

סיווג לקבוצות באמצעות למידת מכונה
מטרת המדריך היא ללמד את המחשב להבחין בין קבוצות בעזרת למידת מכונה. לשם כך נשתמש במסד נתונים קלאסי הכולל מדידות ושמות של שלושה זני אירוסים. זני הפרחים נראים כמעט זהים לחלוטין לעין אנושית אולם מעט מומחים בעולם יכולים להבחין ביניהם על סמך ממדי עלי הכותרת. מעניין האם מודל למידת המכונה אותו נפתח במדריך יצליח במלאכת הסיווג.

להורדת הקוד המלא אותו נפתח במדריך: קובץ ipynb
ייבוא הספריות הבסיסיות
נייבא את 4 הספריות הבאות:
# Import the modules
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns- Numpy מאפשרת לעבוד עם מערכים רב-מימדיים.
- Pandas לסידור ולסינון המידע בדומה לגיליון אקסל.
- Matplotlib ליצירת תרשימים.
- Seaborn מבוססת על Matplotlib. באמצעותה נציג תרשימים יפים ומתקדמים.
את המדריך פיתחתי בסביבת Colab המאפשרת להריץ מודלים של למידת מכונה על המחשבים של גוגל בחינם. כל מה שצריך הוא חשבון Gmail.
את למידת המכונה נעשה באמצעות TensorFlow 2.
נייבא את הספרייה:
!pip install tensorflow==2.2.0
import tensorflow as tfבהמשך, נייבא ספריות נוספות לפי הצורך.
ייבוא וסקירת מסד הנתונים
את מסד הנתונים הכולל 150 דוגמאות של שלושה זני אירוסים. שם הזן, ומדידות אורך וגובה עלי הכותרת ייבאתי מ- archive.ics.uci.edu/ml/datasets/iris. הזנתי ידנית את שמות העמודות המתוארים בקובץ data.names בתור השורה הראשונה.
יבוא הקובץ:
# Load the dataset
df = pd.read_csv('iris.data')סקירת מסד הנתונים:
df.head()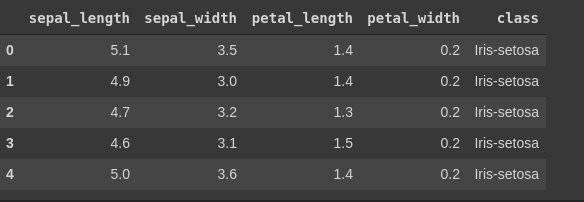
נוודא את סופו של הקובץ כדי לחסוך מעצמנו הפתעות בהמשך:
df.tail()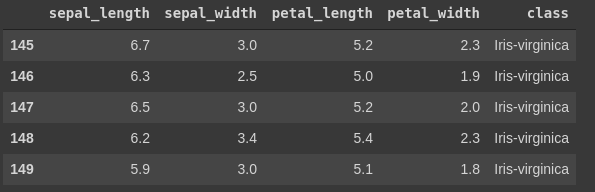
כמה דוגמאות? האם חסרות דוגמאות? מה סוג הנתונים בכל עמודה?
df.info()RangeIndex: 150 entries, 0 to 149 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 sepal_length 150 non-null float64 1 sepal_width 150 non-null float64 2 petal_length 150 non-null float64 3 petal_width 150 non-null float64 4 class 150 non-null object dtypes: float64(4), object(1) memory usage: 6.0+ KB
- 150 דוגמאות
- 4 עמודות של מדידות עם סוג נתונים float
- עמודה אחת עם שמות הזנים
- לא חסרים נתונים
מסד הנתונים כולל 150 דוגמאות בלבד ממש מעט בשביל למידת מכונה, במיוחד כשעובדים עם מודלים של TensorFlow.
מהם שמות הזנים?
