
Confusion matrix ומדדים להערכת המודל
אחרי שסיימנו לפתח את המודל במדריך הקודם השאלה היא עד כמה הוא טוב. תשובה אחת שראינו משתמשת במדד "דיוק" (accuracy). המדד accuracy יודע להעריך באופן כללי עד כמה המודל הוא מדויק אבל הוא לא יודע להגיד לנו אילו שגיאות הוא עשה. בנוסף, יעילותו פוחתת כאשר סט הנתונים לא מאוזן. כדי לזהות את השגיאות מתארים את התוצאות באמצעות Confusion matrix שמתוכה מחשבים מדדים להערכת המודל (model evaluation metrics).
שימו לב, ה-confusion matrix והמדדים שנראה במדריך טובים לבעיות של סיווג לקבוצות מובחנות (mutually exclusive), ולא לבעיות של רגרסיה.
בואו ניקח לדוגמה מכונה שלומדת להבחין בין אנשים חולים בקורונה לבריאים (=מי שאינם חולים). לפני תהליך הלמידה צריך להכין את הדוגמאות, ולשם כך רופא מיומן צריך לסווג 300 אנשים לקבוצת החולים והבריאים. בשלב הבא, נפריד את האנשים לשתי קבוצות, אימון (train) וביקורת (test). שני שליש מהאנשים (200) יוקצו לקבוצת האימון שממנה תלמד המכונה, והיתר (100) ישמרו בצד בקבוצת הביקורת, שתשמש להערכת המודל שפיתחה המכונה. אחרי שהמכונה התאמנה ופיתחה את המודל, נעריך את המודל על קבוצת הביקורת ששמרנו בצד, ונקבל את התוצאות הבאות:
| n=100 | לא חולה לפי המודל | חולה לפי המודל |
|---|---|---|
| לא חולה במציאות | 50 | 2 |
| חולה במציאות | 1 | 47 |
העמודות מכילות את הקבוצות כפי שסווגו על ידי המודל, והשורות את הסיווג בפועל.
הטבלה לעיל היא מקרה פרטי של Confusion matrix שבה כל תא מוקדש למקרה אחר. זיהוי נכון או שגוי. המקרה הכללי הפשוט ביותר של Confusion matrix מחלק לשתי קבוצות מובחנות. "בריאים" לעומת "חולים", "לא" לעומת "כן", 0 לעומת 1, או negative לעומת positive.
| Predicted positive | Predicted negative | |
|---|---|---|
| False positive | True negative | Actual negative |
| True positive | False negative | Actual positive |
המודל צודק בשני המקרים שבהם הוא משייך את הדוגמאות לקבוצות הנכונות. True positive ו-True negative.
המודל טועה כאשר הוא משייך לקבוצות הלא נכונות (2 התאים הוורודים).
הטעויות מחולקות לשני סוגים:
False positive - כאשר הערך האמיתי הוא negative אולם התחזית של המודל היא positive. בדוגמה שלנו, המודל משייך בטעות אדם בריא לקבוצת החולים.
False negative - כאשר הערך האמיתי הוא positive והתחזית היא negative. בדוגמה שלנו, חולה במציאות מזוהה כבריא על ידי המודל.
False positive ידועים גם כ-Type I error בעוד False negative ידועים גם כ-Type II error.
הטבלה הזו מלמדת אותנו איזה סוג של שגיאות המודל עושה.
מתי להשתמש ב-Confusion matrix?
טבלת Confusion matrix משמשת לבעיות של סיווג לקבוצות מובחנות באופן ברור. לדוגמה, חולים לעומת בריאים, תפוזים באיכות יצוא לעומת תפוזים שמיועדים לסחיטת מיצים, כלבים לעומת חתולים וכיו"ב.
Confusion matrix לא יכול לשמש להערכת בעיות של סיווג לקבוצות שאינן מובחנות. לדוגמה, סיווג לגזעים של כלבים כאשר ידוע מראש שלפחות חלק מהדוגמאות הם של כלבים מעורבים.
