
הבחנה בין קבוצות באמצעות למידת מכונה
מטרת המדריך היא ללמד את המחשב להבחין בין קבוצות מובחנות באמצעות למידת מכונה. בסופו של המדריך, נלמד להעריך את מידת הדיוק של המודל. מסד הנתונים שבו נעשה שימוש במדריך הוא של זני פרחים שהמחשב ילמד להבחין ביניהם.
להורדת הקוד המלא אותו נפתח במדריך: קובץ ipynb
ייבוא הספריות שישמשו ללמידת מכונה
import pandas as pd
import numpy as np
import seaborn as sns- ספריית Numpy של Python מאפשרת לעבוד עם מערכים רב-מימדיים, ומספקת פונקציות לביצוע פעולות של אלגברה לינארית הנדרשות לפתרון הבעיות המתמטיות בתהליך הלמידה.
- Pandas משמשת לסידור ולסינון מידע בדומה לגיליון אקסל.
- Seaborn ישמש לייבוא סט הנתונים של זני הפרחים וגם להצגת המידע באמצעות תרשימים.
בהמשך המדריך נייבא ספריות נוספות לפי הצורך.
ייבוא וסקירת סט הנתונים
את סט הנתונים המסכם נתוני מדידות מ-3 זני פרחים נייבא באמצעות seaborn.
dataset = sns.load_dataset("iris")נראה מה הנתונים כוללים:
dataset
סה"כ 149 דוגמאות של 3 זני פרחים שמדדו בהם 4 תכונות שונות.
נשתמש ב-seaborn כדי להציג את הזנים והתכונות שלהם באמצעות תרשים השוואתי:
sns.set(style='ticks')
sns.pairplot(dataset.iloc[:,0:6], hue='species')
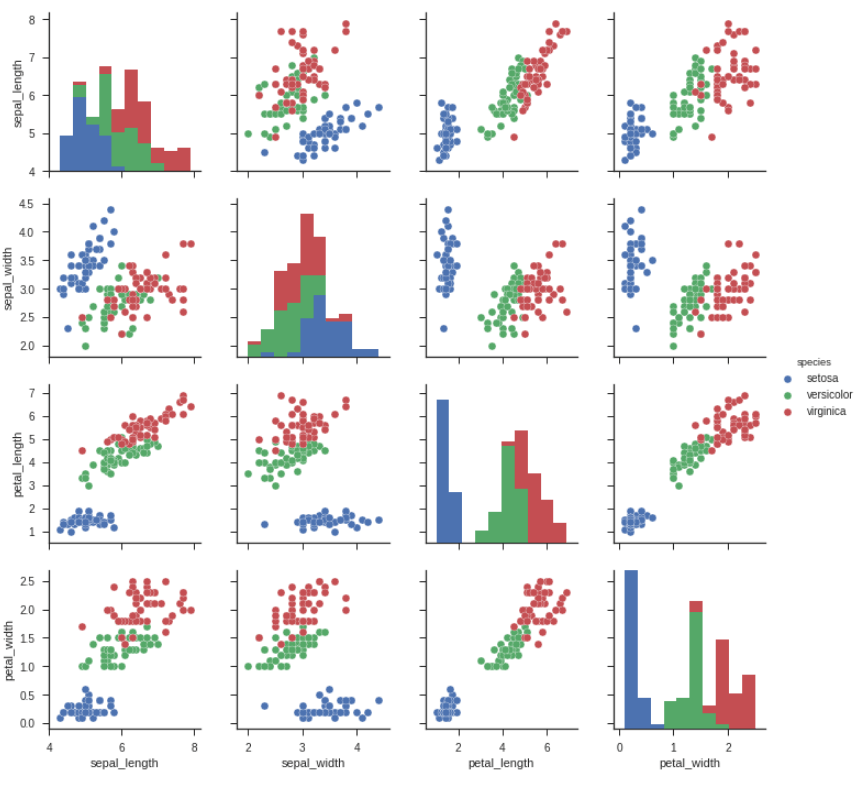
אפשר לראות שזן הפרחים הכחול נבדל משני הזנים האחרים בכל ארבעת הפרמטרים, וגם שהזנים האדום והירוק מתקבצים ביחד באופן שמקשה על ההבחנה ביניהם לבן אנוש. מעניין אם המחשב יצליח להבדיל ביניהם.