# Get the unique labels from the list with the help of numpy
species_names = np.unique(np.array(y))
species_namesarray(['setosa', 'versicolor', 'virginica'], dtype=object)
האם נוכל להבחין בעין בין הזנים?
sns.set(style='ticks')
sns.pairplot(df, hue='class')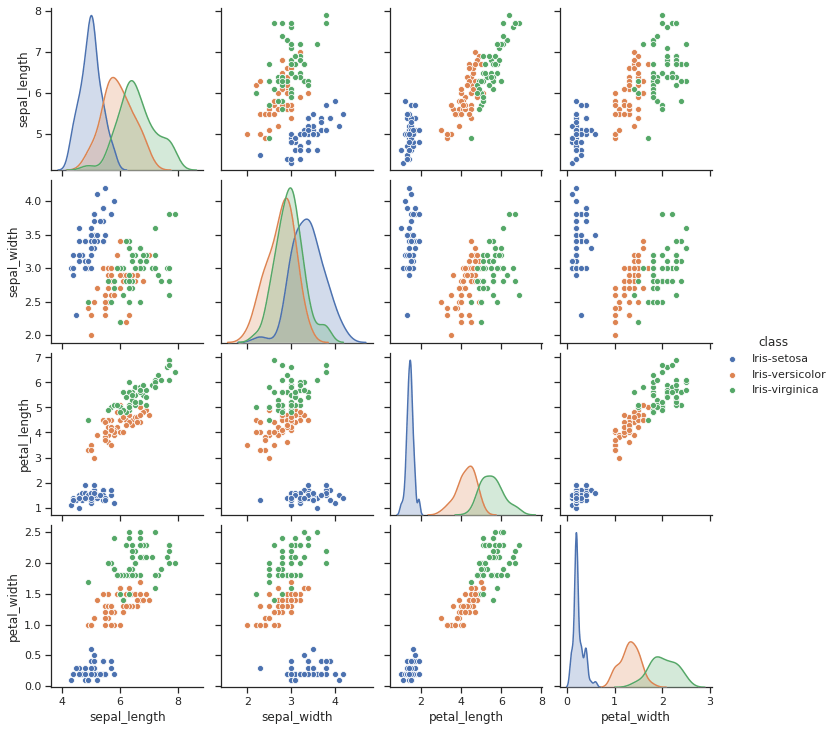
- הזן setosa נראה שונה מ-versicolor ו-virginica, בעוד שני הזנים האחרונים נוטים להתקבץ ביחד.
האם מסד הנתונים מאוזן? כמה דוגמאות יש לנו מכל זן?
df['class'].value_counts()Iris-versicolor 50 Iris-setosa 50 Iris-virginica 50 Name: class, dtype: int64
כן. מסד הנתונים מאוזן וכולל 50 דוגמאות מכל סוג.
נסקור את מדדי המרכז עבור מסד הנתונים.
df.describe()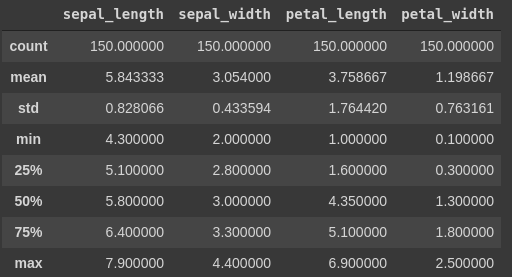
ישנה מידה של שונות בין העמודות. דיאגרמת box plot תסייע לנו לראות את ההבדלים:
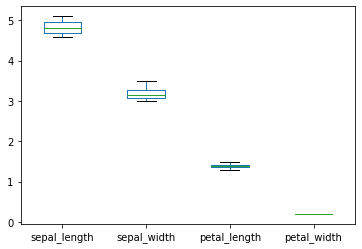
העמודות שונות משמעותית ועל כן נצטרך לנרמל אותם כדי שכולם יהיו על אותה סקאלה.
שאלה חשובה נוספת היא האם יש לנו דוגמאות חריגות (outliers), כאשר נהוג להגדיר דוגמאות הסוטות ביותר מ-3 סטיות תקן מהממוצע כחריגות.
from scipy.stats import zscore
z = np.abs(zscore(df.iloc[:,:4]))
print(np.where(z > 3))(array([15]), array([1]))
המערך הראשון מתייחס לדוגמה שבה מופיעה החריגה והמערך השני לאינדקס העמודה. לפיכך, יש לנו חריגה אחת במסד הנתונים בעמודה השנייה של דוגמה מספר 15.
הכנת הנתונים ללמידת מכונה
כדי להכין את הנתונים ללמידת מכונה נעשה את הפעולות הבאות:
- נסיר או נתאים את ערכם של הדוגמאות החריגות.
