
ניקוי תמונות מרעשים באמצעות למידת מכונה
אוטואנקודר autoencoder היא רשת נוירונית שמשחזרת את הקלט שהיא מקבלת בשכבת הפלט. לדוגמה, נזין לתוכה תמונות של ספרות והרשת תפיק תמונות של ספרות דומות כמה שניתן למקור. בעוד רשת רגילה מנסה להכליל. לדוגמה, לסדר תמונות של 70,000 ספרות ב-10 קטגוריות של מספרים, ה-autoencoder מנסה ליצור שחזור כמה שיותר אמין של המידע שהוזן לתוכו. ההבדל הזה מרשת רגילה גורם לשינוי משמעותי בארכיטקטורה. כי בעוד ברשת רגילה שכבת הקלט מכילה יותר נאורונים מאשר שכבת הפלט ב-autoencoder מספר הנוירונים בשכבת הפלט יהיה זהה לזה שבשכבת הקלט.
תרשים סכמטי של רשת autoencoder יראה כך:
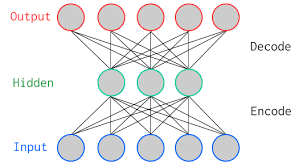
- מספר הנוירונים בשכבת הקלט input הוא גדול יותר מבשכבה החבויה, ומספר הנוירונים חוזר וגדל עד לגודל המקורי בשכבת הפלט.
- בסכמה מתוארת שכבה חבויה אחת ובמודל שנפתח במדריך נראה מספר גדול יותר של שכבות חבויות.
הרשת מורכבת משני חלקים:
- Encoder - החלק שבין הקלט לבין השכבה החבויה המרכזית. בחלק זה של הרשת המידע נדחס לייצוג מצומצם.
- Decoder - החלק שבין השכבה החבויה המרכזית לבין הפלט שבו המידע חוזר לממדים המקוריים.
השכבה החבויה כוללת מספר נמוך יותר של נוירונים מאשר השכבות שעוטפות אותה משני הצדדים. מכיוון שהרשת לומדת לשחזר את המידע, המשמעות היא שהשכבה החבויה לומדת להחזיק את המידע בייצוג דחוס המסתפק במספר קטן יותר של ממדים. איך יכול להיות שלמרות הייצוג הדחוס המידע נשמר? זה מפני שהמידע כיצד לפענח את המידע מוחזק בפרמטרים שלומד המודל.
Autoencoders יכולים לשמש לניקוי מרעשים, זיהוי אנומליות או אנליזת PCA. שימוש מעניין הוא העברת מידע בין דומיינים domain adaptation: לדוגמה, אימון המודל להציג תמונות ברזולוציה גבוהה יותר, או צביעת תמונות שחור-לבן. במדריך הנוכחי נלמד לנקות תמונות של ספרות הכתובות בכתב יד מרעשים.
לחץ כאן כדי להוריד את קובץ קוד המלא שנפתח במדריך
ייבוא הספריות הבסיסיות
import numpy as np
import matplotlib.pyplot as plt
ייבוא מסד הנתונים
מסד הנתונים הוא MNIST שכולל 70,000 תמונות של ספרות הכתובות בכתב יד.
# import the mnist dataset
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32')
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32')
נוסיף לתמונות רעש
הקוד הבא מוסיף רעש אקראי לתמונות.
# add random noise
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)
# show the first 10 noisy images
rows = 1
cols = 10
fig, ax = plt.subplots(rows,cols)
for i in range(cols):
ax[i].imshow(x_test_noisy[i].reshape(28,28))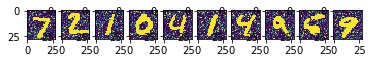
בניית המודל autoencoder
נייבא מ-Keras את הספריות שישמשו לבניית המודל.
from keras.models import Sequential
from keras.engine.input_layer import Input
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import UpSampling2D
from keras.optimizers import adadeltaנבנה את המודל בשכבות:
# the autoencoder model
model = Sequential()
# encoder
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), padding='same'))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(MaxPooling2D((2, 2), padding='same'))
# decoder
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(1, (3, 3), activation='sigmoid', padding='same'))
model.compile(optimizer='adadelta', loss='binary_crossentropy')המודל מבוסס על קונבולוציה בדומה למדריך קודם על זיהוי ספרות שכתובות בכתב יד לקריאת המדריך.
