
חיזוי מחירי מכוניות - XGBoost, Optuna, SHAP, ועוד הרבה דברים טובים...
במדריך זה בסדרת למידת המכונה נלמד לחזות מחירי מכוניות. על הדרך:
- נסקור את מסד הנתונים בעזרת pandas_profiling
- נעשה רגרסיה באמצעות XGBoost
- נשפר את ביצועי המודל באמצעות Optuna
- נלמד להעריך את תוצאות המודל
- נבין את הסיבה שהמודל הגיע לתוצאות באמצעות SHAP

את הקוד המלא אותו נפתח במדריך אפשר להוריד מהמחברת המצורפת.
ייבוא התלויות
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns- numpy ,pandas - בשביל החישובים
- matplotlib ,seaborn - בשביל התרשימים
מודלים סטטיסטיים מושפעים מתהליכים אקראיים. כדי שניתן יהיה לשחזר את התוצאות אני משתמש בערך SEED שישמש את הפונקציות שמייצרות מספרים אקראיים:
SEED = 42
מסד הנתונים
את מסד הנתונים Vehicle dataset הורדתי מ-Kaggle והוא כולל את פרטיהם של 8,128 רכבים. כולל שנת הייצור, מספר ק"מ, סוג המנוע ומחיר המכירה. במדריך נחזה את מחיר המכירה על סמך יתר הנתונים.
df = pd.read_csv("data/car_dataset.csv")כמה שורות ועמודות?
df.shape(8128, 13)
נציץ בראש של מסד הנתונים:
df.head(3)
המחירים נקובים ברופי. נמיר לדולרים:
# convert the prices to dollars
df.selling_price = df.selling_price / 100כדי לסקור את מסד הנתונים נשתמש ב-pandas_profiling שעושה בשבילנו את העבודה של תיאור מסד הנתונים.
import pandas_profiling as pp
pp.ProfileReport(df)הדו"ח ש-pandas_profiling מספק כולל הרבה מידע שרק את חלקו אני מביא פה ואת כל היתר אפשר למצוא במחברת המצורפת.
נתחיל בסקירה הכללית:
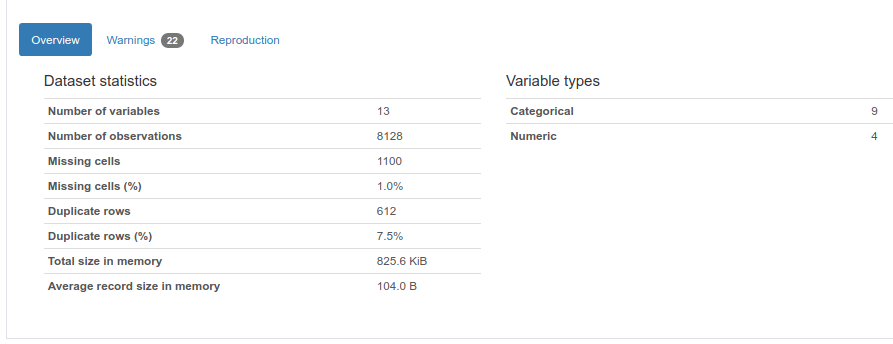
pandas_profiling מנתח כל עמודה בנפרד כדי לזהות תכונות חשובות. לדוגמה, התכונה שנת ייצור:
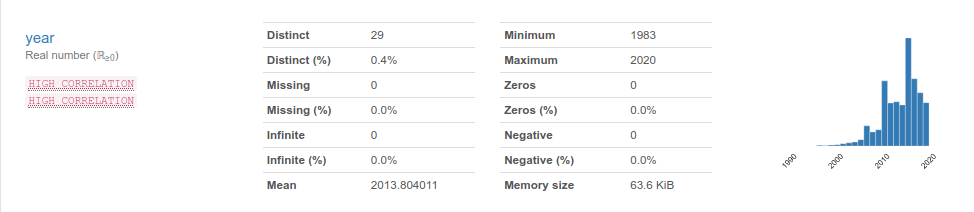
אפשר לראות:
- את ההתפלגות
- ערכים חסרים
- ערכים סטטיסטיים דוגמת ממוצע
- האם קיימת קורלציה גבוהה עם תכונות אחרות
על סמך המידע אנו יכולים לבחור האם להשתמש בעמודה. ואם משתמשים אז כיצד לעבד preprocess את המידע, וכיצד להתייחס אליו אחר כך בתוצאות שנקבל.
