
זיהוי SMS ספאמי בעזרת RNN ומרחב הטמעה שאומן מראש
במדריך הקודם ראינו כיצד להבחין בין הודעות SMS תקינות לספאמיות באמצעות מודל RNN המתחשב בסדר המילים ומוזן על ידי שכבת הטמעה embedding אותה אימנו מאפס. יכולנו להרשות לעצמנו לאמן את הרשת מאפס בגלל שמסד הנתונים שעמד לרשותינו היה גדול מספיק. רק שלעיתים כמות הטקסט אינה מספיקה לאימון המודל ואז אפשר להשתמש במסד נתונים של וקטורי הטמעה שאומנו מראש pre-trained word embeddings, המכילים מספיק מילים והקשרים שחלקם עשויים להיות שימושיים עבור המשימה שעל הפרק. לצורך זה, קיימות מספר ספריות ידועות באנגלית, ביניהם word2vec ו-GloVe.

במסד נתונים של וקטורי הטמעה המשמעות הסמנטית של המילים מבוטאת על ידי מידת הקרבה הגיאומטרית והיחסים בין הוקטורים. לדוגמה, במרחב הטמעה סביר, הוקטורים המייצגים את צמד המילים "מלך" ו-"מלכה" יתקבצו יחדיו הרחק מצמד המילים "גמל" ו-"נאקה". בנוסף, כיוון הקשר בתוך צמדי המילים יהיה דומה כיוון שהוא מבטא יחס של מין (זכר ונקבה).

במדריך נעבוד עם ספריית Keras באמצעותה יוצרים מודלים של למידת מכונה העשויים בשכבות. המודל שלנו יכלול שכבה מסוג RNN, המתמחה במציאת קשרים בתוך רצפים, אותה תזין שכבת Embedding אשר מקודדת את המשמעות הסמנטית של כל אחד מהטוקנים על פי GloVe מסד נתונים של וקטורי הטמעה אשר אומן מראש.
במדריך זה ניישם מודל RNN בשביל למידת מכונה בשלושה שלבים:
- הפיכת מילים לטוקנים כאשר לכל טוקן ייחודי מוקצה ספרת אינדקס.
- מיפוי כל ספרת אינדקס לוקטור הנושא משמעות סמנטית במסגרת שכבת הטמעה שאומנה מראש.
- שימוש במודל RNN ללימוד קשרים בין הוקטורים ברצף.
נייבא את הספריות הדרושות ללמידת מכונה:
import numpy as np
import pandas as pdספרייה של פייתון לעבודה עם מערכת ההפעלה:
import osנשתמש ב-Keras כדי ליצור את המודל בו נשתמש לצורך למידת מכונה:
import tensorflow as tf
from tensorflow import keras
מסד הנתונים
את מסד הנתונים הורדתי כקובץ CSV מאתר Kaggle (קישור למסד הנתונים).
# import dataset
df = pd.read_csv('spam.csv', encoding = "ISO-8859-1", usecols=["v1", "v2"])
df.columns = ["Category", "Message"]
df
df.shape(5572, 2)
df.isnull().sum().sum()0
df.Category.unique()array(['ham', 'spam'], dtype=object)
df.groupby(['Category']).count()|
Category |
Message |
|---|---|
|
ham |
4825 |
|
spam |
747 |
categories = df.Category.unique() # ['ham','spam']NUM_CLASSES = len(categories) # 2מסד הנתונים כולל 5,547 הודעות SMS באנגלית המסווגות ל-2 קטגוריות: ham (לגיטימיות) או spam. הסט אינו מאוזן עם 13.5% בלבד מההודעות המסווגות ספאם.
יבוא ושימוש בספריית הטמעה שהוכנה מראש
את הדרך להשתמש בספריית הטמעה Glove במסגרת מודל Keras ביססתי על התיעוד.
נוריד את מסד הנתונים של וקטורי ההטמעה GloVe בגרסתו המכווצת ונחלץ מתוכו את הקובץ המכיל את הנתונים :
# download pre-trained GloVe embeddings
!wget https://nlp.stanford.edu/data/glove.6B.zip
!unzip -q glove.6B.zipהקובץ הינו קובץ טקסט המכיל את הוקטורים המקודדים המייצגים את 400,000 הטוקנים הנפוצים בשפה האנגלית בגרסה של וקטורים באורך 50, 100, 200 ו-300 מימדים. במדריך זה נשתמש בגרסה בת 100 הממדים.
