
האצת למידת מכונה באמצעות שלב מקדים מבוסס טרנספורמציית PCA
ניתוח גורמים ראשיים (Principal Component Analysis, PCA) היא טכניקה בה אנו משתמשים כדי להפחית את הממדיות (= מספר הפיצ'רים) של מערכי נתונים גדולים תוך שמירה על רוב השונות. כאשר, נא לזכור, השונות היא מה שמעניין אותנו במערך הנתונים. הפחתת מימדיות מקריבה דיוק ומעניקה פשטות. התוצאה היא נתונים פחות מדויקים, אבל כאלה שאנחנו יכולים בקלות לצייר מהם תרשים או להשתמש בהם כדי לאמן את המודלים שלנו בזמן קצר יותר. חשוב להבין, שהטכניקה לא משתמשת בממדים הקיימים אלא מארגנת את המידע באופן שיוצר ממדים חדשים קומפקטיים שמצליחים להכיל את המידע במספר מצומצם של ממדים דחוסים.
למה משתמשים ב-PCA?
ב-PCA משתמשים לשתי מטרות עיקריות:
- הצגה של נתונים מרובי ממדים באמצעות 2-3 ממדים. כיוון שאנחנו לא מסוגלים לתפוס יותר מ2-3 ממדים כדאי לנו להשתמש ב-PCA כדי להפחית את מספר הממדים לשניים או שלושה שאותם אנחנו יכולים לתאר באמצעות תרשים דו או תלת ממדי.
- כדי להאיץ את למידת המכונה מכיוון שקל יותר ללמוד ממספר מופחת של פיצ'רים.
במדריך זה אני בודק כיצד שימוש ב- PCA לצורך הפחתת מספר הממדים משפיע על הזמן והדיוק של אימון מודל Keras על מערך נתונים MNIST. המדריך מבוסס על מדריך קודם שלימד כיצד לפתח מודל מבוסס קונבולוציה כדי ללמד מחשב להבחין בין ספרות הכתובות בכתב יד. לקריאת המדריך שבו תלמד לפתח מודל מבוסס קונבולוציה כדי לסווג תמונות של ספרות.
במדריך נבצע טרנספורמציית PCA קודם לביצוע למידת מכונה באמצעות Keras. נשווה את התוצאות מבחינת דיוק והזמן שלוקח לתהליך לרוץ עם למידת מכונה ללא הצעד המקדים.
לחץ כאן כדי להוריד את קובץ קוד המלא שנפתח במדריך
ייבוא הספריות
הספריות להלן דרושות כדי לבצע למידת מכונה במודל מבוסס קונבולוציה באמצעות Keras:
## Import the libraries
import numpy as np
import matplotlib.pyplot as plt
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras import backend as K
# "th" format means that the convolutional kernels will have the shape (depth, input_depth, rows, cols)
# "tf" format means that the convolutional kernels will have the shape (rows, cols, input_depth, depth)
K.set_image_dim_ordering('th')השורות הבאות יאפשרו לנו לשחזר את הביצועים גם בפעם הבאה שנריץ את הקוד:
# fix random seed for reproducibility
seed = 42
numpy.random.seed(seed)
טעינת מסד הנתונים של MNIST
סט הנתונים MNIST מכיל 70,000 דוגמאות של ספרות הכתובות בכתב יד כולל התגיות של כל דוגמה. נייבא אותו:
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()נהפוך את התגיות לקטגוריות:
# one hot encode outputs
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)הפונקציה הבאה תסייע לנו לתאר באמצעות תרשים 4 דוגמאות מסט הנתונים:
# helper function to draw images and labels
def plot_images(images, labels, shape=[28,28]):
# Create figure with 2x2 sub-plots.
fig, axes = plt.subplots(2, 2)
fig.subplots_adjust(hspace=0.3, wspace=0.3)
# plot 4 images
for i, ax in enumerate(axes.flat):
# Plot image
ax.imshow(images[i].reshape(shape), cmap=plt.get_cmap('gray'))
# Plot label
for idx, val in enumerate(labels[i]):
if(val == 1):
ax.set_xlabel('Label : %d' % idx)
plt.show()נתאר את 4 התמונות הראשונות בסט הנתונים:
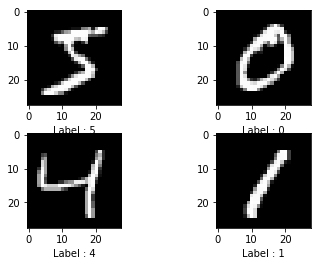
סטנדרטיזציה של המידע
סטנדרטיזציה (תיקנון) לצורך PCA משמעותה מרכוז והאחדת סטיית התקן עבור כל אחד מהפיצ'רים המרכיבים את מסד הנתונים.
