
למידת מכונה: סיווג תמונות באמצעות מודל VGG16 (חלק ג)למידת העברה ולמידה בפועל
סדרת מדריכים זו מדגימה למידת העברה, transfer learning, שהיא ענף של למידת מכונה המתמקד בשימוש בידע שנרכש תוך פתרון בעיה אחת לפתרון בעיה קשורה אחרת. במדריך זה, נלמד לייעד מחדש מודל VGG16 כדי שיוכל להבחין בין תמונות כלבים לחתולים במקום בין 1000 קבוצות שאותם למד המודל לסווג במקור.
מדריך זה הוא השלישי בסדרה העוסקת ב- transfer learning. במדריך הראשון הורדנו את מאגר הנתונים מ-Kaggle. במדריך השני סידרנו את התמונות בתיקיות בהתאם למבנה הנדרש על ידי Keras.
ובמדריך הנוכחי נלמד את המודל להבחין בין תמונות חתולים וכלבים כשאנחנו מסתמכים על מודל קיים VGG16 שבו אנחנו מחליפים את השכבות המסווגות של המודל שהבחינו בין 1000 קטגוריות במבנה חדש שידע להבחין בין תמונות כלבים לחתולים. זו גישה שמכונה transfer learning, ובה אנחנו משתמשים בידע שצבר המודל ומעבירים את הידע הזה לטיפול בבעיה דומה.
להורדת קוד הפרויקט שאותו נפתח במדריך
למידת העברה - transfer learning
כמו במדריכים הקודמים בסדרה נייבא את ספריות הקוד של Keras שבהם נשתמש להורדת המודל VGG16 ואימון המודל בגישה של למידת מכונה.
# importing tensorflow and Keras for doing ML
from tensorflow.python.keras.models import Model, Sequential
from tensorflow.python.keras.layers import Dense, Flatten, Dropout
from tensorflow.python.keras.applications import VGG16
from tensorflow.python.keras.applications.vgg16 import preprocess_input, decode_predictions
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
from tensorflow.python.keras.optimizers import Adam, RMSpropהאימון נעשה באצוות (batches) משום שניסיון לגרום ל-Keras להריץ את כל המידע בבת אחת עלול לגרום לקריסת המחשב.
# keras needs to divide the samples to batches because handling all of the
# samples at once is too costly
batch_size = 32משיכת התמונות נעשית באמצעות data generator ששולף את האצוות לפי הסדר עד שהוא מסיים את כל התמונות עבור כל epoch.
יש לנו שתי קטגוריות. כלבים נגד חתולים:
classes = ['cats','dogs']משיכת התמונות לתוך הרשת הנוירונית נעשית באמצעות ImageDataGenerator שמושך את האצוות מתוך כל אחת מהתיקיות בנפרד.
train_batches = ImageDataGenerator().flow_from_directory(directory=train_path,
classes=classes,
class_mode='categorical',
target_size=(224,224),
batch_size=batch_size,
shuffle=True)
valid_batches = ImageDataGenerator().flow_from_directory(directory=valid_path,
classes=classes,
class_mode='categorical',
target_size=(224,224),
batch_size=batch_size,
shuffle=True)
test_batches = ImageDataGenerator().flow_from_directory(directory=test_path,
classes=classes,
class_mode='categorical',
target_size=(224,224),
batch_size=batch_size,
shuffle=False)Found 18000 images belonging to 2 classes. Found 4500 images belonging to 2 classes. Found 2500 images belonging to 2 classes.
- 3 התיקיות הם לפי החלוקה המקובלת בעולם למידת מכונה : train, valid, test
- גודל התמונות הוא 224 על 224 לפי דרישות המודל VGG16.
- הסיווג הוא לפי קטגוריות.
- ה-generator נדרש שלא לערבב את המידע שהוא מושך מתיקיית test כדי שנוכל להשוות בהמשך את הקטגוריות שהמודל חזה עם הקטגוריות בפועל אליהם משתייכות התמונות.
נייבא את המודל VGG16 באמצעות Keras
# lucky for us the Keras API makes it a breeze to import the VGG16 model
vgg16_model = VGG16()נבחן את סוגו של המודל:
# the model is based on the Keras Model API which is harder to work with
type(vgg16_model)tensorflow.python.keras.engine.training.Model
עד היום לא עבדנו עם מודל מבוסס Model API, אבל אל דאגה נמיר את המודל ל-Sequential API שאיתו אנחנו כן יודעים לעבוד.