ניצור מילון הממפה טוקנים על הוקטורים המייצגים אותם:
# the download contains encoded vectors
# of sizes: 50-dim, 100, 200, 300
# here we use the 100-dim version
# to make a dictionary mapping words to their vector
# representation
embeddings_index = {}
with open('glove.6B.100d.txt') as f:
for line in f:
word, coefs = line.split(maxsplit=1)
coefs = np.fromstring(coefs, 'f', sep=' ')
embeddings_index[word] = coefsכמה וקטורים / טוקנים במרחב ההטמעה?
# how many word vectors
print(f"Number of word vectors: {len(embeddings_index)}")Number of word vectors: 400000
מעניין איך נראה וקטור המייצג מילה מסוימת בעזרת 100 מימדים מספריים? לצורך הדוגמה בחרתי במילה האקראית "mobile".
# What's the embedding index for a word? e.g. "mobile"
print(embeddings_index['mobile'])
print(f'number of embedding dimensions {len(embeddings_index["mobile"])}')[ 1.3277e-01 -1.1802e-01 -6.3487e-02 5.8452e-02 5.4653e-01 -1.8702e-01 2.7409e-01 -4.5269e-01 3.7747e-01 4.9108e-01 1.2519e-01 -4.4236e-01 -4.0846e-01 -4.8862e-01 3.1593e-01 -7.5444e-01 4.0238e-01 2.2404e-01 2.6054e-01 1.0356e-01 1.1760e-01 -3.1270e-01 6.9717e-01 7.9034e-01 2.7629e-01 -2.8558e-01 4.8569e-01 6.1455e-01 -3.0830e-01 6.2046e-01 7.5955e-02 4.8833e-01 1.5655e-01 -1.3768e-01 1.6104e+00 -1.2606e-01 -6.0980e-01 1.7007e-01 5.1831e-01 -1.5185e-01 6.7569e-01 -1.6895e-01 -1.3517e-02 -6.5150e-02 -3.5010e-01 2.2901e-01 -3.0688e-02 6.7220e-01 1.0096e+00 -5.7403e-01 -2.2519e-01 6.9901e-01 1.9860e-01 -2.0927e-02 6.7138e-02 -1.4205e+00 -3.9847e-01 -1.8576e-01 2.0598e+00 3.6025e-01 2.7935e-01 -1.6915e-01 2.8530e-01 7.2234e-02 1.3069e-01 6.1942e-01 -1.4552e-01 -7.9057e-02 9.0466e-01 4.2882e-01 6.2880e-01 -1.6217e-01 3.7428e-01 -9.5509e-01 4.6671e-01 3.6377e-01 7.9208e-01 4.8429e-01 -3.1006e-01 -2.7141e-01 1.5868e+00 -9.1446e-01 -1.4639e-01 8.7609e-01 -1.5752e+00 -1.9979e-01 6.4625e-01 -4.0523e-01 4.8063e-01 5.2552e-01 6.7724e-01 3.3226e-01 7.7819e-01 -2.8663e-01 1.3012e-03 1.2219e-01 -2.2720e-01 1.0199e-01 1.0979e+00 -1.7951e-01] number of embedding dimensions 100
הכנת הנתונים ללמידת מכונה
כדי לעבוד עם ה-pipeline של Keras נסדר את הודעות הטקסט בתיקיות בהתאם למבנה הבא:
data/
exp_0/
test/
ham/
spam/
train/
ham/
spam/
val/
ham/
spam/
בתוך התיקייה data תהיה תיקיית הניסוי exp_0, ובתוכה 3 תיקיות ע"פ החלוקה המקובלת לקבוצת אימון מבחן ובקרה (test, train, val). בתוך כל אחת משלוש התיקיות יהיו תיקיות הקטגוריה: ham או spam. כל אחת מתיקיות הקטגוריה יחזיקו קבצי טקסט (סיומת txt) שבכל אחד מהקבצים תהיה כתובה הודעת SMS אחת.