למודל יש שני חלקים. ה-encoder משתמש בשתי שכבות קונבולוציה ו-2 שכבות MaxPooling כדי לדחוס את המידע. ה-decoder משתמש גם הוא בשתי שכבות קונבולוציה ובנוסף בשתי שכבות UpSampling שמרחיבות את המידע לצורתו המקורית.
זה מבנה המודל:
Layer (type) Output Shape Param # ====================================================== conv2d_1 (Conv2D) (None, 28, 28, 32) 320 ______________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 14, 14, 32) 0 ______________________________________________________ conv2d_2 (Conv2D) (None, 14, 14, 32) 9248 ______________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 7, 7, 32) 0 ______________________________________________________ conv2d_3 (Conv2D) (None, 7, 7, 32) 9248 ______________________________________________________ up_sampling2d_1 (UpSampling2 (None, 14, 14, 32) 0 ______________________________________________________ conv2d_4 (Conv2D) (None, 14, 14, 32) 9248 ______________________________________________________ up_sampling2d_2 (UpSampling2 (None, 28, 28, 32) 0 ______________________________________________________ conv2d_5 (Conv2D) (None, 28, 28, 1) 289 ====================================================== Total params: 28,353 Trainable params: 28,353 Non-trainable params: 0
אנחנו מתחילים עם 28*28 נוירונים בקלט, שה-encoder מכווץ ל-14*14 ואח"כ ל-7*7. ה-decoder מרחיב ל-14*14 ומסיים עם מבנה של 28*28.
נריץ את המודל:
model.fit(x_train_noisy, x_train,
epochs=10,
batch_size=128,
shuffle=True,
validation_data=(x_test_noisy, x_test))
הערכת המודל
נעריך עד כמה המודל מצליח בניקוי התמונות בקבוצת הביקורת מרעשים.
x_pred = model.predict(x_test_noisy)ככה זה נראה עבור 10 הספרות הראשונות:
rows = 3
fig, ax = plt.subplots(rows,cols)
for c in range(cols):
ax[0][c].imshow(x_test[c].reshape(28,28))
ax[1][c].imshow(x_test_noisy[c].reshape(28,28))
ax[2][c].imshow(x_pred[c].reshape(28,28)) 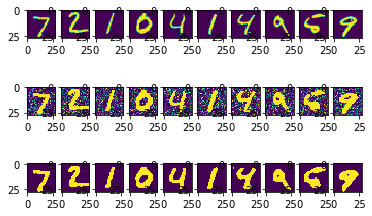
בשורה הראשונה, התמונות המקוריות. בשורה השנייה, התמונות עם הרעש, ובשורה השלישית השחזור באמצעות הרשת שפיתחנו במדריך.
השחזור נראה אמין עם כי בקווים גסים יותר מהמקור. בסך הכול תוצאה טובה בשביל 10 מחזורים בלבד.
סיכום
למדנו שמודל autoencoder מסוגל לשחזר את המידע שהוא קולט. זו תכונה שימושית כשרוצים לנקות תמונות מרעשים. אפשר גם קטעי קול. צריך לשים לב, ש-autoencoder יודע לשחזר רק את המידע שהוא קולט, והוא לא יודע להכליל. זאת אומרת, שהמודל שפתחנו במדריך כדי לנקות תמונות של ספרות מרעשים לא יצליח בניקוי תמונות של כלבים מרעשים.
פה המקום לעצור לרגע ולהבין משהו מאוד חשוב על הרשת שפתחנו במדריך והוא שהרשת הזו מעולם לא ראתה תמונות שאינן רועשות, ולמרות הכול היא מסוגלת לנקות את התמונות מרעשים. אם עד עכשיו לימדנו את הרשתות שפיתחנו מה הם צריכות להפיק. פה הרשת לומדת בעצמה. זה מרחיק אותנו מהרעיון של למידת מכונה מפוקחת supervised שבה אנחנו מגדירים לרשת את היעדים שהיא צריכה להגיע אליהם (להבדיל בין כלבים וחתולים) ומקרב לסוג של למידה בלתי מפוקחת (unsupervised) שבו הרשת מסווגת בעצמה על סמך דפוסים שאנחנו לא בהכרח מבינים והתוצאה יכולה להיות מפתיעה ואפקטיבית. אפקטיביות משמעותית במיוחד בעולם שבו אנחנו אוגרים כמויות עצומות של מידע כמעט בלא יכולת לסווג לא כל שכן להפיק תובנות משמעותיות.
במדריך הבא נשתמש ב-autoencoder כדי להפיק מידע דחוס במסגרת אנליזת PCA.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.