# we need to transform the model to the sequential API that we are used to work with
model = Sequential()
for layer in vgg16_model.layers:
model.add(layer)נבדוק את מה שעשינו:
type(model)tensorflow.python.keras.engine.sequential.Sequential
אכן sequential.
כדי לראות את מבנה המודל:
# let's take a peek at the layers that construct the model
model.summary()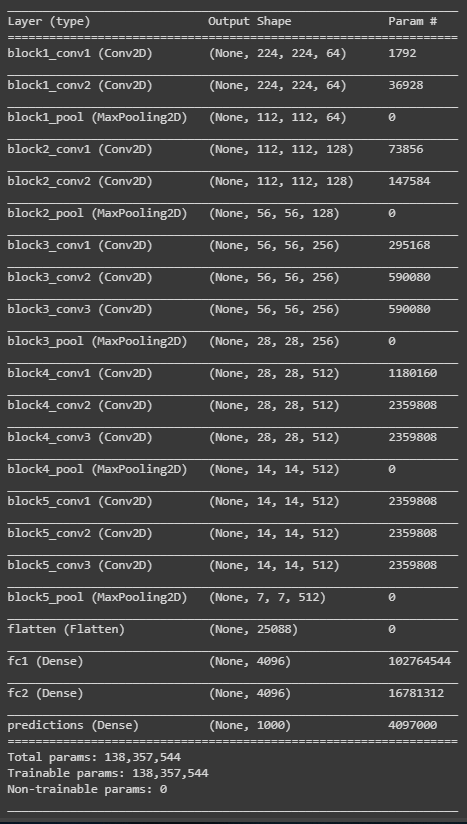
כמה פרמטרים! כמה שכבות! איך בכלל קוראים את זה?
5 השכבות הראשונות הם שכבות קונבולוציה. אח"כ ישנה שכבת flatten שמזינה שתי שכבות dense שמבצעות את הסיווג בפועל ל-1000 קטגוריות.
אבל אחנו לא מעוניינים לסווג ל-1000 קטגוריות אלא רק ל-2. כלבים וחתולים. לשם כך, נסיר את 3 השכבות האחרונות ואת כל היתר נצרף לבניית מודל חדש שיכלול רק את שכבות הקונבולוציה ושמו conv_model.
# for transfer learning we need to chop the classifying layers of the model
# for this we need to chop the last 4 layers (Flatten and 3 dense)
# that are used by the VGG16 model to classify into 1000 classes.
# leave the convolutional layers intact because we need to preserve the
# the data that they gained during the learning process.
# we'll call these layers the 'conv_model'
conv_model = Sequential()
for layer in vgg16_model.layers[:-4]:
conv_model.add(layer)התוצאה של התרגיל היא שנישארנו עם שכבות הקונבולציה בלבד המרכיבות עתה את המודל החדש שאיתו נמשיך לעבוד במדריך ששמו conv_model.
נסכם את המודל באמצעות:
conv_model.summary()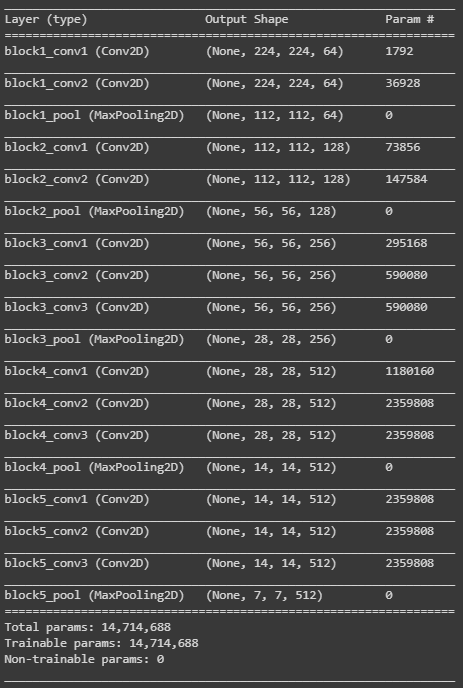
אנחנו רוצים לשמר את המידע שנצבר במודל למרות שתיכף נאמן אותו על התמונות שלנו. לצורך כך, "נקפיא" את שכבות הקונבולציה באופן שימנע מתהליך האימון לשנות את המשקלים שלהם:
# make the layers of the 'conv_model' untrainable because
# we want to save the data which was accumulated during the learning process
# from the researchers that developed the VGG16 model
for layer in conv_model.layers:
layer.trainable = Falseסיכום המודל עד כה ילמד אותנו שאת השכבות לא ניתן לאמן:
conv_model.summary()
כמעט 15 מיליון פרמטרים ואף לא אחד מהם ישתנה בתהליך האימון.