נסדר את הקבצים בתיקיות:
BASE_DIR = './'
DATA_DIR = os.path.join(BASE_DIR, 'data/')
# make data directory
!mkdir -p ./data/!mkdir -p ./data/ham_or_spam
SRC_DIR = os.path.join(DATA_DIR, 'ham_or_spam')
!mkdir -p ./data/ham_or_spam/ham
!mkdir -p ./data/ham_or_spam/spamlen_df = len(df)
for idx, row in df.iterrows():
if idx > len_df:
break
else:
new_path = os.path.join(DATA_DIR, 'ham_or_spam', row[0], str(idx)+'.txt')
f = open(new_path, 'w')
f.write(row[1])
f.close()
idx+=1dir_list = os.listdir(SRC_DIR)
for name in sorted(dir_list):
path = os.path.join(name)
print(path)ham spam
# make data directory for the experiment
EXP_DIR = "exp_0"
!mkdir -p ./data/exp_0/# make train, val, test directories
!mkdir -p ./data/exp_0/train ./data/exp_0/val ./data/exp_0/test
TRAIN_DIR = os.path.join(DATA_DIR, EXP_DIR, "train")
VAL_DIR = os.path.join(DATA_DIR, EXP_DIR, "val")
TEST_DIR = os.path.join(DATA_DIR, EXP_DIR, "test")import os, pathlib, shutil, random
for category in categories:
if not os.path.exists(os.path.join(TRAIN_DIR, category)):
os.makedirs(os.path.join(TRAIN_DIR, category))
if not os.path.exists(os.path.join(VAL_DIR, category)):
os.makedirs(os.path.join(VAL_DIR, category))
files = os.listdir(os.path.join(SRC_DIR, category))
random.Random(42).shuffle(files)
num_val_samples = int(0.3 * len(files))
val_files = files[-num_val_samples:]
for fname in val_files:
new_fname = fname
shutil.copy2(os.path.join(SRC_DIR, category, fname),
os.path.join(VAL_DIR, category, new_fname))
train_files = files[:-num_val_samples]
for fname in train_files:
new_fname = fname
shutil.copy2(os.path.join(SRC_DIR, category, fname),
os.path.join(TRAIN_DIR, category, new_fname))for category in categories:
if not os.path.exists(os.path.join(TEST_DIR, category)):
os.makedirs(os.path.join(TEST_DIR, category))
files = os.listdir(os.path.join(VAL_DIR, category))
random.Random(42).shuffle(files)
num_val_samples = int(0.33 * len(files))
val_files = files[:num_val_samples]
for fname in val_files:
new_fname = fname
shutil.move(os.path.join(VAL_DIR, category, fname),
os.path.join(TEST_DIR, category, new_fname))נוודא את מה שעשינו:
for category in categories:
file_count = len(os.listdir(os.path.join(TRAIN_DIR, category)))
print(f"TRAIN {category} has {file_count} files")
file_count = len(os.listdir(os.path.join(VAL_DIR, category)))
print(f"VAL {category} has {file_count} files")
file_count = len(os.listdir(os.path.join(TEST_DIR, category)))
print(f"TEST {category} has {file_count} files")- סה"כ 6 תיקיות.
נייבא את התיקיות ל- Keras במבנה של אצוות batches תוך התחשבות בקטגוריות:
batch_size = 32
train_ds = keras.utils.text_dataset_from_directory(
os.path.join(DATA_DIR, EXP_DIR, "train"),
label_mode="categorical",
batch_size=batch_size
)
val_ds = keras.utils.text_dataset_from_directory(
os.path.join(DATA_DIR, EXP_DIR, "val"),
label_mode="categorical",
batch_size=batch_size
)
test_ds = keras.utils.text_dataset_from_directory(
os.path.join(DATA_DIR, EXP_DIR, "test"),
label_mode="categorical",
shuffle=False,
batch_size=batch_size
)Found 3901 files belonging to 2 classes. Found 1121 files belonging to 2 classes. Found 550 files belonging to 2 classes.