- מרכוז (centering) - הופך את הממוצע לאפס.
- האחדת סטיית התקן (scaling) - גורמת לסטיית התקן להיות שווה ל-1.
סטנדרטיזציה היא חובה עבור PCA כדי שהפיצ'רים השונים יהיו באותו סולם. דוגמה נגדית היא של תהליך למידת מכונה בו אתה מנסה למצוא כיצד שטח הדירה ומספר החדרים משפיעים על מחיר הדירה. אם לא תתקנן רוב ההשפעה תהיה של שטח הדירה כי הוא גדול בשני סדרי גודל (לדוגמה, 100 מ"ר בשביל 4 חדרים).
את התיקנון תעשה בשבילנו פונקציה של sklearn. ניצור אובייקט של StandardScaler.
במדריך קודם כתבתי על השלבים בהפעלת פונקציות של sklearn אשר משותפים לכל הפונקציות השייכות לספרייה.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()התמונות שלנו דו-מימדיות אבל המידע המוזן לפונקציה צריך להיות חד ממדי, אז את התמונות נשטח.
# check the shape of data
x_test.shape(10000, 28, 28)
# For the scaler to work we need to reshape the data to 1-d
x_train_flattened = x_train.reshape(x_train.shape[0], 28*28).astype('float32')
x_test_flattened = x_test.reshape(x_test.shape[0], 28*28).astype('float32')והתוצאה היא:
print(x_train_flattened.shape)
print(x_test_flattened.shape)(60000, 784) (10000, 784)
כן, זה הצליח. קיבלנו רצועה שגובהה פיקסל 1 ורוחבה 784 פיקסלים במקום תמונה של 28 * 28 פיקסלים.
הפונקציה לומדת מסט הנתונים המיועד לאימון ומיישמת את הטרנספורמציה על סט האימון והמבחן.
# Fit on training set only
scaler.fit(x_train_flattened)StandardScaler(copy=True, with_mean=True, with_std=True)
# Apply transform to both the training set and the test set
x_train_scaled = scaler.transform(x_train_flattened)
x_test_scaled = scaler.transform(x_test_flattened)לעשות PCA
את ה-PCA נעשה באמצעות פונקציה אותה נייבא מ-sklearn.
from sklearn.decomposition import PCAהפרמטר שנעביר לפונקציה כדי ליצור אובייקט pca הוא שיעור השונות שצריך לשמר. במקרה זה, שיעור השימור הוא 95%.
# Make an instance of the Model
# Let the function choose the number of components
# that reduces the dimensions yet saves 95% of the variance
pca = PCA(.95)נאמן את אובייקט ה-PCA על סט האימון:
# train the PCA object on the training set
x_train_reduced = pca.fit_transform(x_train_scaled)מעניין לכמה פיצ'רים הצליחה להקטין הפונקציה:
# find out how many components PCA chose
# pca.n_components_
x_train_reduced.shape(60000, 331)
כלומר, האלגוריתם הצליח לצמצם את מספר הפיצ'רים מ-784 ל-331 בלבד ועדיין לשמור על 95% מהשונות המקורית. מדהים!
אנחנו עושים PCA בשביל לצמצם את מספר הממדים של הדוגמאות כדי לאמן עליהם את המודל בזמן קצר יותר. בשלב קודם, הפכנו את הדוגמאות לחד-מימדיות (גובה של פיקסל 1 ואורך של 784) אבל המודל של למידת מכונה שניצור בהמשך באמצעות Keras הוא מבוסס קונבולוציה מה שאומר שהוא צריך להיות מוזן בדוגמאות דו-ממדיות (בעלות רוחב וגובה). אם נוציא שורש מ-331 נראה שהמספר שאנחנו מקבלים אינו שלם (18.2) אבל אנחנו חייבים לבטא את ממדי התמונה בפיקסלים שלמים. כדי לפתור את הבעיה נעגל כלפי מעלה ל-19 ואת ה-PCA נעשה במטרה שיפחית את מספר המימדים ל-19 בריבוע (=361 מימדים).
נעביר לקונסטרקטור של פונקצית ה-PCA את הפרמטר n_components=361 ועל האובייקט שיתקבל נאמן את הנתונים שלנו בידיעה שנשמור על 95% מהשונות המקורית וגם נקבל סט נתונים המכיל 19 * 19 מימדים שעליו נוכל לאמן את המודל מבוסס הקונבולוציה בהמשך.