Confusion matrix לא יכול לשמש להערכת בעיות של רגרסיה ליניארית שבוחנות קשר בין גדלים (תחזית יבול העגבניות על פי מספר ימי הקרה בשנה).
מדדים להערכת המודל
טבלת Confusion matrix מתארת את הנתונים. כדי להעריך את המודל אנחנו צריכים מדדים שאותם נפיק מתוך הטבלה. קיימים מדדים רבים אבל אנחנו נתרכז בשלושה: accuracy, recall ו- precision.
Accuracy (דיוק)
המדד הפשוט ביותר הוא דיוק (accuracy), שהוא היחס בין הסיווגים הנכונים לבין סך כל הסיווגים.
![]()
בדוגמה שלנו:
![]()
הדיוק של המודל הוא 0.97 כי 97 מתוך 100 הדוגמאות סווגו לקבוצה הנכונה.
הבעיה עם המדד accuracy שהוא אמין רק בתנאי שהדוגמאות מאוזנות (אותה פרופורציה לכל קבוצה לדוגמה, 50 חולים ו-50 בריאים). אבל לא תמיד זה המצב וכדי לפתור את הבעיה נהוג להשתמש במדד F1 score. כדי לחשב את ה-F1 score צריך להכיר עוד שני מדדים, שיעור ה-recall, ושיעור ה-precision.
Recall (רגישות)
Recall היא הפרופורציה של דוגמאות חיוביות שהמודל זיהה (true positive) מכל הדוגמאות החיוביות במציאות.
![]()
שמות נוספים ל-recall הם: true positive rate וגם sensitivity.
נחזור לדוגמה שלנו. Recall עונה על השאלה מה שיעור החולים שהמודל זיהה נכונה מתוך כלל אוכלוסיית החולים בפועל.
נחשב את שיעור ה-recall עבור הדוגמה שלנו:
![]()
המדד recall מודד את רגישות המודל, והערך הגבוה ביותר שהוא יכול לקבל הוא 1. בגלל שהערך שחישבנו עבור המודל הוא קרוב ל-1 נאמר על המודל שהוא רגיש.
Precision
Precision הוא היחס של תצפיות חיוביות שהמודל זיהה נכונה מכל התצפיות שהמודל זיהה שהם חיוביות (בצדק או שלא בצדק).
![]()
בדוגמה שלנו, Precision עונה על השאלה מה שיעור החולים בקרב מי שהמודל סיווג כחולים?
![]()
המדד precision מודד את דיוק המודל, והערך הגבוה ביותר שהוא יכול לקבל הוא 1. בגלל שהערך שחישבנו עבור המודל הוא קרוב ל-1 נאמר על המודל שהוא מדויק.
בעברית המילים accuracy ו-precision מתורגמות שניהם לדיוק. אבל בלמידת מכונה צריך לדעת להבחין בין המדדים: accuracy הוא שיעור הזיהוי הנכון מתוך כל הדוגמאות (חיוביות או שליליות) בעוד precision הוא שיעור הזיהוי הנכון מתוך הדוגמאות החיוביות.
F1 score
מדד F1 עושה ממוצע הרמוני של ה-Precision וה-Recall, ובכך לוקח בחשבון את השגיאות משני הסוגים. כך נראית הנוסחה:
![]()
החישוב הוא בהתאם לנוסחת הממוצע ההרמוני.
נחשב את ערך F1 עבור הדוגמה שלנו:
![]()
הערך הגבוה ביותר ש-F1 יכול לקבל הוא 1. בדוגמה שלנו קיבלנו 0.97 שהוא ערך F1 גבוה מאוד שמעיד על כך שהמודל הצליח במשימת הסיווג שהוא למד.
באיזה מדד הכי כדאי להשתמש?
במדריך הסברנו 4 מדדים וכמובן שנרצה שהמודל שלנו יהיה המדויק ביותר וגם הרגיש ביותר אבל יש בעיה בגלל שה-precision וה-recall נותנים בדרך כלל תוצאות הפוכות.