הכנת הנתונים ללמידת מכונה
נפריד את התגיות (labels) שהם עמודת זן הפרח (העמודה species) מיתר העמודות המכילות את המדידות.
x = dataset.iloc[:,0:4].values
y = dataset.iloc[:,4].valuesעמודת התגיות הם ציר ה-y ועמודות המדידות מהוות את ציר ה-x. כי אנחנו מנסים לחזות את זן הפרח מערכי המדידות.
2. בשלב זה אנחנו בבעיה כי שמות הזנים הם מחרוזות (טקסטים) אבל מחשבים יודעים לעבוד עם מספרים. הפתרון הוא להשתמש בשיטה של One hot encoding שהופכת משתנים קטגוריים סותרים (mutually exclusive) למשתנים מספריים שהמחשב יודע לעבוד איתם. מדוע סותרים? מכיוון שכל דוגמה בסט הנתונים שייכת לזן אחד מובחן ואינה תוצאה של הכלאה.
בסוף הסעיף הזה תוכלו לראות כיצד נראה סט נתונים שקודד בשיטת One hot encoding, אבל קודם נעשה את עבודת הקידוד.
נעזר ב-numpy כדי למצות את שמות הזנים ממשתנה y.
species_names = np.unique(np.array(y))
species_namesarray(['setosa', 'versicolor', 'virginica'], dtype=object)
נמיר את הרשימה למילון עם אינדקסים.
species_names_dict = {k: v for v, k in enumerate(species_names)}
species_names_dict{'setosa': 0, 'versicolor': 1, 'virginica': 2}
נשתמש ב-pandas כדי לקודד בשיטת One hot encoding, המתאימה לקידוד נתונים קטגוריים.
s = pd.DataFrame(y)
y_cat = pd.get_dummies(s)נציץ בתוצאות עבור 5 דוגמאות אקראיות:
y_cat.sample(5)
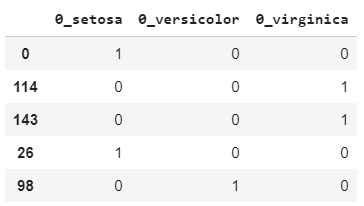
הדוגמה שמספרה 0 שייכת לזן setosa כי היא קיבלה 1 בעמודת הזן setosa ו-0 בשתי העמודות האחרות. לפי אותו היגיון, דוגמה 114 שייכת ל-virginica.
3. נפריד את הנתונים לקבוצת אימון (train) וביקורת (test) באמצעות sklearn.
X = pd.DataFrame(x)from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X.values, y_cat, test_size=0.25,random_state=42)שיעור הדוגמאות שאנחנו משתמשים בהם לקבוצת הביקורת הוא 25%, ו-random_state יכול להיות כל מספר אבל במדריכים נשתמש ב-42 כדי לקבל תוצאות עקביות.
אימון המודל
נייבא את הספריות של keras שאנחנו צריכים לצורך אימון המודל.
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import Adamהמודל הוא sequential והוא עורם (stack) שכבה ניאורונית אחת על גבי השנייה.
נבנה את המודל:
model = Sequential()
model.add(Dense(3,input_shape=(4,),activation='softmax'))
model.compile(Adam(lr=0.1),loss='categorical_crossentropy',metrics=['accuracy'])- המודל רדוד, לא עמוק, מפני שהוא מכיל שכבה חבויה אחת בלבד.
- השכבה החבויה שייכת לסוג dense, כי כל נאורון בה מחובר לכל נאורון בשכבה שלפניה.
- השכבה dense מקבלת 4 מאפיינים (features) בתור קלט (input) ומשייכת לאחת מ-3 קבוצות אפשריות בתור פלט (output).
- שכבת האקטיבציה היא softmax כי היא המתאימה ביותר לעבודה עם קטגוריות מובחנות המקודדות באמצעות one hot encoding.
- האופטימייזר הוא Adam, והוא משתמש בקצב למידה 0.1. ה-loss מוערך באמצעות categorical_crossentropy כי זו השיטה המתאימה ביותר לעבודה עם קטגוריות מובחנות.
- הערכת התקדמות תהליך הלמידה מתוארת באמצעות המדד accuracy.
לפני שנריץ את תהליך הלמידה נקבע את התנאים שבהם הוא יפסיק באמצעות הפונקציה earlyStopping שמספק Keras.
from keras.callbacks import EarlyStopping
es = EarlyStopping(monitor='val_loss',min_delta=0.001,patience=5,verbose=1,mode='auto')
לתכונה שהפונקציה מנטרת נקרא val_loss והיא ה-loss של קבוצת הביקורת, שאינה משתתפת בתהליך הלמידה עצמו אלא רק בהערכה שלו. במידה ואין שיפור במדד ה-loss במשך 5 סיבובים (epochs) התהליך נפסק.
