
מה רואות שכבות הביניים כשעושים למידת מכונה עם מודל מבוסס CNN
יש נטייה להתייחס למודלים של למידת מכונת עמוקה כאל קופסה שחורה שמכניסים לתוכה נתונים ומקבלים תחזיות בצד השני בלי יכולת להבין מה קורה באמצע. אבל בכל הנוגע לרשתות נוירונים מבוססות שכבות קונבולוציה CNN זה לא המצב. במדריך זה נראה כיצד אנחנו יכולים לראות מה מזהים הפילטרים מהם מורכבת הרשת.
את מודל למידת המכונה בו נשתמש לביצוע המשימה הסברתי במדריך "זיהוי ספרות שכתב אדם על ידי למידת מכונה" שכדאי לקרוא אותו כיוון שהוא מכיל מידע רב על מודלים של למידת מכונה ובפרט על בניית מודלים מבוססי קונבולוציה לפענוח תמונות.
נייבא את הספריות הבסיסיות:
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras- Numpy - היא ספרייה של פייתון לעבודה עם מערכים רב מימדיים.
- Matplotlib - כדי לצייר גרפים ותרשימים.
- TensorFlow בשביל למידת מכונה ו-Keras בתור הממשק הידידותי של הספרייה.
נייבא את מסד הנתונים MNIST הכולל תמונות של עשרות אלפי ספרות כתובות בכתב יד עליהם נאמן את המודל:
# load data
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()במסגרת הכנת הנתונים ללמידת מכונה ננרמל את ערכי הצבע של התמונות לערכים הנעים בין 0 ל-1 ונקודד את התגיות בשיטת one-hot encode:
# normalise inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255
# one hot encode targets
from keras.utils.np_utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
num_classes = y_test.shape[1]נציץ ב-4 התמונות הראשונות כדי לראות במה אנו עוסקים:
def plot_images(images):
# Create figure with 2x2 sub-plots.
fig, axes = plt.subplots(2, 2)
fig.subplots_adjust(hspace=0.3, wspace=0.3)
# plot 4 images
for i, ax in enumerate(axes.flat):
# Plot image
ax.imshow(images[i].reshape([28,28]), cmap=plt.get_cmap('gray'))
plt.show()
plot_images(X_train[0:4])
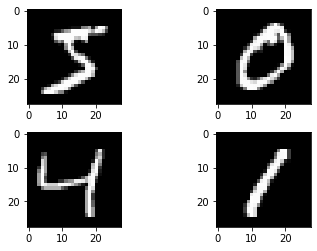
מטרת המודל לפענח איזו ספרה כתובה בכל תמונה, והוא מורכב משתי שכבות קונבולוציה:
from keras.models import Sequential
from keras import layers
def make_model():
model = Sequential()
# input
model.add(layers.Input(shape=(28, 28, 1)))
# conv block 1
model.add(layers.Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.2))
# conv block 2
model.add(layers.Conv2D(64, (3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.2))
# flatten
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
# classify
model.add(layers.Dense(num_classes, activation='softmax'))
return modelנקרא לפונקציה שבונה את המודל, נקמפל ונאמן אותו:
# Build and compile the model
model = make_model()
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
from tensorflow.keras.callbacks import ModelCheckpoint
from tensorflow.keras.callbacks import EarlyStopping
# Save the best trained model
filepath = './trained_models/mnist_model.keras'
cp = ModelCheckpoint(filepath, monitor='val_loss', verbose=1,
save_best_only=True, save_weights_only=False,
mode='auto', save_frequency=1)
es = EarlyStopping(monitor='val_loss',
min_delta=0,
patience=2,
verbose=1,
mode='auto')
# Fit the model
model.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=5, batch_size=100,
callbacks=[es, cp])אחרי שהמודל סיים את תהליך האימון, נטען את הגרסה שלו שהוכיחה את הביצועים הטובים ביותר על סט המבחן:
# load model
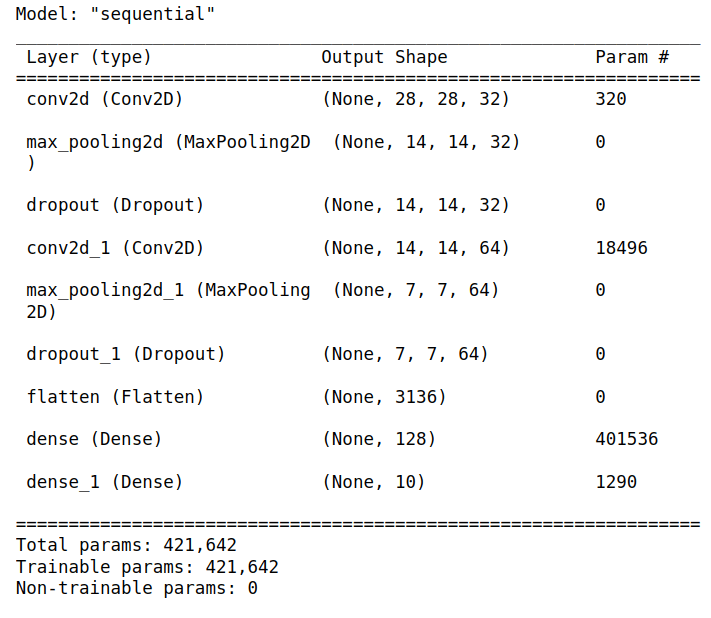
model = keras.models.load_model('./trained_models/mnist_model.keras')מה מבנה המודל?