התוצאה הינה generator. נציץ בו:
for inputs, targets in train_ds:
print("inputs.shape:", inputs.shape)
print("inputs.dtype:", inputs.dtype)
print("targets.shape:", targets.shape)
print("targets.dtype:", targets.dtype)
print("inputs[0]:", inputs[0])
print("targets[0]:", targets[0])
breakinputs.shape: (32,) inputs.dtype: targets.shape: (32, 2) targets.dtype: dtype: 'float32' inputs[0]: tf.Tensor(b'Hi Petey!noixc3xa5xc3x95m ok just wanted 2 chat coz avent spoken 2 u 4 a long time-hope ur doin alrite.have good nit at js love ya am.x', shape=(), dtype=string) targets[0]: tf.Tensor([1. 0.], shape=(2,), dtype=float32)
כיוון שמחשבים לא יודעים לעבוד עם טקסט צריך להפוך את התכנים לוקטורים המייצגים כל אחד טוקן אחר (המונח token מקביל פחות או יותר למילה). תהליך ההפיכה לוקטורים מכונה וקטוריזציה. נעזר בשכבת TextVectorization כדי לעשות וקטוריזציה אשר תמפה כל טוקן ייחודי על ספרת אינדקס משלה.
קודם שנערוך וקטוריזציה עלינו למצוא את האורך המקסימלי של הוקטורים המקודדים מפני שזה יהיה האורך של הוקטורים אותם נזין לרשת הנוירונית בגלל ש-RNN מסוגל לעבוד רק עם רצפים בעלי אורך זהה. כדי לקבל רצפים באורך זהה ראשית נקבע את האורך הרצוי, ואחר כך נעבור על כל אחד מהרצפים ונקטע רצפים ארוכים מדי או נרפד באפס רצפים קצרים מדי. בחירה מושכלת של האורך חשובה מפני שרצפים ארוכים מדי גורמים להאטה משמעותית של התהליך ולמהילת הסיגנל, בעוד רצפים קצרים מדי עלולים לפספס את החלקים האינפורמטיביים ביותר אם הם נמצאים במורד הרצף באותו חלק שנקטע. כדי למצוא את האורך המקסימלי של הוקטורים המקודדים נחשב את מספר המילים הממוצע ברצפים, ולכך נוסיף 2 סטיות תקן כדי להצליח לקודד את מלוא האורך של כ- 97% מהרצפים (תחת הנחה של התפלגות נורמלית):
import math
messages = df.Message.values
lengths = [len(msg.split()) for msg in messages]
arr = np.array(lengths)
mean = np.mean(arr, axis=0)
stdev = np.std(arr, axis=0)
max_len = math.floor(mean + 2 * stdev)
print("mean: ", mean)
print("stdev: ", stdev)
print("max_len: ", max_len)mean: 15.494436468054559 stdev: 11.328410463078066 max_len: 38
- האורך הממוצע של הודעת טקסט הוא 15.5 מילים וסטיית התקן 11.3 מילים. נוסיף 2 סטיות תקן לממוצע, ונקבל שאורך הוקטורים המקודדים צריך להיות 38 מילים כדי ללכוד את האורך המלא של כ-97% מההודעות.
בהתאם נקבע את האורך המקסימלי של הוקטורים המקודדים ל-38 טוקנים:
MAX_SEQUENCE_LEN = 38במהלך הוקטוריזציה רצפים ארוכים מ-38 טוקנים יקוצצו ורצפים קצרים יותר "ירופדו" באפסים לצורך השלמת אורכם. בסיומו יקבלו כל הוקטורים המקודדים אורך אחיד של 38 טוקנים.
נגדיר את מספרם של הטוקנים באוצר המילים הכללי על 20,000 לכל היותר כי זה המספר המקובל עבור משימות NLP:
MAX_TOKENS = 20000נאתחל את המתודה של Keras שתעשה וקטוריזציה:
from keras import layers
# vectorization layer
text_vectorization = layers.TextVectorization(
max_tokens=MAX_TOKENS,
output_mode="int",
output_sequence_length=MAX_SEQUENCE_LEN,
)תהליך וקטוריזציה כולל:
- סטנדרטיזציה standardization של טקסטים במסגרתה הופכות כל האותיות לקטנות, מוסרים סימני הפיסוק, ומוסרים תווים לא סטנדרטיים.
- הפיכה לטוקנים tokenization על ידי חיתוך הרצף ברווחים שבין המילים.