# since 331 has square root of 18.2 and I work with pixels that have to be integers
# I use n_components of 19*19 = 361
pca1 = PCA(n_components=361)כרגיל בפונקציות של sklearn נאמן על סט נתוני האימון:
# Fit PCA on training set
pca1.fit(x_train_scaled)PCA(copy=True, iterated_power='auto', n_components=361, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
ניישם את הטרנספורמציה שהאובייקט למד על כל הנתונים.
# Apply the mapping (transform) to both the training and test sets
x_train_reduced1 = pca1.transform(x_train_scaled)
x_test_reduced1 = pca1.transform(x_test_scaled)נבדוק שאכן הטרנספורמציה נעשתה על פי הפרמטר שהעברנו לפונקציה::
x_train_reduced1.shape(60000, 361)
כן. זה עובד. התחלנו עם 784 מימדים, ואחרי הטרנספורמציה שעשתה פונקצית ה-PCA נשארנו עם 361 מימדים בלבד.
לפני שנוכל לאמן את מודל הקונבולוציה צריך לסדר את הדוגמאות במבנה דו-ממדי של 19 * 19 פיקסלים.
# reshape before feeding the convolutional model since it is only able to work with 3D samples
x_train_2d = x_train_reduced1.reshape(x_train_reduced1.shape[0], 1, 19, 19).astype('float32')
x_test_2d = x_test_reduced1.reshape(x_test_reduced1.shape[0], 1, 19, 19).astype('float32')נבחן את הצורה אחרי השינוי לעיל:
x_train_2d[0].shape(1, 19, 19)
פששש. איזו רדוקציה מטורפת. מעניין איך נראות התמונות של הספרות:
plot_images(x_train_2d[:4], y_train[:4],[19,19])
טרנספורמציית ה-PCA הפכה את התמונות של הספרות למשהו שנראה לי כמו רעש רנדומלי. אני מקווה שהמחשב יצליח ללמוד למרות הכול.
מודל מבוסס קונבולוציה לצורך למידת מכונה
הקוד להלן אינו חדש, ופיתוחו הוסבר בהרחבה במדריך זיהוי ספרות שכתב אדם על ידי בינה מלאכותית - פיתוח המודל. הבדל אחד קטן הוא שממדי התמונות הם 19 * 19.
# deep learning model that needs to learn to connect the labels with the images
K.clear_session()
def baseline_model():
# create model
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(1, 19, 19), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))# compile the model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model# build the model
model = baseline_model()פונקצית "עצירה מוקדמת" עוצרת את תהליך הלמידה במידה והוא אינו מתקדם יותר.
# early stopping stops the learning process in the case that the process doesn't progress for 2 epochs
# or in the case of over fitting to the training data over the validation data
from tensorflow.keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=2,
verbose=1,
mode='auto')למידה בפועל:
# Fit the model
history = model.fit(x_train_2d,
y_train,
validation_data=(x_test_2d,y_test),
callbacks = [es],
epochs=1000,
batch_size=200,
verbose=1)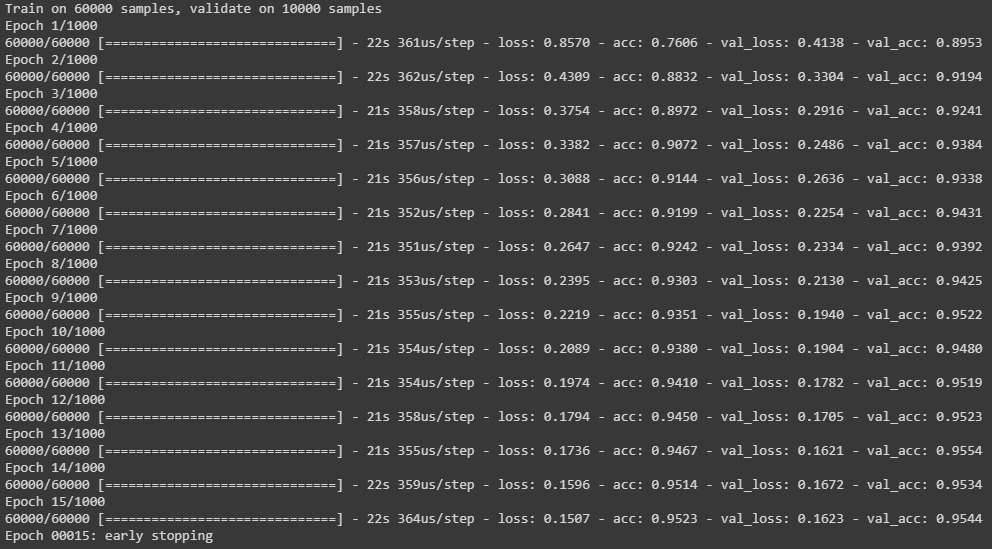
הערכת ביצועי המודל
הקוד הבא יעריך את ביצועי המודל:
model.evaluate(x_test_2d, y_test)[0.16234565799888223, 0.9544]
נעשה סיכום ביניים. לא רק במשחק ה-GO והשחמט, גם בסיווג תמונות של ספרות הכתובות בכתב יד הצליחה המכונה להביס את האדם ולסווג תמונות שנראות לי לא יותר מבלאגן אחד גדול ורועש. מידת הדיוק היא 95.44% והמודל רץ במשך 319 שניות על סביבת colab - CPU
מעניין להשוות לסט הנתונים שלא עבר את הטרנספורמציה באמצעות PCA.