אימון המודל יעשה באמצעות הפונקציה model.fit
model.fit(X_train, y_train, validation_data=(X_test,y_test),callbacks=[es],epochs=500)- התהליך שם בצד את קבוצת הביקורת (test) ולומד רק מקבוצת האימון (train).
- בסוף כל epoch מעריך המודל את ההתקדמות על ידי הרצת המודל כנגד דוגמאות הביקורת.
- במידה ולא מושגת התקדמות, הפונקציה es עוצרת את התהליך.
- התהליך יכול לרוץ 500 סיבובים (epochs) לכל היותר.

המודל רץ 72 סיבובים מתוך ה-500 שהקצנו לו. נראה שהוא למד מספיק. מעניין האם תחזיות המודל הם אמינות.
הערכת המודל
את יכולת הסיווג של המודל אנחנו מעריכים על קבוצת הניסוי (test) ששמרנו בצד.
קודם נביט בתוצאות הגולמיות עבור 5 הדוגמאות כדי להבין עם מה אנחנו מתמודדים:
y_pred = model.predict(X_test)
y_pred[:5]array([[3.2356910e-03, 8.9912200e-01, 9.7642273e-02],
[9.9332643e-01, 6.6735381e-03, 2.4579033e-10],
[9.4719355e-10, 3.5704824e-04, 9.9964297e-01],
[2.9540968e-03, 7.6134396e-01, 2.3570192e-01],
[1.8470370e-03, 8.6251414e-01, 1.3563886e-01]], dtype=float32)
- כל שורה מתארת את ההסתברות לשיוך לאחד משלושת הזנים עבור דוגמה אחת בקבוצת הביקורת. ההסתברות הראשונה משמאל היא שהדוגמה שייכת לזן הראשון, ההסתברות השנייה מתייחסת לזן השני והשלישית לזן השלישי.
- סכום ההסתברויות בכל שורה שווה ל-1 כי עשינו שימוש בפונקציית אקטיבציה מסוג softmax.
- התחזית של המודל היא הזן שמקבל את ההסתברות הגבוהה ביותר עבור כל דוגמה.
כיצד נמצה את התחזית של המודל עבור כל אחת מהדוגמאות? נשתמש בפונקציה של numpy ששמה argmax.
y_pred_class = np.argmax(y_pred,axis=1)נדפיס את התוצאה:
y_pred_classarray([1, 0, 2, 1, 1, 0, 1, 2, 2, 1, 2, 0, 0, 0, 0, 1, 2, 1, 1, 2, 0, 2,
0, 2, 2, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 2, 1, 0])
הרשימה שקיבלנו היא התחזית של המודל עבור כל אחת מהדוגמאות בקבוצת הביקורת.
מה שמעניין אותנו הוא להשוות את התחזית עם שמות הזנים שסופקו לנו עם סט הנתונים. לצורך כך, נעשה רשימה של שמות הזנים שקיבלנו.
y_actual_class = np.argmax(np.array(y_test),axis=1)כך נראית התוצאה:
y_actual_classarray([1, 0, 2, 1, 1, 0, 1, 2, 1, 1, 2, 0, 0, 0, 0, 1, 2, 1, 1, 2, 0, 2,
0, 2, 2, 2, 2, 2, 0, 0, 0, 0, 1, 0, 0, 2, 1, 0])
ועכשיו נעמת בין הצפוי ובין הרצוי באמצעות Confusion matrix
from sklearn.metrics import confusion_matrix
confusion_matrix(y_actual_class,y_pred_class)array([[15, 0, 0],
[ 0, 10, 1],
[ 0, 0, 12]])
- את התוצאה של ה-confusion matrix צריך לקרוא כטבלה. השורות הם הסיווג בפועל שהם הזנים כפי שהוגדרו במסד הנתונים. העמודות הם מספר הדוגמאות שסווגו על ידי המודל לזנים השונים.
- בכל שורה זן אחר של פרחים לפי הסיווג בפועל שאותו קיבלנו עם מסד הנתונים. השורה הראשונה שייכת לזן הראשון, השנייה לשני, וכיו"ב.
- בעמודות מופיעות מספר הדוגמאות שסווגו על ידי המודל לזנים השונים. העמודה הראשונה, את הסיווג לזן הראשון. השנייה את הסיווג לשני, וכיו"ב.
- בשורה הראשונה, 15 מתוך 15 דוגמאות שצריכות להיות מסווגות לזן הראשון אכן זוהו נכונה על ידי המודל.