הגישה הזו שבה אנחנו מאמצים כמעט את כל המודל המקורי ומחליפים את החלק המסווג לקטגוריות מכונה transfer learning, כי היא מעבירה את המידע שנצבר בבעיה אחת לטובת פתרון בעיה אחרת דומה למדי. גישה יותר רדיקלית המכונה fine-tuning עשויה לאמן ואף להחליף חלק משכבות הקונבולוציה. במקרה שלנו, והודות לכך ש-VGG16 אומן בין השאר גם על קטגוריות של כלבים וחתולים אין צורך להתאמץ מעבר ל- transfer learning כדי להשיג את התוצאה הרצויה.
כדי להגדיר את המודל אנחנו צריכים להגדיר את ה-input וה-output שלו:
# we need to define the model inputs and outputs
# here the output is the last layer 'block5_pool'
# the following takes a reference to this layer
transfer_layer = model.get_layer('block5_pool')
# define the conv_model inputs and outputs
conv_model = Model(inputs=conv_model.input,
outputs=transfer_layer.output)נוסיף למודל את השכבות המסווגות. קודם שכבת flatten שמתווכת בין שכבת קונבולציה לשכבות ה-dense המסווגות בפועל ואח"כ שתי שכבות dense שביניהן שכבת dropout למניעת עודף התאמה. שכבת ה-dense האחרונה מסווגת ל-2 קטגוריות באמצעות פונקציית אקטיבציה softmax.
# the 2 classes: dogs and cats
num_classes = 2
# start a new Keras Sequential model.
new_model = Sequential()
# add the convolutional layers of the VGG16 model
new_model.add(conv_model)
# flatten the output of the VGG16 model because it is from a
# convolutional layer
new_model.add(Flatten())
# add a dense (fully-connected) layer.
# this is for combining features that the VGG16 model has
# recognized in the image.
new_model.add(Dense(1024, activation='relu'))
# add a dropout layer which may prevent overfitting and
# improve generalization ability to unseen data e.g. the test set
new_model.add(Dropout(0.5))
# add the final layer for the actual classification
new_model.add(Dense(num_classes, activation='softmax'))לצורך הקומפילציה של המודל אנחנו צריכים להגדיר פונקצית אופטימיזציה מסוג Adam עם קצב למידה נמוך למדי.
# in the process we use the Adam optimizer with a low learning-rate so we don't
# distort the original weights from the pre-trained VGG16 model
optimizer = Adam(lr=1e-5)קצב הלמידה הוא נמוך למדי אולם לא נמוך מאוד. במידה ותבחרו לעשות fine-tuning ולאפשר אימון גם של שכבות הקונבולוציה עליכם להוריד את את קצב הלמידה בסדרי גודל ל 1e-6 ואף מתחת לכך כדי למנוע את עיוות המשקולות בעקבות התפשטות השגיאה אחורנית לשכבות הקונבולוציה.
נבחר loss function בינארית:
# loss function should by 'categorical_crossentropy' for multiple classes
# but here we better use 'binary_crossentropy' because we need to distinguish between 2 classes
loss = 'binary_crossentropy'במקרה של יותר מ-2 קטגוריות עדיף להשתמש בפונקציה -categorical_crossentropy. למרות ששתיהם היו יעילות באותה מידה על משימת הסיווג במדריך.
נקמפל את המודל:
# compile the model
# the metrics is binary_accuracy (not category_accuracy)
new_model.compile(optimizer=optimizer, loss=loss, metrics=['binary_accuracy'])
אימון בפועל
נגדיר פונקציית עצירה מוקדמת שתפסיק את תהליך הלמידה במידה ואין בו התקדמות או במקרה של over fitting לסט האימון לעומת הוידוא.