- אינדוקס indexing המקנה לכל טוקן מספר אינדקס ייחודי (עד למספר מקסימום של 20,000 טוקנים)
נוסף לכך, העברנו למתודה שתפקידה להפוך רצפים לוקטורים TextVectorization() את הפרמטר:
- output_mode="int" - אשר מאנדקס את הטוקנים על ידי כך שהוא יוצר מילון אשר ממפה כל טוקן ייחודי על סיפרת אינדקס ייחודית. שני האינדקסים הראשונים במילון שמורים לטוקנים מיוחדים: הטוקן שמספר האינדקס שלו 0 מוקצה לריפוד padding, הטוקן שמספר האינדקס שלו 1 מוקצה למילה לא קיימת במסד הנתונים (מסומן [UNK]), וכל יתר הטוקנים מוקצים על פי מידת השכיחות. קודם השכיחים ביותר.
נאמן את Keras על סט נתוני האימון בלבד באמצעות המתודה adapt():
# prepare a text only dataset
text_only_train_ds = train_ds.map(lambda x, y: x)
# the adapt method needs to learn
# to vectorize only on the train dataset
text_vectorization.adapt(text_only_train_ds)נבחן את הפונקציה שתפקידה לעשות וקטוריזציה על הטקסט הבא:
# vectorize a test sentence
output = text_vectorization([["i love the amiga"]])
print(output)tf.Tensor( [[ 2 66 6 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]], shape=(1, 38), dtype=int64)
המידע נמצא בתוך טנסור של TensorFlow. נחלץ אותו לפורמט שיהיה לנו קל יותר לעבוד איתו:
print(output.numpy()[0])[ 2 66 6 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
- אורך הוקטור המקודד הוא 38 פיקסלים
- הפונקציה שיצרה את הוקטור שיבצה בכל עמדה את ספרת האינדקס של הטוקן המתאים מתוך אוצר המילים
מה במילון אוצר המילים?
# a dict mapping words to their indices
vocab = text_vectorization.get_vocabulary()
word_index = dict(zip(vocab, range(len(vocab))))
word_index{'': 0,
'[UNK]': 1,
'i': 2,
'to': 3,
'you': 4,
'a': 5,
'the': 6,
…
'mobiles': 992,
'mistake': 993,
'men': 994,
'meh': 995,
'march': 996,
'loves': 997,
'login': 998,
'loan': 999,
...}
- הטוקן שמספר האינדקס שלו 0 מוקצה לריפוד padding, ומשמש להשלמת הרצף במקרה של רצפים קצרים מדי.
- הטוקן שמספר האינדקס שלו 1 מוקצה לכל המילים שלא קיימת במסד הנתונים (מסומן [UNK])
- כל יתר הטוקנים מוקצים על פי מידת השכיחות. קודם השכיחים ביותר. לכן הראשונים להופיע הם: 'i', 'to', 'you', 'a', 'the'
- הטוקנים מכילים אותיות קטנות לטיניות סטנדרטיות ומספרים בלבד. ללא סימני פיסוק ורווחים. בהתאם, נמצא במילון את הטוקן 'i' ולא 'I'.
נהפוך את ה-keys וה-values של מילון אוצר המילים:
inv_word_index = {v: k for k, v in word_index.items()}
inv_word_index{0: '',
1: '[UNK]',
2: 'i',
3: 'to',
4: 'you',
5: 'a',
6: 'the',
…
מה הפריט האחרון במילון אוצר המילים ההפוך?
print("last item key: ", list(inv_word_index)[-1])
print("last item value: ", inv_word_index[list(inv_word_index)[-1]])last item key: 7783 last item value: 0089my
נבחן את המתודה המקודדת שלנו על ידי הזנת הטקסט הקצר הבא:
# vectorize a test sentence
output = text_vectorization([["i love the amiga"]])
print(output)
# extract the array from the tensor
print(output.numpy()[0])tf.Tensor( [[ 2 66 6 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]], shape=(1, 38), dtype=int64) [ 2 66 6 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
- קיבלנו מערך של 38 טוקנים כאשר רק 4 הראשונים מקודדים כי זה מספר המילים במשפט לדוגמה, וכל היתר הם ריפוד באפס.
נשחזר את המשפט מתוך הוקטור המקודד:
np_outputs = output.numpy()[0]
words = []
for token in np_outputs:
if inv_word_index[token]:
words.append(inv_word_index[token])
print(' '.join(words))i love the [UNK]
- המילה האחרונה היא [UNK] בגלל שהמילה "amiga" לא קיימת באוצר המילים.