- נפריד מספר דוגמאות לסט מבחן (holdout) שלא משתתף בתהליך הלמידה. אותו נשמור לבדיקת דיוק המודל בסוף.
- נפריד את עמודת התכונה שאנו מעוניינים לסווג (שם הזן) מהתכונות על פיהם נסווג (אורך וגובה עלי הכותרת).
- ננרמל את עמודות הנתונים המספריים כדי שיהיו על אותה הסקאלה
- נקודד את שמות הזנים
- נחלק את הדוגמאות לקבוצת אימון ובקרה
טיפול בדוגמאות החריגות
בסעיף הקודם ראינו שישנה דוגמה חריגה. הבעיה עם דוגמאות חריגות שהם יכולות לפגוע בתפקוד המודל בפרט אם השיעור היחסי של הדוגמאות החריגות הוא גבוה באוכלוסיה או שהערכים בהם הם קיצוניים.
כשאנו נתקלים בדוגמאות חריגות יש לנו שתי ברירות: להסיר אותם ממסד הנתונים או להחליף את הערך שלהם בממוצע או בחציון. אחד השיקולים הוא מספר הדוגמאות, ובמקרה שלנו סט הנתונים קטן מאוד (בסך הכול 150 דוגמאות) ולכן נעדיף להחליף את הערך החריג בחציון, ולהשאיר כמה שיותר דוגמאות. מדוע חציון ולא ממוצע? כי החציון מושפע פחות מערכים קיצוניים.
נציץ בדוגמה החריגה כדי שיהיה לנו למה להשוות בסוף הטיפול:
df.loc[15]sepal_length 5.7 sepal_width 4.4 petal_length 1.5 petal_width 0.4 class Iris-setosa Name: 15, dtype: object
החריגה היא בעמודה השנייה, sepal_width.
מהו הערך z של הנתונים בעמודה השנייה?
z = np.abs(zscore(df.iloc[:,1]))נמצא את ערך החציון של העמודה ללא התחשבות בערכים חריגים:
median = df.iloc[np.where(z <= 3)[0], 1].median()נחליף את הערך החריג:
df.iloc[np.where(z > 3)[0], 1] = np.nan
df.fillna(median, inplace=True)נבדוק את הדוגמה אחרי ההחלפה:
df.iloc[15]sepal_length 5.7 sepal_width 3 petal_length 1.5 petal_width 0.4 class Iris-setosa Name: 15, dtype: object
יופי. החלפנו בהצלחה את הערך.
נוודא שאין דוגמאות חריגות בסט הנתונים:
z = np.abs(zscore(df.iloc[:,:4]))
print(np.where(z > 3))(array([], dtype=int64), array([], dtype=int64))
אין דוגמאות חריגות.
הפרדת סט המבחן
נפריד 6 דוגמאות לסט מבחן (holdout) שלא משתתף בתהליך הלמידה. אותו נשמור לבדיקת דיוק המודל אחרי שנסיים את האימון.
# Save 6 samples as a holdout group to use only in the testing phase - don't touch it until you finish training and evaluating your model
df0 = df.sample(frac=0.96, random_state=42)
holdout = df.drop(df0.index)
נפריד את ציר התכונה שאנו מעוניינים לסווג (שם הזן) מהתכונות על פיהם נסווג (אורך וגובה עלי הכותרת)
נפריד את עמודת שמות הזנים (class) מיתר העמודות.
x = df.iloc[:,:4]
y = df.iloc[:,4]- המשתנים הבלתי תלויים המרכיבים את x הם אורך ורוחב עלי הכותרת.
- עמודת שמות הזנים הם המשתנה התלוי y.
ננרמל את עמודות הנתונים המספריים
ננרמל את העמודות המספריות כדי למנוע את הבעיה שהמודל נותן משקל יתר לעמודה רק מכיוון שהנתונים בה גבוהים יותר.
x_standard = x.apply(zscore)מה קרה לנתונים בעקבות הנירמול?
