
כיצד להתגבר על overfitting במודלים מבוססי Keras?
במדריך זה נסביר מהו מודל שסובל מ-overfitting וכיצד להתמודד עם הבעיה.
מודל לוקה ב-overfitting אם הוא מתאים יותר לסט הדוגמאות שעליהם הוא אומן (training set) מאשר עם דוגמאות אחרות.
הבעיה מאוד נפוצה, ונוטה להופיע בשלבים שונים בתהליך האימון והפריסה (deployment) של המודל.
כבר במהלך אימון המודל ניתן להבחין ב-overfitting. אם אנחנו מודדים את מידת הדיוק (accuracy) ואנחנו רואים שהדיוק עבור דוגמאות האימון הוא פחות טוב מאשר עבור דוגמאות הווידוא. במדריך בחירת המודל המשמש ללמידת מכונה ראינו את המצב הזה קורה אחרי 4 epochs:
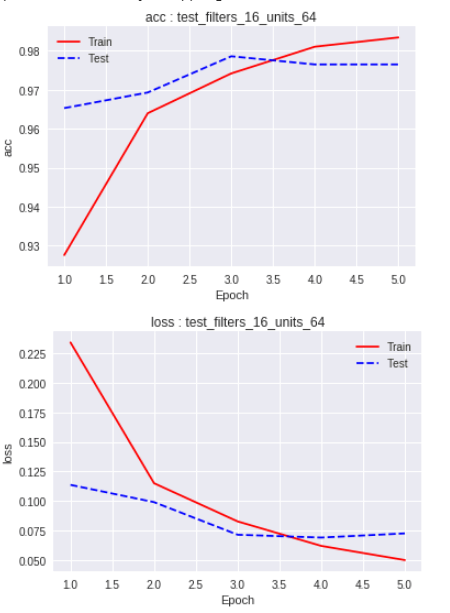
אנחנו עלולים להיתקל בבעיה גם בשלב שבו העברנו את המודל לשירות הלקוח כאשר אנחנו נוכחים שהמודל פחות מדויק עבור דוגמאות חדשות אליהם הוא לא נחשף במסגרת האימון.
מקור הבעיה בכך שהמודל לומד להתאים את עצמו לדוגמאות האימון בצורה יותר מדי טובה ומתקשה להכליל לדוגמאות שהוא לא נחשף אליהם.
כיצד להתמודד עם בעיית ה-overfitting?
קיימות 5 דרכים עיקריות להתמודד עם בעיית ה- overfitting:
1. הפיכת המודל לפשוט יותר
כשאנחנו מוסיפים למודל פרמטרים נלמדים - יותר שכבות ויותר יחידות בכל שכבה - אנחנו מגבירים את היכולת שלו ללמוד בצורה מדויקת את סט האימון. הדיוק מועיל עד לגבול מסוים שמעבר לו המודל מתאים יותר מדי לסט האימון ופחות מדי לסט המבחן, שזו אינדיקציה ל-overfitting. אחת הדרכים לפתרון הבעיה היא פישוט המודל. ובכלל כך, הפחתה במספר השכבות ובמספר היחידות בכל שכבה.
2. הוספת דוגמאות אימון לצורך הגדלת המגוון
ככל שאנחנו מגדילים את מספר הדוגמאות בסט האימון, המודל שלנו יכול ללמוד יותר, ולהפיק תחזיות טובות יותר בתנאי שמגוון הדוגמאות גדל. לדוגמה, אם המודל צריך להבחין בין כלבים וחתולים אז נוסיף כלבים מגזעים שונים, נשנה את רמות הבהירות ומידת הרווייה של צבע התמונות ונשחק בזוויות הצילום. למזלנו, קיימים כלים אוטומטיים שיכולים להגדיל את כמות הדוגמאות והמגוון שלהם, כפי שכתבתי במדריך הגדלת כמות התמונות ללמידת מכונה באמצעות data augmentation.
3. הוספת שכבת dropout
dropout מסירה באופן רנדומלי חלק מהיחידות בשכבה שעליה היא פועלת, וכתוצאה מכך הרשת הופכת לקטנה יותר, ולתלויה פחות בכל נוירון בודד.
בממשק keras מוסיפים פוקנצית Dropout בתור שכבה במודל מסוג Sequential:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout
model = Sequential()
# The model receives 1 input
model.add(Dense(12, activation='relu', input_shape=(1,)))
# A single hidden layer
model.add(Dense(36, activation='relu'))
# The dropout layer
model.add(Dropout(0.2))הפרמטר שמעבירים לפונקציה Dropout הוא שיעור היחידות שצריך להסיר באקראי. כדאי שהשיעור יהיה קטן כדי שהרשת תוכל ללמוד. מקובל להשתמש בערכים נמוכים שלא עולים על 0.5. ברוב הניסויים שערכתי, שיעור של 0.2 עשה את העבודה.
4. הוספת regularizers
regularizer מפחית את השונות בין המשקלים (weight) וה-bias בתוך הרשת הנוירונית. קיימים שני סוגי פונקציות: l1ו-l2. הפונקציה הנפוצה יותר בספרות היא l2.
את l2 מוסיפים כפרמטר לתוך שכבה קיימת:
from tensorflow.keras.regularizers import l2
….
# A layer with l2 regularization
model.add(Dense(36, kernel_regularizer=l2(0.001), activity_regularizer=l2(0.001), activation='relu'))- activity_regularizer פועל על היחידות החבויות (hidden units).
- akernel_regularizer פועל על המשקולות (weights).
- משתמשים יותר ב-activity_regularizer מאשר ב-kernel_regularizer.
- הפרמטר שהפונקציה מקבלת הוא המידה שבה צריך ליישם אותה alpha. הערכים יכולים להיות בין 0 ל-1. ערך 0 מבטל את הפונקציה. ערך של 1 גורם לפונקציה לפעול במלוא הכוח וגורם לתהליך האימון להיות לא יציב. מקובל להשתמש בערכים הנמוכים מ-0.1. לדוגמה, 1e-3 או 1e-4 כדי לרסן את פעולת הפונקציה ועדיין לאפשר לה להשפיע על התהליך.
5. הוספת שכבת batch normalization
כשאנחנו מכינים את הדוגמאות שלנו, אנחנו מצמצמים את הטווח שלהם באמצעות נורמליזציה. לדוגמה, בתמונות אפורות ערכו של כל פיקסל נע בין 0 ל-255, וכדי להקל על תהליך האימון אנחנו מחלקים את כל הערכים שאנו מזינים לרשת ב-255 כדי לצמצם את הטווח שלהם לערכים בין 0 ל-1. בדומה, batch normalization היא פונקציה מנרמלת שעובדת על השכבות החבויות של הרשת הנוירונית כדי שפלט השכבות יהיה אחיד בין הפיצ'רים המרכיבים את מסד הנתונים.
ב-Keras מוסיפים את הפונקציה BatchNormalization כמו כל שכבה אחרת:
from tensorflow.keras.layers import Dense, BatchNormalization
...
# A single hidden layer
model.add(Dense(36, activation='relu'))
# Batch normalization layer
model.add(BatchNormalization(axis=1))כשעובדים עם הפונקציה BatchNormalization נשים לב:
א. שמוסיפים אותה אחרי שכבה חבויה.
ב. כמעט תמיד מגדירים את הנורמליזציה על העמודות (axis=1)
בדרך כלל, נצטרך להשתמש בשילוב של שיטות כדי לפתור את בעיית ה-overfitting שמתעקשת לתקוף את המודלים שלנו.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.