ניישם את המתודה שעושה וקטוריזציה על 3 מסדי הנתונים - אימון, מבחן והערכה:
# vectorize the 3 datasets
vectorized_train_ds = train_ds.map(
lambda x, y: (text_vectorization(x), y))
vectorized_val_ds = val_ds.map(
lambda x, y: (text_vectorization(x), y))
vectorized_test_ds = test_ds.map(
lambda x, y: (text_vectorization(x), y))מה קיבלנו?
for inputs, targets in vectorized_train_ds:
print("inputs.shape:", inputs.shape)
print("inputs.dtype:", inputs.dtype)
print("targets.shape:", targets.shape)
print("targets.dtype:", targets.dtype)
print("inputs[0]:", inputs[0])
print("targets[0]:", targets[0])
breakinputs.shape: (32, 38) inputs.dtype: dtype: 'int64' targets.shape: (32, 2) targets.dtype: dtype: 'float32' inputs[0]: tf.Tensor( [ 43 10 937 4 5 151 73 2718 244 11 85 14 388 8 71 218 2 61 4286 4 388 25 3068 3 49 3 151 5516 19 12 7035 8 42 4172 12 1358 10 215], shape=(38,), dtype=int64) targets[0]: tf.Tensor([1. 0.], shape=(2,), dtype=float32)
- בכל אצווה 32 וקטורים מקודדים. כל אחד מהוקטורים מכיל 38 מספרים שלמים integers.
נמפה כל אחד מהטוקנים שמקורו במסד הנתונים של הודעות ה-SMS המונה 7884 מילים על הוקטור המייצג אותו במרחב ההטמעה GloVe:
embedding_dim = 100
max_tokens = 7884
# get the vocabulary from the TextVectorization method as a dictionary
vocabulary = text_vectorization.get_vocabulary()
# reverse the order of the dictionary: mapping from words to indexes
word_index = dict(zip(vocabulary, range(len(vocabulary))))
# prepare a matrix to fill the GloVe vectors
embedding_matrix = np.zeros((max_tokens, embedding_dim))
# fill each entry with the corresponding embedding vector, if exists
for word, i in word_index.items():
if i < max_tokens:
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
embedding_matrix[i] = embedding_vectorכדי לקבל תחושה לגבי הטוקנים והוקטורים המייצגים אותם נבחן את 3 הטוקנים הראשונים:
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
print(word, i, embedding_vector, '
')
if i == 3:
breakto 2 [-1.8970e-01 5.0024e-02 1.9084e-01 -4.9184e-02 -8.9737e-02 2.1006e-01 -5.4952e-01 9.8377e-02 -2.0135e-01 3.4241e-01 -9.2677e-02 1.6100e-01 -1.3268e-01 -2.8160e-01 1.8737e-01 -4.2959e-01 9.6039e-01 1.3972e-01 -1.0781e+00 4.0518e-01 5.0539e-01 -5.5064e-01 4.8440e-01 3.8044e-01 -2.9055e-03 -3.4942e-01 -9.9696e-02 -7.8368e-01 1.0363e+00 -2.3140e-01 -4.7121e-01 5.7126e-01 -2.1454e-01 3.5958e-01 -4.8319e-01 1.0875e+00 2.8524e-01 1.2447e-01 -3.9248e-02 -7.6732e-02 -7.6343e-01 -3.2409e-01 -5.7490e-01 -1.0893e+00 -4.1811e-01 4.5120e-01 1.2112e-01 -5.1367e-01 -1.3349e-01 -1.1378e+00 -2.8768e-01 1.6774e-01 5.5804e-01 1.5387e+00 1.8859e-02 -2.9721e+00 -2.4216e-01 -9.2495e-01 2.1992e+00 2.8234e-01 -3.4780e-01 5.1621e-01 -4.3387e-01 3.6852e-01 7.4573e-01 7.2102e-02 2.7931e-01 9.2569e-01 -5.0336e-02 -8.5856e-01 -1.3580e-01 -9.2551e-01 -3.3991e-01 -1.0394e+00 -6.7203e-02 -2.1379e-01 -4.7690e-01 2.1377e-01 -8.4008e-01 5.2536e-02 5.9298e-01 2.9604e-01 -6.7644e-01 1.3916e-01 -1.5504e+00 -2.0765e-01 7.2220e-01 5.2056e-01 -7.6221e-02 -1.5194e-01 -1.3134e-01 5.8617e-02 -3.1869e-01 -6.1419e-01 -6.2393e-01 -4.1548e-01 -3.8175e-02 -3.9804e-01 4.7647e-01 -1.5983e-01]
- השלישי ברשימה הוא הטוקן 'to' המיוצג ב-100 מימדים.