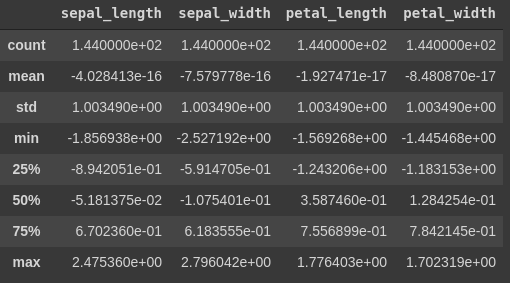
כל העמודות הם עכשיו באותו שיעור גודל. עם ממוצע 0, וסטיית תקן 1.
נקודד את שמות הזנים
שמות הזנים הם מחרוזות (טקסטים) אבל מחשבים יודעים לעבוד עם מספרים. הפתרון הוא להשתמש בשיטת One hot encoding שהופכת משתנים קטגוריים סותרים (mutually exclusive) למשתנים מספריים שהמחשב יודע לעבוד איתם.
העובדה שהזנים במסד הנתונים מובחנים וסותרים מאפשרת את הסיווג מכיוון שידוע לנו שכל דוגמה שייכת לזן אחד מובחן ואינה תוצאה של הכלאה.
# one hot encode the labels since they are categorical
y_cat = pd.get_dummies(y, prefix='cat')מה התוצאה של הקידוד?
y_cat.sample(10, random_state=42)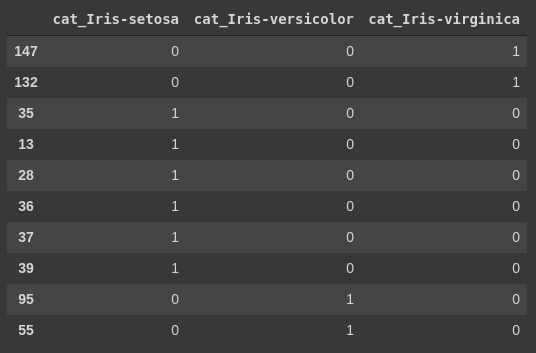
מסד הנתונים של נתוני הדמה שהתקבל באמצעות one hot encoding מקודד את הזנים שאותם אנו רוצים לסווג. בקידוד one hot כל העמודות מקבלות את הערך 0 מלבד עמודה אחת שמקבלת את הערך 1. עמודה זו מציינת את הקטגוריה שהדוגמה שייכת אליה.
את עמודות שמות הזנים קודדנו בשיטת one hot encoding כפי שצריך לעשות עבור עמודות המכילות נתונים קטגוריים בגלל שהמודל שלנו לא יודע לעבוד עם טקסטים. מדוע השתמשנו בשיטת one hot במקום להפוך את הקטגוריות למספרים? כדי למנוע מהמודל להתייחס לקטגוריות כאל כמויות. מה שעלול לגרום למודל לחשוב שחיבור של קטגוריה שקידודה 1 עם קטגוריה שקידודה 2 ייתן קטגוריה שקודדה 3.
נחלק את הדוגמאות לקבוצת אימון ובקרה
נשתמש בפונקציה train_test_split כדי להפריד לקבוצת אימון ובקרה:
# Split into train and test groups
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x_standard, y_cat, test_size=0.5, random_state=42)- כיוון שסט הנתונים קטן מאוד השתמשתי במחצית הדוגמאות כקבוצת אימון. בד"כ נסתפק בקבוצות אימון קטנות יותר - 30% או פחות.
- המשתנה התלוי x הם מדידות אורך ורוחב עלי הכותרת.
- עמודת שמות הזנים הם המשתנה התלוי y.
בניית ואימון המודל
נייבא את התלויות הדרושות לבניית מודל למידת מכונה באמצעות TensorFlow:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStoppingהמודל מורכב משתי שכבות דחוסות (Dense) שבהם כל יחידה בשכבה מתקשרת לכל יחידה בשכבה הבאה:
# build the model
model = Sequential()
# the first layer receives 4 input features and outputs 3 to the next layer
# the activation function 'relu' is the standard in the literature
model.add(Dense(8, input_shape=(4,), activation='relu'))
# the second layer outputs 3 classes as the number of species
# because it is categorical we use the softmax activation function
model.add(Dense(3, activation='softmax'))- המודל מורכב משתי שכבות: שכבת קלט ופלט.