# early stopping stops the learning process in the case that the process doesn't progress for 2 epochs
# or in the case of over fitting to the training data over the validation data
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=2,
verbose=1,
mode='auto')ה-data generators ירוצו לנצח. כדי שיריצו את כל סט הנתונים רק פעם אחת בכל epoch נגדיר את הפרמטר גודל הצעד כמנת החלוקה בין מספר התמונות בסט ובין גודל האצווה:
# the data generators are built to loop for eternity so we need to specify the number
# of steps to perform during training and validating so each epoch we'll run all the
# images in the dataset only once.
# here we refer to these constants as 'step_size_train' and 'step_size_valid'
step_size_train=train_batches.n//train_batches.batch_size
step_size_valid=valid_batches.n//valid_batches.batch_sizeאימון המודל בפועל נעשה באמצעות fit_generator שירוץ לכל היותר 100 epochs, אולם בפועל יעצור עוד קודם הודות ל-early stopping:
# at last! fit the model - the actual learning process
# here i define the process to be 100 epochs
# with the early stopping function stopping the learning process
# whenever it reaches convergence between the training and validation steps
history = new_model.fit_generator(train_batches,
epochs=100,
steps_per_epoch=step_size_train,
validation_data=valid_batches,
validation_steps=step_size_valid,
callbacks = [es],
verbose=1)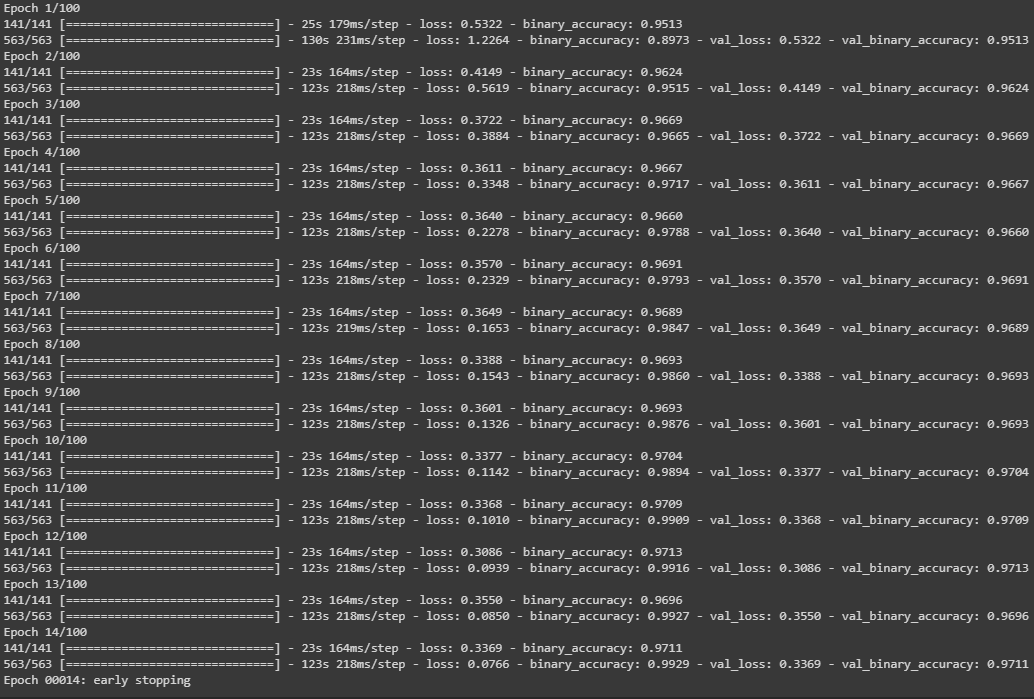
בהרצה הנוכחית עצר אחרי 14 epochs.
הערכת המודל
מטרת המודל היא לבצע תחזיות על מידע שהוא לא נחשף אליו. נעריך את ביצועי המודל על סמך מידת הדיוק של סיווג תמונות בסט המבחן (test). אילו תמונות שהמודל לא נחשף אליהם במהלך הלמידה.
# evaluate the model by measuring the model's accuracy.
# we perform the evaluation on the test images since our model
# wasn't exposed to during the training process
step_size_test=test_batches.n//test_batches.batch_size
result = new_model.evaluate_generator(test_batches, steps=step_size_test)
print("Test set classification accuracy: {0:.2%}".format(result[1]))Test set classification accuracy: 97.36%
למעלה מ-97% דיוק. לא רע בכלל!
במדריך הבא בסדרה על transfer learning נמשיך להעריך את ביצועי המודל באמצעות confusion matrix וחיזוי לגבי סט נתוני המבחן.
לכל המדריכים בסדרה על למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.