השני ברשימה הוא טוקן OOV (=Out Of Vocabulary) שאין וקטור המייצג אותו:
[UNK] 1 None
מודל Keras מסוג RNN אותו מזינה שכבת Embedding
המודל במדריך יהיה מסוג RNN כיוון שאנחנו מעוניינים ללמוד מהרצף. את ה-RNN תזין שכבת הטמעה Embedding שתתרגם את הטוקנים לוקטורים אותם לוקחים ממסד הנתונים המוכן מראש של וקטורי הטמעה pre-trained word embeddings
נטען את המילון הממפה את האינדקסים על וקטורי הטמעה embedding_matrix לשכבת ה-embedding:
embedding_layer = layers.Embedding(
max_tokens,
embedding_dim,
embeddings_initializer=keras.initializers.Constant(embedding_matrix),
trainable=False,
mask_zero=True,
)- חשוב להקפיא את וקטורי ההטמעה באמצעות העברת הפרמטר trainable=False אם רוצים למנוע את האימון של שכבת ה-Embedding כחלק מאימון המודל.
- כפי שראינו, הוקטוריזציה מרפדת את הרצפים הקצרים באפסים עד לאורך הרצוי. הבעיה עם הפרקטיקה הזו שהיא גורמת למהילת הסיגנל ברצפים קצרים כי אותו RNN שמגיע לקצה של רצף מלא אפסים "שוכח" את ראשית הרצף. כדי לפתור את הבעיה הוספנו לשכבת ה- Embedding את הפרמטר mask_zero=True המורה ל- RNN להתעלם מחלקי הוקטור המרופדים באפסים. את הפרמטר אנחנו מוסיפים לשכבת ה- embedding וההוראה הזו עוברת ליתר השכבות באמצעות Keras.
ניצור פונקציה לבניית המודל הכוללת שכבת RNN אותה מזינה שכבת ה-embedding:
# RNN model with an embedding layer
def get_model(max_tokens, hidden_dim):
inputs = keras.Input(shape=(None,), dtype="int64")
embedded = embedding_layer(inputs)
x = layers.Bidirectional(layers.LSTM(hidden_dim))(embedded)
x = layers.Dropout(0.25)(x)
outputs = layers.Dense(NUM_CLASSES, activation="softmax")(x)
model = keras.Model(inputs, outputs)
return modelנבנה את המודל על ידי קריאה לפונקציה:
model = get_model(MAX_TOKENS, 64)נתאר את מבנה המודל:
model.summary()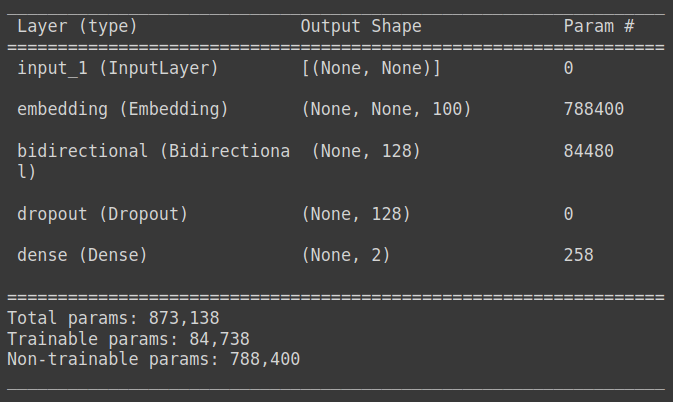
נקמפל את המודל:
model.compile(optimizer=tf.keras.optimizers.Adam(),
loss="categorical_crossentropy",
metrics=["accuracy"])נריץ את המודל:
callbacks = [
keras.callbacks.ModelCheckpoint("nlp_rnn.keras",
save_best_only=True)
]
model.fit(vectorized_train_ds.cache(),
validation_data=vectorized_val_ds.cache(),
batch_size=BATCH_SIZE,
epochs=10,
callbacks=callbacks)- נשמור את המודל בעל הביצועים הטובים ביותר אותו מצאנו במהלך האימון בקובץ קובץ "nlp_pretrained_embedding_rnn.keras" באמצעות קריאה לפונקצית callback.