- שכבת הקלט כוללת 4 קלטים כמספר התכונות שאנו מעבירים למודל לצורך הסיווג. אילו 4 המדידות של ממדי עלי הכותרת.
- שכבת הקלט אף כוללת 8 יחידות חישוב.
- relu היא פונקצית האקטיבציה ברירת המחדל.
- שכבת הפלט כוללת 3 פלטים כמספר זני האירוסים.
- פונקצית האקטיבציה softmax משמשת בשכבת הפלט לסיווג שאינו בינארי, הכולל יותר משתי מחלקות.
נתאר את מבנה המודל:
model.summary()Model: "sequential" ______________________________________ Layer (type) Output Shape Param# ====================================== dense (Dense) (None, 8) 40 __________________________________ dense_1 (Dense) (None, 3) 27 ================================== Total params: 67 Trainable params: 67 Non-trainable params: 0 __________________________________
נקמפל את המודל:
# The categorical_crossentropy loss function is the one we use when working with categorical labels
# the adam optimizer and accuracy as a metrics are standard
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])- פונקצית האופטימיזציה היא Adam, המהווה את ברירת המחדל.
- פונקצית ה-loss היא categorical_crossentropy כי היא המתאימה ביותר לעבודה עם קטגוריות.
- את התקדמות תהליך הלמידה נמדוד באמצעות accuracy.
הלימוד בפועל נעשה במסגרת של מחזורי למידה epoch. בסוף כל מחזור למידה פונקצית ה-loss מעריכה את דיוק המודל (accuracy) על פי התחזית שמנפק המודל עבור הדוגמאות בקבוצת הבקרה. על סמך ערך זה פונקצית האופטימיזציה מעדכנת את המשקולות וההטיות (weights and biases) של המודל.
המודל יכול לרוץ מספר מוגדר מראש של מחזורי למידה אבל אני מעדיף את הגישה של שימוש בפונקצית עצירה מוקדמת, Early Stopping, שעוצרת את תהליך הלמידה כאשר המודל מתכנס ולא מצליח ללמוד יותר:
# Early stopping function
es = EarlyStopping(monitor='val_loss', patience=2)- התכונה שהפונקציה EarlyStopping מנטרת נקראת val_loss, ה-loss של קבוצת הבקרה - הקבוצה שאינה משתתפת בתהליך הלמידה עצמו אלא רק בהערכה שלו.
- במידה ואין שיפור בתכונה val_loss במשך 2 מחזורים (epochs) רצופים הפונקציה עוצרת את התהליך.
נאמן את המודל:
# Train the model
model.fit(x_train, y_train, validation_data=(x_test,y_test), batch_size=32, callbacks=[es], epochs=1000)- המודל לומד מדוגמאות קבוצת האימון לאורך 1000 מחזורי למידה לכל היותר או עד לעצירה ביוזמת הפונקציה EarlyStopping במידה ואין התקדמות בלמידה.
- הערכת ביצועי המודל נעשית בסיום כל מחזור למידה כנגד דוגמאות קבוצת הבקרה.
- המודל מעבד 32 דוגמאות במקביל בכל מחזור למידה.
בבדיקה שערכתי, המודל רץ 588 מחזורי למידה עד שהפונקציה EarlyStopping עצרה אותו.
הערכת המודל
בחלק זה של המדריך נעריך את ביצועי המודל באמצעות המדד של דיוק accuracy , נגלה באילו מהזנים המודל שגה יותר באמצעות confusion matrix ונכיר את המדד f1 שעשוי לספק תוצאות טובות יותר מדיוק (accuracy) בהערכת ביצועי המודל.
נעריך את ביצועי המודל על סמך יכולת הסיווג שלו את דוגמאות קבוצת המבחן.
נעריך את ביצועי המודל בעזרת פונקציה של TensorFlow שמעריכה את דיוק המודל:
loss, acc = model.evaluate(x_test, y_test)3/3 [==============================] - 0s 2ms/step - loss: 0.1640 - accuracy: 0.9444
f'The accuracy is %.2f' % (acc)The accuracy is 0.94
המודל חוזה את דוגמאות קבוצת הבקרה ברמת דיוק של 94%.