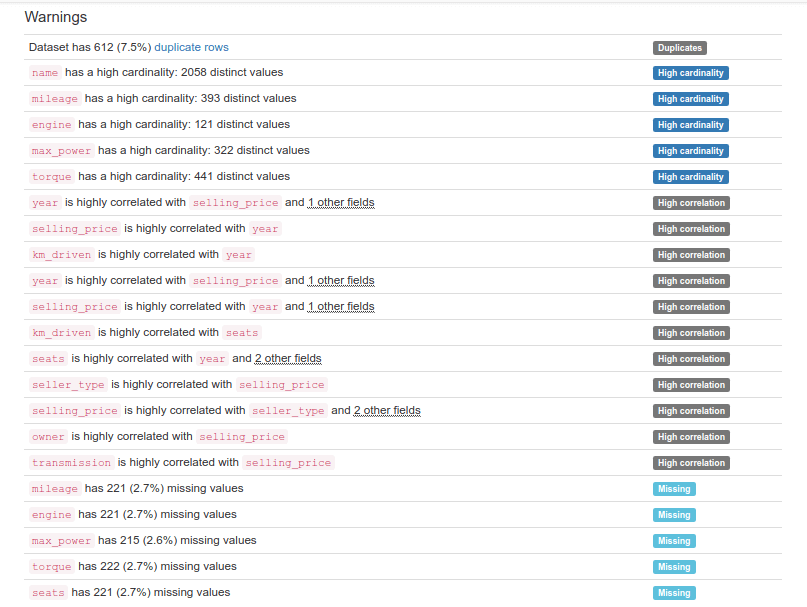
בלשונית Warnings אנחנו יכולים ללמוד על בעיות בנתונים:
בפרק המוקדש לקורלציות אפשר לגלות קשרים מעניינים בין העמודות:
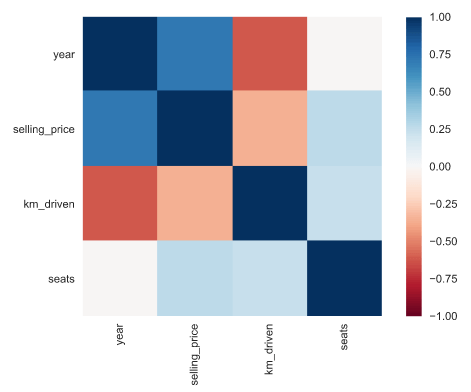
- לדוגמה, קיים קשר חזק בין מחיר ושנת ייצור וקשר הפוך עם מספר הק"מ.
הכנת הנתונים לעבודה עם XGBoost
הפונקציות הבאות שימשו להכנת מסד הנתונים:
def remove_unit(df,colum_name) :
t = []
for i in df[colum_name]:
number = str(i).split(' ')[0]
t.append(float(number))
return tdef preprocess(df):
df_clean = df.dropna().reset_index(drop=True)
df_clean.drop(['name' ,'torque', 'max_power'], axis=1,inplace=True)
# remove units
df_clean['engine'] = remove_unit(df_clean,'engine')
df_clean['mileage'] = remove_unit(df_clean,'mileage')
# df_clean['max_power'] = remove_unit(df_clean,'max_power')
# remove categories which are not 'Diesel' or 'Petrol'
df_clean = df_clean[df_clean.fuel != 'CNG']
df_clean = df_clean[df_clean.fuel != 'LPG']
categorical_columns = ['fuel', 'seller_type', 'transmission', 'owner']
for cname in categorical_columns:
dummies = pd.get_dummies(df_clean[cname], prefix=cname)
df_clean = pd.concat([df_clean, dummies], axis=1)
df_clean.drop([cname], axis=1, inplace=True)
return df_cleanנקרא לפונקציה שמנקה את מסד הנתונים:
df_clean = preprocess(df)מה עשינו?