- שימוש במתודה cache() של Keras עשוי לחסוך את הצורך לטעון מחדש את נתוני המידע שמקורם במסדי הנתונים בכל epoch.
הערכת ביצועי המודל
נשתמש לצורך הערכת ביצועי המודל בקונפיגורציה של המודל המאומן שהציגה את הביצועים הטובים ביותר. לשם כך, נטען את המודל:
model = keras.models.load_model("nlp_pretrained_embedding_rnn.keras")נעריך את דיוק המודל על קבוצת המבחן:
loss, acc = model.evaluate(vectorized_test_ds)18/18 [==============================] - 1s 44ms/step - loss: 0.0660 - accuracy: 0.9800
- 98% דיוק
באילו מקרים שגה המודל?
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report, f1_scorey_pred = model.predict(vectorized_test_ds)
y_pred = np.argmax(y_pred,axis=1)
y_actual = []
for bx in test_ds:
mx = np.argmax(bx[1].numpy(), axis=1)
y_actual.extend(mx)
print(confusion_matrix(y_actual, y_pred))[[471 6] [ 5 68]]
print(classification_report(y_actual, y_pred))precision recall f1-score support
0 0.99 0.99 0.99 477
1 0.92 0.93 0.93 73
accuracy 0.98 550
macro avg 0.95 0.96 0.96 550
weighted avg 0.98 0.98 0.98 550
נציץ בהודעות שהמודל שגה בסיווג שלהם:
wrong_ids = []
for idx, x in enumerate(y_actual):
if y_actual[idx] != y_pred[idx]:
print(y_actual[idx], y_pred[idx], test_ds_texts[idx])- המודל שוגה בשני אופנים: מסווג הודעות לגיטימיות כאילו היו ספאם False positive ב-6 מתוך 477 מקרים (1.25%) ומסווג הודעות ספאם כאילו היו לגיטימיות False negative ב-5 מתוך 73 מקרים (6.85%). כאשר גובר חלקו של הזיהוי השגוי בזיהוי הודעות שהם במקור ספאם בהתאמה עם המספר הנמוך יותר של דוגמאות מסוג זה שעמדו לרשות המערכת במהלך האימון.
שיעור הדיוק נראה גבוה ועומד על 98% אבל המערכת מתקשה יותר לזהות הודעות ספאם ואף מסווגת כמעט 7% מהודעות הספאם כאילו היו לגיטימיות. בנוסף, המערכת שוגה ומסווגת הודעות תקינות כאילו היו ספאם ב-1.25% מההודעות התקינות מה שיכול להיות בעייתי יותר כי משתמשים שהודעות שהם מחכים להם יגיעו לפח האשפה עלולים לאבד אימון במודל.
במדריך קודם שסיווג SMS באמצעות מודל RNN ושכבת embedding שאימנו מאפס הצלחנו להשיג דיוק גבוה יותר (כמעט 99%) אבל המודל שגה וסיווג הודעות תקינות כאילו היו ספאם. אף שאימון של שכבת embedding מאפס נתן לנו תוצאות טובות יותר צריך לקחת בחשבון שלא תמיד יהיה בידינו סט נתונים גדול מספיק שיאפשר את אימון המודל. במקרה כזה השימוש בספרייה של וקטורי הטמעה pre-trained word embeddings יכול בהחלט לעזור.
מעניין שדווקא מודל bag of words פשוט הצליח להגיע לרמת הדיוק הגבוהה ביותר (99.3%) בלי לשגות ולזהות הודעות תקינות כאילו היו ספאם.
במדריך הבא ננסה לאתר הודעות ספאם באמצעות גישה חדישה יותר של מודל מבוסס transformer.
להורדת הקוד אותו פיתחנו במדריך
מדריכים נוספים בסדרה על למידת מכונה שעשויים לעניין אותך
זיהוי SMS ספאמי בעזרת בינה מלאכותית
זיהוי SMS ספאמי באמצעות מודל RNN
מערכת שאלות-תשובות מבוססת בינה מלאכותית
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.