השוואה למודל שלא עבר טרנספורמציה של מסד הנתונים באמצעות PCA
הקוד להלן לומד מסט הנתונים המקורי, שלא עבר רדוקציה באמצעות PCA.
הקוד להלן אינו חדש, ופיתוחו הוסבר בהרחבה במדריך זיהוי ספרות שכתב אדם על ידי בינה מלאכותית - פיתוח המודל. מימדי התמונות הם 28 * 28.
# reshape to be [samples][pixels][width][height]
X_train = x_train.reshape(x_train.shape[0], 1, 28, 28).astype('float32')
X_test = x_test.reshape(x_test.shape[0], 1, 28, 28).astype('float32')# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255# deep learning model that needs to learn to connect the labels with the images
K.clear_session()
def baseline_model():
# create model
model = Sequential()
model.add(Conv2D(32, (5, 5), input_shape=(1, 28, 28), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# Compile model
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# build the model
model = baseline_model()history = model.fit(X_train,
y_train,
validation_data=(X_test,y_test),
callbacks = [es],
epochs=1000,
batch_size=200,
verbose=1)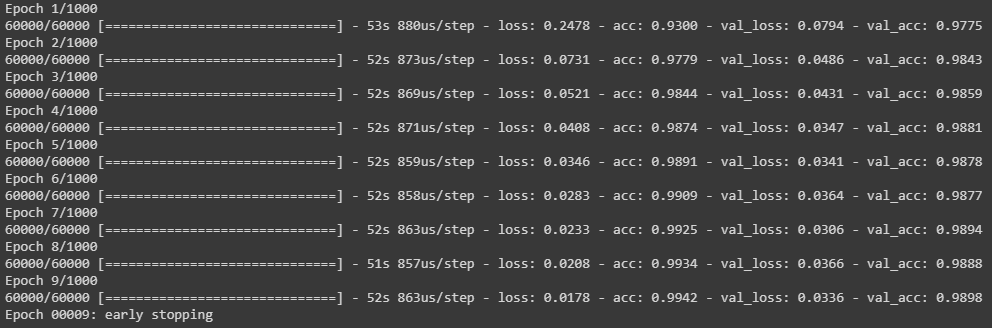
נעריך את ביצועי המודל:
model.evaluate(X_test, y_test)[0.03362984441231238, 0.9898]
דיוק של 99.98% עם זמן אימון של 468 שניות שהוא ארוך ב-47% יותר מאותו תהליך לאחר PCA. כלומר, ה-PCA הקטין את זמן העיבוד בתמורה להפחתה במידת הדיוק של המודל.
לסיכום
ראינו כיצד תמונות שעברו רדוקציה באמצעות PCA הפכו לבלתי מובנות לעין אנושית אבל עדיין המחשב הצליח לסווג אותם בהצלחה. המסקנה היא שמחשבים יכולים לזהות דפוסים במידע שנראה לנו כלא יותר מרעש חסר פשר.
שלב מקדים של PCA לפני אימון המודל יכול לקצר משמעותית את זמן האימון בתמורה לפגיעה בדיוק התוצאות. זה יכול להועיל כאשר רוצים לקצר את זמן האימון ולבחון מודל בזמן קצר כמה שיותר לפני שמחליטים האם להשקיע בו את מלוא המשאבים החישוביים.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.