתונים:
df.tail()ואפשר לראות מספר שורות אקראיות:
df.sample(10)כדי לצפות במספר השורות והעמודות:
df.shape(59, 4)
כדי לראות נתונים סטטיסטיים כלליים על ה-data frame:
df.describe()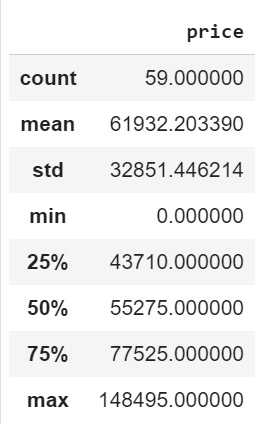
וכדי לראות סוג הנתונים בעמודות:
df.info()RangeIndex: 59 entries, 0 to 58 Data columns (total 4 columns): model 59 non-null object price 59 non-null int64 description 59 non-null object date 59 non-null datetime64[ns] dtypes: datetime64[ns](1), int64(1), object(2) memory usage: 1.9+ KB
df.info מראה את סוג הנתונים (object למחרוזת), שם העמודה ואת מספר הנתונים בכל עמודה.
7. כיצד להוסיף עמודה ל-data frame?
נוסיף את העמודה sold, ונציב את הערך True בכל אחד מהתאים:
df['sold'] = Trueכדי להוסיף עמודה במקום מסוים נציין את מספר האינדקס של העמודה. לדוגמה, עמודה ששמה convertible (גג נפתח) בתור העמודה הראשונה (אינדקס 0).
df.insert(0, 'convertible', True)
9. כיצד להסיר עמודות?
ניתן להסיר רשימה של עמודות באמצעות drop:
df.drop(['convertible','sold'], axis=1, inplace=True)- axis=1 - כי אנחנו מעוניינים להסיר עמודות (ולא שורות).
- inplace=True - כדי לשנות את הdata frame עצמו במקום ליצור אובייקט חדש.
9. כיצד להוסיף תנאים פשוטים לסט הנתונים?
בדוגמה זו נוסיף עמודה expensive המכילה ערכים בוליאניים. במידה והמחיר גבוה מ-90000 הערך יהיה True.
כדי שזה יעבוד נשתמש במתודה where של ספריית numpy.
import numpy as np
df['expensive'] = np.where(df['price']>=90000, True, False)
10. כיצד לחלק את הנתונים לקבוצות?
בדוגמה זו אנחנו מעוניינים לחלק את הנתונים ל-3 קבוצות לפי מחיר:
bins = [0, 40000, 60000, 200000]
names = ['Cheap', 'Medium', 'Expensive']
df['price_point'] = pd.cut(df.price, bins, labels=names)בתהליך יצרנו עמודה חדשה price_point שמכילה את התגיות עם שמות רמות המחיר.
נבדוק את השינוי שעשינו:
df.price_point.value_counts()Expensive 24 Medium 24 Cheap 7 Name: price_point, dtype: int64
11. כיצד להפעיל פונקציה על עמודה?
כדי להפעיל פונקציה על עמודה משתמשים במתודה apply:
def get_company(s):
if s.find('BMW') > -1:
return 'BMW'
elif s.find('Audi') > -1:
return 'Audi'
else:
return 'Unknown'
df['company'] = df.model.apply(get_company)במקרים רבים, נסתפק בפונקציה אנונימית:
df['company'] = df.model.apply(lambda x: 'BMW' if x.find('BMW') > -1 else 'Mercedes')הטריק הבא יכול לעזור עם עמודות המערבות סימנים ומספרים:
df['real_price'] = df.price.apply(lambda x: '$' + str(x))
במקרים מסוימים נרצה להחליף רשימה של ביטויים באחרים. לשם כך, אפשר להשתמש במילון אותו מעבירים לפונקציה replace():
# Define a dictionary for replacements
replace_dict = {'BMW': 'B.M.W.', 'mercedes': 'Mercedes', 'tesla': 'Tesla'}
# Replace values in the 'company' column
df['company'] = df['company'].replace(replace_dict)
12. כיצד לעבוד עם תאריכים?
מתחילים מהמרת המידע בעמודה לסוג datetime , ואז משתמשים בתכונות של dt.
לדוגמה, פונקציה שממירה תאריך סטנדרטי ל"ישראלי":
def to_israeli_date(d):
date = d.to_pydatetime()
day = date.day
month = date.month
year = date.year
return '%s.%s.%s' % (day, month, year)
df['israeli_date'] = df.date.apply(to_israeli_date)
13. loc - בחירה באמצעות תגיות
המתודה loc מאפשרת לבחור שורות לפי האינדקס ועמודות לפי שם העמודה.