model.summary()
על בסיס המודל המאומן ניצור מודל מקוצר הכולל רק את שכבות הקונבולוציה:
# filter outputs for the conv layers
layer_outputs = []
layer_names = []
for layer in model.layers:
if isinstance(layer, (layers.Conv2D)):
layer_outputs.append(layer.output)
layer_names.append(layer.name)
extracted_model = keras.Model(inputs=model.inputs,
outputs=layer_outputs)נטען תמונה שהמודל לא נחשף אליה במהלך האימון:
from PIL import Image
img_src = './data/my_hand_written_images/9.png'
# img = keras.preprocessing.image.load_img(img_src)
img = Image.open(img_src)
img = img.convert('L')
img_tensor = keras.preprocessing.image.img_to_array(img)
img_tensor = img_tensor.reshape([28,28])
plt.imshow(img_tensor, cmap=plt.get_cmap('gray'))
plt.show()
נזין את המודל בתמונה לעיל כאילו הייתה חלק מאצווה batch:
print(img_tensor.shape) # (28, 28)
print(np.expand_dims(img_tensor, axis=0).shape) # (1, 28, 28)# the model expects a batch so first add it
img_tensor_batch = np.expand_dims(img_tensor, axis=0)
# predict
predictions = extracted_model.predict(img_tensor_batch)התוצאה היא טנסור. נציץ בטנסור שכבת הקונבולוציה הראשונה:
first_layer_predictions = predictions[0]
print(first_layer_predictions.shape)(1, 28, 28, 32)
מבנה הטנסור משמאל לימין:
- מספר הפריטים באצווה batch הוא 1 כיוון שהזנו תמונה אחת.
- גודל התמונה הוא 28X28 פיקסלים
- 32 פילטרים סרקו את התמונה
נציג את התמונה אותה מייצר הראשון מבין 32 הפילטרים שסרקו את התמונה בשכבת הקונבולוציה הראשונה:
# predictions by the first channel
plt.matshow(first_layer_predictions[0,:,:,0], cmap="gray")