כדי להבין איך הסיווג עובד נחזה את הקטגוריה של 5 דוגמאות בקבוצת הניסוי:
y_pred = model.predict(x_test)
y_pred[:5]array([[8.8124664e-04, 5.6953058e-02, 9.4216567e-01],
[1.6015852e-04, 1.7979069e-02, 9.8186076e-01],
[9.9619138e-01, 3.7830384e-03, 2.5548978e-05],
[9.9858946e-01, 1.4067279e-03, 3.8264106e-06],
[9.9728954e-01, 2.6752544e-03, 3.5232220e-05]], dtype=float32)
פלט פונקצית החיזוי הם הסבירויות להשתייכות כל אחת מהדוגמאות לכל אחד מזני הפרחים.
בדוגמה הראשונה:
[8.8124664e-04, 5.6953058e-02, 9.4216567e-01]
- הסיכוי שהדוגמה שייכת לזן השלישי היא למעלה מ-94%, ולעומת זאת הזן השני זוכה לסבירות של 5.7%, והזן השלישי לסיכוי הקרוב ל-0.
- סכום ההסתברויות עבור כל דוגמה הוא 1.
כדי להסיק את זהות הזנים החזויים נשתמש בפונקציה np.argmax שממצה מכל דוגמה את הערך הגבוה ביותר:
np.argmax(y_pred[:5], axis=1)array([2, 2, 0, 0, 0])
המודל חוזה ששתי הדוגמאות הראשונות שייכות לסוג השלישי ומסווג את דוגמאות שלוש וארבע לסוג הראשון.
אחרי שקיבלנו תחושה, נמצה את הסיווגים החזויים עבור כל דוגמאות קבוצת המבחן:
# Get the indices of the class which got the highest probability within each sample
y_pred = np.argmax(y_pred,axis=1)
y_predarray([2, 2, 0, 0, 0, 0, 0, 0, 1, 1, 2, 0, 2, 2, 0, 1, 2, 1, 1, 2, 0, 1,
1, 2, 1, 1, 1, 1, 2, 0, 0, 1, 1, 2, 2, 1, 2, 1, 1, 2, 0, 2, 1, 2,
0, 2, 2, 2, 2, 2, 2, 2, 0, 1, 1, 0, 0, 0, 2, 1, 2, 0, 1, 2, 2, 0,
0, 2, 0, 2, 2, 0])
הרשימה היא תחזית המודל עבור כל אחת מהדוגמאות בקבוצת המבחן.
כדי שנוכל להשוות את התחזית עם הערכים בפועל, נמצה אותם באמצעות הפונקציה np.argmax:
y_actual = np.argmax(np.array(y_test), axis=1)array([2, 2, 0, 0, 0, 0, 0, 0, 1, 1, 2, 0, 2, 2, 0, 1, 2, 1, 1, 2, 0, 1,
1, 2, 1, 1, 1, 1, 2, 0, 0, 2, 1, 2, 2, 2, 2, 1, 1, 2, 0, 2, 1, 1,
0, 2, 2, 2, 2, 2, 2, 2, 0, 1, 1, 0, 0, 0, 2, 1, 2, 0, 1, 2, 2, 0,
0, 2, 0, 2, 1, 0])
Confusion matrix
Confusion matrix הוא כלי שמאפשר לנו לזהות את הסיווגים בהם המודל שגה באמצעות טבלה פשוטה.
from sklearn.metrics import classification_report, confusion_matrix
print('Confusion Matrix')
cf_matrix = confusion_matrix(y_actual, y_pred)
print(cf_matrix)Confusion Matrix [[22 0 0] [ 0 19 2] [ 0 2 27]]
- השורות הם הערכים בפועל, והטורים הם הערכים החזויים.
- המודל סיווג נכונה את כל 29 הדוגמאות השייכות לזן הראשון.
- המודל סיווג נכונה 21 דוגמאות של הזן השני אך שגה בסיווג של שתי דוגמאות אותם הוא שייך בטעות לזן השלישי.
- המודל סיווג נכונה 27 דוגמאות מהזן השלישי אך שגה בסיווג 2 דוגמאות אותם הוא שייך בטעות לזן השני.
- נראה שעיקר הבלבול הוא בין הזנים השני והשלישי. תוצאה עקבית עם העובדה שהזנים הם כמעט בלתי מובחנים.