- הסרנו את האינדקס.
- הסרנו עמודות שהראו מספר גדול של משתנים וחוסרים.
- הסרנו את היחידות מ-2 עמודות בעזרת ביטוי רגולרי.
- השארנו רק דוגמאות שמשתמשות במנועי דיזל או בנזין היות ומספר של כל היתר זניח.
- קודדנו בגישה של one hot encode את העמודות הקטגורית.
נוודא את מסד הנתונים:
df_clean.info()Int64Index: 7819 entries, 0 to 7905 Data columns (total 18 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 year 7819 non-null int64 1 selling_price 7819 non-null float64 2 km_driven 7819 non-null int64 3 mileage 7819 non-null float64 4 engine 7819 non-null float64 5 seats 7819 non-null float64 6 fuel_Diesel 7819 non-null uint8 7 fuel_Petrol 7819 non-null uint8 8 seller_type_Dealer 7819 non-null uint8 9 seller_type_Individual 7819 non-null uint8 10 seller_type_Trustmark Dealer 7819 non-null uint8 11 transmission_Automatic 7819 non-null uint8 12 transmission_Manual 7819 non-null uint8 13 owner_First Owner 7819 non-null uint8 14 owner_Fourth & Above Owner 7819 non-null uint8 15 owner_Second Owner 7819 non-null uint8 16 owner_Test Drive Car 7819 non-null uint8 17 owner_Third Owner 7819 non-null uint8
- כל העמודות מספריות
- לא חסרים נתונים
נראה שהנתונים מוכנים ל-XGBoost.
נפריד את המשתנים התלויים והבלתי תלויים:
# separate into dependent and independent variables
y = df_clean.pop('selling_price')
X = df_cleanנפריד לשלושה סטים: אימון, מבחן, ולידציה.
# split into train, val and test datasets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=SEED)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, train_size=0.8, random_state=SEED)
אימון המודל הראשוני
לפני שנעשה אופטימיזציה אנחנו צריכים בסיס להשוות אליו. אז נאמן מודל ללא כל אופטימיזציה:
import xgboost as xgbxgb_regressor = xgb.XGBRegressor(objective="reg:squarederror",
n_estimators=1000,
random_state=SEED)
xgb_regressor.fit(X_train, y_train,
eval_set=[(X_val, y_val)],
early_stopping_rounds=10,
eval_metric=['rmse'], verbose=True)- המטרה של המודל היא רגרסיה ולפי זה נגדיר את הפרמטר objective. קיימות מטרות אחרות עליהם כדאי לקרוא בתיעוד של XGBoost. באופן כללי, הקידומת, 'reg' מתייחסת לרגרסיה ו-'binary' לסיווג.
- מודלים של XGBoost מורכבים מעצי החלטה. כל עץ נותן תחזית משל עצמו, וסיכום התחזיות בתהליך המכונה הצבעה voting נותן את תחזית המודל. הפרמטר n_estimators קובע למודל כמה עצים לייצר. כמות גדולה מדי תגרום להתאמת יתר overfitting ומעט מדי תגרום להתאמת חסר underfitting.
- הפונקציה fit רצה מספר פעמים. כל ריצה נקראת boosting round. מספר הפעמים נקבע על פי התקדמות המודל. במקרה שלנו, הפונקציה נעצרת רק במידה ולא הושג שיפור בתוצאות במשך 10 מחזורים (early_stopping_rounds).
- המודל מתאמן על סט האימון בכל סיבוב ובסוף הסיבוב הוא מבצע הערכה על סט נתוני הבדיקה (eval_set). מידת ההתקדמות נמדדת ביחידות RMSE. בתיעוד של XGBoost אפשר לקרוא על eval_metric נוספים.
במהלך האימון, המודל רץ 72 מחזורים בהם ה-RMSE ירד מ-7,308 ל-1,798.