- בשורה השנייה והשלישית הזנים כחול וירוק שהיינו בספק לגבי היכולת של המודל להבחין ביניהם. ואכן, המודל מסווג באופן שגוי דוגמה אחת מהזן השני שהוא טועה לסווג לזן השלישי. בשורה השלישית הדיוק הוא 100%.
דרך נפוצה להציג confusion matrix היא באמצעות "מפת חום" מפת חום.
את הקוד הבא העתקתי מ-github והוא מאפשר לי להציג את הנתונים באמצעות מפת חום.
# https://gist.github.com/hitvoice/36cf44689065ca9b927431546381a3f7
def cm_analysis(y_true, y_pred, filename, labels, ymap=None, figsize=(10,10)):
"""
Generate matrix plot of confusion matrix with pretty annotations.
The plot image is saved to disk.
args:
y_true: true label of the data, with shape (nsamples,)
y_pred: prediction of the data, with shape (nsamples,)
filename: filename of figure file to save
labels: string array, name the order of class labels in the confusion matrix.
use `clf.classes_` if using scikit-learn models.
with shape (nclass,).
ymap: dict: any -> string, length == nclass.
if not None, map the labels & ys to more understandable strings.
Caution: original y_true, y_pred and labels must align.
figsize: the size of the figure plotted.
"""
if ymap is not None:
y_pred = [ymap[yi] for yi in y_pred]
y_true = [ymap[yi] for yi in y_true]
labels = [ymap[yi] for yi in labels]
cm = confusion_matrix(y_true, y_pred, labels=labels)
cm_sum = np.sum(cm, axis=1, keepdims=True)
cm_perc = cm / cm_sum.astype(float) * 100
annot = np.empty_like(cm).astype(str)
nrows, ncols = cm.shape
for i in range(nrows):
for j in range(ncols):
c = cm[i, j]
p = cm_perc[i, j]
if i == j:
s = cm_sum[i]
annot[i, j] = '%.1f%%\n%d/%d' % (p, c, s)
elif c == 0:
annot[i, j] = ''
else:
annot[i, j] = '%.1f%%\n%d' % (p, c)
cm = pd.DataFrame(cm, index=labels, columns=labels)
cm.index.name = 'Actual'
cm.columns.name = 'Predicted'
fig, ax = plt.subplots(figsize=figsize)
sns.heatmap(cm, annot=annot, fmt='', ax=ax)
plt.savefig(filename)נזין את הפונקציה לעיל עם הנתונים שלנו:
cm_analysis(y_actual, y_pred, 'figur1', [0,1,2], ymap={0:'setosa',1:'versicolor',2:'virginica'})והרי התוצאה לפניכם:

המדד שמעריך את המידה שבה המודל שפתחנו מצליח בסיווג הדוגמאות נקרא f1-score. ניתן ל-sklearn לחשב את המדד בשבילנו:
from sklearn.metrics import classification_report
print(classification_report(y_test_class, y_pred_class, target_names=species_names))
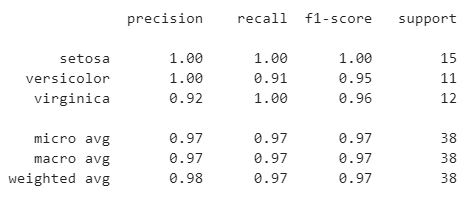
ככל ש-f1-score גבוה יותר כך הוא טוב יותר. הערך הגבוה ביותר האפשרי הוא 1, והנמוך ביותר הוא 0. בדוגמאות שלנו המדד הוא גבוה עבור כל הזנים.
האם הערך הוא מספיק גבוה? תלוי ביישום. אם המטרה היא להבחין בין זן של צמח ראוי למאכל אדם לעומת זן שעלול להרעיל את האוכלים אותו אז לא נסתפק בערך שהוא פחות מ-1.
כדי להבין את המשמעות של המדד f1-score וכיצד מחשבים אותו צריך יותר מאשר פסקה במדריך בגלל שאם נבין את האופן והמחשבה שמאחורי חישוב המדד נפתח את היכולת שלנו להעריך מידע. יכולת שהיא מהותית להבנת למידת המכונה מעבר ללמידת ספרייה כזו או אחרת. אז במדריך הבא ננסה להבין לעומק את האופן שבו אנו מעריכים את ביצועי המודל, ובכלל כך סוגי שגיאות ומדידת שיעור השגיאה. לקריאת המדריך על confusion matrix בלמידת מכונה
לכל המדריכים בסדרה על לימוד מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.