מפת חום (heat map) מציגה את נתוני ה-confusion matrix באופן שמושך את העין. בתצוגה הבאה האזורים החמים מסומנים בכחול והקרים בלבן.
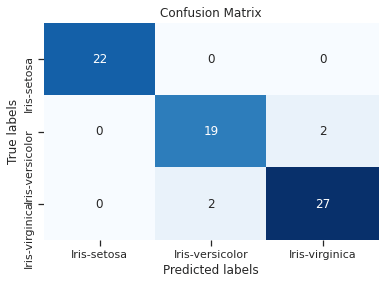
- על הקו האלכסוני שחוצה את האיור מהצד השמאלי העליון לצד הימני התחתון מסודרים התאים שבהם מתלכדות התחזיות עם הערך בפועל.
- ככל שהערכים בתוך התאים המרכיבים את הציר האלכסוני גבוהים יותר כך המודל מוצלח יותר.
- הערכים הגבוהים מ-0 המופיעים מחוץ לקו האלכסוני מעידים על דוגמאות בהם המודל פספס.
מדד f1
מלבד שיעור הדיוק (accuracy) חשוב להעריך את ביצועי המודל המסווג באמצעות מדד f1 שלוקח בחשבון את המדדים: recall ו-precision מפני שהוא נותן לנו תמונה אמינה יותר כאשר הקבוצות לא מאוזנות. משמע, באחת הקבוצות יש יותר דוגמאות.
נייבא את הספריות של sklearn שיאפשרו לנו להעריך את ביצועי המודל:
from sklearn.metrics import accuracy_score, classification_report, f1_scoreאת מידת הדיוק הערכנו כבר באמצעות TensorFlow. נעריך אותו גם באמצעות sklearn:
acc = accuracy_score(y_actual, y_pred)
f'The accuracy is %.2f' % (acc)The accuracy is 0.94
תוצאה שהיא עקבית עם מידת הדיוק שהציג TensorFlow.
פונקציה נוספת שתעזור לנו להעריך את ביצועי המודל:
print(classification_report(y_actual, y_pred))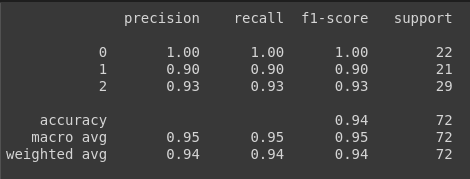
ומה לגבי f1:
f1 = f1_score(y_actual, y_pred, average='macro')
f'The f1_score is %.2f' % (f1)The f1_score is 0.95
- ערך f1-score הוא 0.95.
- במקרה שלנו, הערכים של ה-accuracy וה-f1 score הם כמעט זהים הודות לעובדה שהקבוצות מאוזנות עם אותו מספר של דוגמאות בכל אחד מהזנים.
ככל ש-f1-score גבוה יותר כך הוא טוב יותר. הערך הגבוה ביותר האפשרי הוא 1, והנמוך ביותר הוא 0.
האם ערך של 0.94 הוא מספיק גבוה? תלוי בצורך. אם המטרה היא להבחין בין זן של צמח ראוי למאכל אדם לכזה שעלול להרעיל למוות אז לא נסתכן במודל שמנפק ערכים נמוכים מ-1.
כדי להבין את המשמעות של המדד f1-score צריך יותר מאשר פסקה במדריך בגלל שאם נבין את אופן החישוב והסיבה שמאחורי המדד נפתח את היכולת להעריך מידע. יכולת מהותית להבנת למידת מכונה מעבר לספרייה זו או אחרת. אז במדריך הבא ננסה להבין לעומק את האופן שבו אנו מעריכים את ביצועי המודל, ובכלל כך סוגי שגיאות ומדידת שיעור השגיאה. לקריאת המדריך על confusion matrix בלמידת מכונה.
הערכת ביצועי המודל על דוגמאות חדשות
המטרה שלנו בפיתוח מודלים מסווגים היא שהמחשב ילמד להבחין בין דוגמאות בעולם האמיתי. לפיכך, בשלב זה חשוב לבדוק האם המודל שלנו יכול לזהות דוגמאות חדשות, שאליהם הוא לא נחשף במהלך האימון. נשתמש בסט ה-holdout כדי להעריך את ביצועי המודל על דוגמאות חדשות.