נציג את כל התמונות אותם מייצרים 32 הפילטרים שסרקו את התמונה בשכבת הקונבולוציה הראשונה:
# show the 32 feature maps in the first conv layer
cols = 8
rows = 4
fig, axes = plt.subplots(rows, cols, sharex=True, sharey=True, figsize=(28, 28))
for i, ax in enumerate(axes.flat):
ax.matshow(first_layer_predictions[0,:,:,i], cmap="gray")
ax.set_xlabel(f'filter no. {i+1}')
#plt.show()
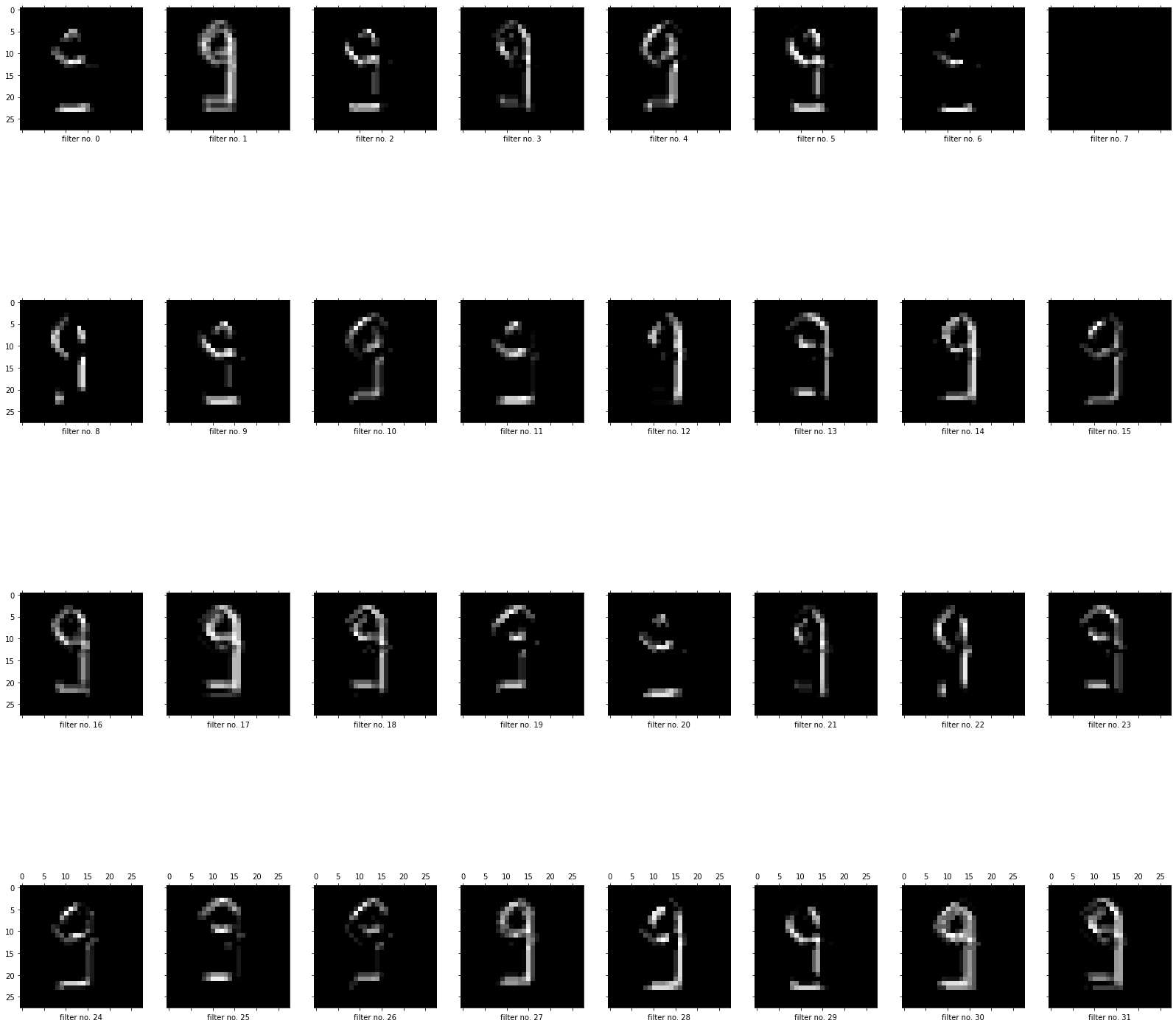
בדומה נבחן מה רואים הפילטרים בשכבת הקונבולוציה השנייה:
second_layer_predictions = predictions[1]
print(second_layer_predictions.shape)(1, 14, 14, 64)
- שכבת הקונבולוציה השנייה של המודל כוללת 64 פילטרים שכל אחד מהם בגודל של 14X14 פיקסלים.
נציג את מה שרואה כל אחד מהפילטרים בשכבת הקונבולוציה השנייה:
# show the 64 feature maps in the second conv layer
cols = 8
rows = 8
fig, axes = plt.subplots(rows, cols, sharex=True, sharey=True, figsize=(14, 14))
for i, ax in enumerate(axes.flat):
ax.matshow(second_layer_predictions[0,:,:,i], cmap="gray")
ax.set_xlabel(f'filter no. {i+1}')
#plt.show()

- ככל שהשכבות הם עמוקות יותר הדפוסים שהם רואות הם יותר מופשטים ופחות ניתנים לפרשנות. ייתכן שבגלל שהשכבות הפנימיות יודעות פחות על התמונות הקונקרטיות ויותר על מה שדרוש לרשת כדי לפענח את הסוג המופיע בתמונה במשימות סיווג.
להורדת הקוד אותו פיתחנו במדריך
מדריכים נוספים בסדרה על למידת מכונה שעשויים לעניין אותך
זיהוי ספרות שכתב אדם על ידי למידת מכונה - פיתוח המודל
חיזוי מחירי מכוניות - XGBoost, Optuna, SHAP, ועוד הרבה דברים טובים...
סיווג תמונות באמצעות מודל מאומן VGG16 על מסד נתונים שהורדנו מ-kaggle
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.