התשובה הטובה ביותר היא שהמדד שבו נרצה להשתמש הוא תלוי מקרה, לדוגמה:
- אם אנחנו מעוניינים להעריך את יעילותה של ערכה לזיהוי חולי אבולה החשש הוא יותר מחולים שלא נצליח לזהות (false negative) וימשיכו להלך חופשיים ולהדביק את האוכלוסיה מאשר מזיהוי שגוי של אדם בריא כחולה במחלה (false positive). במקרה זה נרצה לעשות אופטימיזציה של המודל ל-recall. לדוגמה, על ידי הורדת הסף שמעליו נגדיר אדם כחולה.
- באופן דומה, נרצה להגביר את הרגישות של גלאי מתכות בשדה תעופה כדי למנוע עליית אנשים חמושים למטוסים. גם במקרה זה ננסה למקסם את שיעור ה-recall כי ההשלכות של false negative הם חמורות ביותר.
- במקרה של מודל לזיהוי דואר זבל, רוב האנשים יעדיפו שמיילים מסוג ספאם יגיעו אליהם לתיבת הדואר הנכנס מאשר שדואר לגטימי ילך לתיבת הספאם. בגלל שההעדפה היא ל-false positive כדאי לנו לעשות אופטימיזציה ל-precision.
לא תמיד המקרים הם כל כך ברורים ועל כן חשוב להשתמש במדד F1 בהערכת המודל מפני שהוא לוקח בחשבון את שני המדדים, recall ו- precision.

עד עכשיו טפלנו במקרה פשוט של 2 קבוצות מובחנות אבל מה לגבי 3 קבוצות מובחנות או יותר.
הערכת המודל עבור 3 קבוצות מובחנות
כפי שניתן להשתמש ב-confusion matrix והמדדים שראינו במדריך עבור 2 קבוצות מובחנות ניתן להשתמש באותם הרעיונות עבור 3 קבוצות מובחנות או יותר.
במדריך הקודם דרשנו מהמודל שפתחנו באמצעות Keras להבחין בין שלושה זני פרחים, ואילו התוצאות אותם קיבלנו כאשר סידרנו את הנתונים בתוך Confusion matrix:
| Predicted s3 | Predicted s2 | Predicted s1 | |
|---|---|---|---|
| 0 | 0 | 15 | Actual s1 |
| 1 | 10 | 0 | Actual s2 |
| 12 | 0 | 0 | Actual s3 |
- את ה-confusion matrix צריך לקרוא כטבלה. השורות הם הסיווג בפועל שהם הזנים כפי שהוגדרו במסד הנתונים. העמודות הם מספר הדוגמאות שסווגו על ידי המודל לזנים השונים.
- בכל שורה זן אחר של פרחים לפי הסיווג בפועל שאותו קיבלנו עם מסד הנתונים. השורה הראשונה שייכת לזן הראשון, השנייה לשני, וכיו"ב.
- בעמודות מופיעות מספר הדוגמאות שסווגו על ידי המודל לזנים השונים. העמודה הראשונה, את הסיווג לזן הראשון. השנייה את הסיווג לשני, וכיו"ב.
- בשורה הראשונה, 15 מתוך 15 דוגמאות שצריכות להיות מסווגות לזן הראשון אכן זוהו נכונה על ידי המודל.
- בשורה השנייה אפשר לראות שהמודל טועה ומשייך את אחת הדוגמאות לזן השלישי במקום לזן השני.
ואילו התוצאות שחישב עבורנו sklearn עבור המדדים Recall, Precision וכמובן F1.
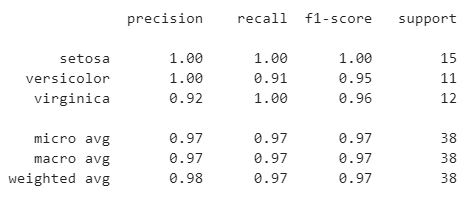
הערך הכי גבוה של המדד F1 הוא 1, ומכיוון שהתוצאה היא 1 או קרובה מאוד ל-1 עבור הקבוצות השונות אנחנו יכולים להסיק שביצועי המודל קרובים למושלמים.
לכל המדריכים בסדרה על לימוד מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.