נקודד את הנתונים:
ho_x = holdout.iloc[:,:4].apply(zscore)נפעיל את המודל על הנתונים המקודדים:
y_pred = np.argmax(model.predict(ho_x), axis=1)נעריך את יכולת הסיווג של המודל על ידי השוואת הסיווגים שעשה המודל עם הקטגוריות האמיתיות:
ho_y = holdout.iloc[:, 4]y_actual = ho_y
y_actual14 Iris-setosa 20 Iris-setosa 71 Iris-versicolor 92 Iris-versicolor 102 Iris-virginica 106 Iris-virginica Name: class, dtype: object
נמיר את הערכים השמיים לקטגוריות מספריות:
y_actual_idx = [np.where(species_names == sn)[0][0] for sn in y_actual]נשווה את תחזית המודל לערכים בפועל:
y_actual_idx = np.array(y_actual_idx)
compare = pd.concat([pd.DataFrame(holdout.index), pd.DataFrame(y_actual_idx), pd.DataFrame(y_pred)], axis=1)
compare.columns = ['index', 'actual', 'predicted']
compare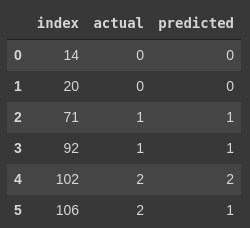
התחזית מדויקת עבור 5 מתוך 6 הדוגמאות אליהם המודל לא נחשף בזמן האימון. השגיאה בסיווג של הדוגמה האחרונה היא עקב בלבול בין הזן השני והשלישי.
במחברת המצורפת תוכלו לראות את כל המהלכים המוסברים במדריך וגם לראות גישה חלופית לסיווג באמצעות מודל של sklearn ששמו GaussianNB.
סיכום
במדריך זה למדנו לסווג דוגמאות מספריות לקטגוריות שמיות באמצעות מודל של למידת מכונה מבוסס TensorFlow.
אחת הבעיות העיקריות של למידת מכונה, ובפרט כאשר המכונה לומדת מכמות עצומה של מידע היא שהמודל מתקשה לנפק תוצאות טובות יותר מאשר איכות המידע שמוזן לתוכו. בעיה המבוטאת באמרה הידועה "אם הכנסת זבל - תקבל זבל" (garbage in - garbage out). כדי לפתור את הבעיה זיהינו את הדוגמאות החריגות, ולאחר מכן ביצענו טרנספורמציה של הנתונים המספריים באמצעות zscore.
את עמודות שמות הזנים קודדנו בשיטת one hot encoding כפי שצריך לעשות עבור קטגוריות בגלל שהמודל שלנו לא יודע לעבוד עם טקסטים. מדוע השתמשנו בשיטת one hot במקום להפוך את הקטגוריות למספרים? כדי למנוע מהמודל להתייחס לקטגוריות כאל כמויות. מה שעלול לגרום למודל לחשוב שחיבור של קטגוריה שקידודה 1 עם קטגוריה שקידודה 2 ייתן קטגוריה שקודדה 3.
כיוון שהמודל מסווג דוגמאות לקטגוריות מרובות (יותר מ-2) למדנו להשתמש במודל TensorFlow המצויד בשכבת פלט הכוללת פונקצית אקטיבציה מסוג softmax. בנוסף, לצורך קומפילציה השתמשנו בפונקצית loss מסוג categorical_crossentropy.
בסיום המדריך, למדנו כיצד להעריך את יכולת הסיווג של המודל ובכלל כך מידת הדיוק ושימוש ב-confusion matrix ובמדד f1-score . כדי להסביר את הצורך במדד f1-score מעבר למדד הדיוק (accuracy) צריך יותר מפסקה במדריך כי אם נבין את אופן החישוב והסיבה שמאחורי המדד נפתח את היכולת שלנו להעריך מידע. יכולת מהותית להבנת למידת מכונה מעבר לספרייה זו או אחרת. אז במדריך הבא ננסה להבין לעומק את האופן שבו אנו מעריכים את ביצועי המודל, ובכלל כך סוגי שגיאות ומדידת שיעור השגיאה. לקריאת המדריך על confusion matrix בלמידת מכונה.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.