נבחר תא אחד מסוים. שורה לפי האינדקס, ועמודה ע"פ השם.
df.loc[2,'model']נבחר שורה לפי האינדקס:
df.loc[2, :]נבחר מספר שורות לפי האינדקס:
df.loc[[2, 3, 5], :]טווח של שורות ע"פ האינדקס:
df.loc[2:5, :]וניתן לחצות את סט הנתונים, לדוגמה, עד שורה 10 ומשורה 10:
train = df.loc[:10]
test = df.loc[10:]
עמודה נבחרת עבור טווח של אינדקסים:
df.loc[0:2, 'model']בחירה הכוללת טווח של אינדקסים בתוך רשימה של עמודות:
df.loc[0:2,['model', 'description']]בחירה הכוללת טווח של אינדקסים בתוך טווח של עמודות:
df.loc[0:2,['model':'description']]
ל-loc ניתן להעביר לוגיקה פשוטה:
df.loc[df.model=='BMW']ולקבל עמודה מסוימת בלבד:
df.loc[df.model=='BMW', 'price']
14. iloc - בחירה באמצעות אינדקסים
המתודה iloc מאוד דומה ל-loc. תפקידה לבחור נתונים על סמך מיקומם בטבלה - אינדקס השורות והעמודות. לכן היא מקבלת רק מספרים בתור פרמטר.
שורות 2-4 עם 4 העמודות הראשונות:
df.iloc[2:5, :4]כל השורות עם העמודה הרביעית בלבד:
df.iloc[:, 3]
15. כיצד להפעיל לוגיקה לסינון הנתונים?
נאמר שאנחנו מעוניינים לסנן את השורות שבהם המחיר גבוה מ-3000
filtered_data = df[df.price > 30000]ניתן לבצע לוגיקה מורכבת יותר באמצעות & או |
filtered_data = df[(df.price > 30000) & (df.price <= 40000)]
filtered_data = df[(df.price < 300000) | (df.model == 'BMW')]הפקודה isin מאפשרת לסנן אם מתקיים אפילו אחד מהתנאים:
filtered_data = df.loc[df['model'].isin(['The Audi A3', 'Audi', 'Ferrari'])]
16. כיצד לקבל את הנתונים הייחודיים בלבד של עמודה?
כדי לקבל את הנתונים הייחודיים בעמודה משתמשים ב-unique:
df.company.unique()array(['BMW', 'Audi'], dtype=object)
17. כיצד לסדר את השורות בהתאם לעמודה מסוימת?
הפקודה sort_values משמשת לסידור סט הנתונים לפי עמודה (בסדר יורד או עולה):
df.sort_values('price', ascending=True)נסדר לפי 2 עמודות:
df.sort_values(['price','model'], ascending=[True,False])
18. כיצד לחבר data frames?
ניתן לחבר data frames כל עוד המבנה הוא זהה.
כדי לחבר את השורות אנכית (אחת מעל לשנייה):
pd.concat([df_1, df_2], axis=0)כדי לחבר את השורות אופקית:
pd.concat([df_1, df_2], axis=1)אפשרות נוספת היא לחבר על בסיס של עמודה משותפת כמו JOIN ב-SQL.
merged_df = pd.merge(df_1, df_2, how='inner', on='unique_id')- העמודה המשותפת היא unique_id היא מכילה את הערכים (המפתחות) לפיהם מצורפות העמודות.
מילת המפתח how היא לפי סוג הצירוף (join):
- inner - חיתוך ה-data frames והשארת השורות בעלות המפתחות המשותפים.
- outer - ה-data frame שיווצר יכיל את כל השורות וערכים חסרים יקבלו NaN.
- left - יכלול מפתחות רק מה-data frame השמאלי.
- right - יכלול מפתחות רק מה-data frame הימני.
19. כיצד למצוא קורלציה?
כדי למצוא את הקורלציה בין עמודות שמכילות סט נתונים המשכי (גובה, מחיר):
df.corr()['price'].sort_values()
20. כיצד לקחת רק חלק מהעמודות?
כדי להגדיר את סט הנתונים רק על חלק מהעמודות:
df1 = df[['model', 'price']]
21. קיבוץ רשומות באמצעות groupby
המתודה groupby של pandas מאפשרת לנו לקבץ את הדוגמאות לקבוצות.
לדוגמה, אני מעוניין במחיר הממוצע של המכוניות לפי חברות:
df.groupby(['company']).mean()והתוצאה:
| company | price | expensive |
|---|---|---|
| Audi | 61499.310345 | 0.103448 |
| BMW | 69750.000000 | 0.233333 |
כדי להציג את הממוצע רק עבור העמודה price נגביל את ה-data frame לעמודות הרלוונטיות:
df[['company','price']].groupby(['company']).mean()| company | price |
|---|---|
| Audi | 61499.310345 |
| BMW | 69750.000000 |
כדי לקבץ לפי שתי עמודות company וגם expensive אנחנו רק צריכים להעביר למתודה groupby את רשימת העמודות:
df[['company','price','expensive']].groupby(['company','expensive']).mean()| company | expensive | price |
|---|---|---|
| Audi | False | 54299.230769 |
| True | 123900.000000 | |
| BMW | False | 55418.913043 |
| True | 116837.857143 |
ואם אנחנו רוצים את הממוצע של רכבים ששוויים גבוה מ-40,000?
df[df['price'] > 40000].groupby(['company','expensive']).mean()| company | expensive | price |
|---|---|---|
| Audi | False | 56869.782609 |
| True | 123900.000000 | |
| BMW | False | 59500.263158 |
| True | 116837.857143 |
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.