נעריך את ביצועי המודל על סט המבחן שלא נטל חלק באימון המודל:
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error as mse
y_pred = xgb_regressor.predict(X_test) # Predictions
y_true = y_test # True values
MSE = mse(y_true, y_pred)
RMSE = np.sqrt(MSE)
R_squared = r2_score(y_true, y_pred)
print("\nRMSE: ", np.round(RMSE, 2))
print()
print("R-Squared: ", np.round(R_squared, 2))התוצאה:
RMSE: 2316.31 R-Squared: 0.92
נראה טוב. בוא נראה אם אפשר לשפר.
אופטימיזציה של היפר פרמטרים באמצעות Optuna
בחלק זה של המדריך ננסה לשפר את ביצועי המודל באמצעות בחירת הפרמטרים הטובים ביותר בעזרת Optuna.
בפרמטרים:
- max_depth השולט בעומק המרבי של כל אחד מעצי ההחלטה.
- learning_rate בשביל קצב הלמידה
- reg_alpha ו-reg_lambda בשביל הרגולריזציה
ופרמטרים נוספים, עליהם אפשר לקרוא בתיעוד של XGBoost.
הפונקציה objective מחזירה את את המדד שאותו אנו רוצים למקסם עבור הפרמטרים. במקרה שלנו אנחנו רוצים ערך RMSE מינימלי.
נערוך את הנתונים בפורמט DMatrix ש-XGBoost מעדיף:
dtrain = xgb.DMatrix(X_train, label=y_train)
dval = xgb.DMatrix(X_val, label=y_val)
dtest = xgb.DMatrix(X_test, label=y_test)נוסיף את הפונקציה get_rmse שמאמנת את המודל, מעריכה את ביצועיו, ומחזירה את התוצאות ב-RMSE:
def get_rmse(params):
model = xgb.train(params, dtrain, num_boost_round=100, evals=[(dval, 'eval')], early_stopping_rounds=10, verbose_eval=0)
results = model.eval(dval)
rmse = np.float(re.search(r'[\d.]+$', results).group(0))
return rmseנבדוק מה ערך ה-RMSE אותו מחזירה הפונקציה במצב הבסיס, ללא פרמטרים:
# First, try without any parameters
get_rmse(params = {})1798.812744
הפונקציה objective מעבירה ל-get_rmse את הפרמטרים עליהם הוא צריך לאמן את המודל:
def objective(trial):
params = {
# 'n_estimators' : trial.suggest_int('n_estimators', 0, 500),
'max_depth':trial.suggest_int('max_depth', 2, 10),
'reg_alpha':trial.suggest_uniform('reg_alpha', 0, 10),
'reg_lambda':trial.suggest_uniform('reg_lambda', 0, 10),
'min_child_weight':trial.suggest_int('min_child_weight', 0, 10),
'gamma':trial.suggest_uniform('gamma', 0, 10),
'learning_rate':trial.suggest_loguniform('learning_rate', 0.05, 10.0),
'colsample_bytree':trial.suggest_discrete_uniform('colsample_bytree', 0.1, 1, 0.01),
'subsample': trial.suggest_uniform('subsample',0.1, 1.0),
'nthread' : -1
}
return(get_rmse(params))- הפרמטרים ערוכים בתוך מילון params ופונקציות של Optuna מזינות בכל ריצה פרמטרים אחרים מתוך ההתפלגויות האפשרויות עבור כל אחד מהפרמטרים.
Optuna לומד מ-studies. בכל study הוא קורא לפונקציה objective מספר מוגדר של פעמים trials כשהאלגוריתם לומד בתהליך מהו טווח הפרמטרים הטוב ביותר עבור כל תכונה ומתוכם הוא בוחר את המשתנים שהוא מזין לפונקציה:
study1 = optuna.create_study(direction='minimize', sampler=TPESampler())
study1.optimize(objective, n_trials= 1000, show_progress_bar = True)- האלגוריתם צריך לעשות 1,000 ניסיונות trials, מתוכם לבחור את הפרמטרים שגורמים ל-RMSE מינימלי.
הגרף עוקב אחר התקדמות האלגוריתם באיתור הפרמטרים שמחזיר את הניקוד הטוב ביותר:
optuna.visualization.plot_optimization_history(study1)
- על ציר ה-X אפשר לראות את מספר הניסיונות trials ב-study, ועל ציר ה-Y את המדד שאנו רוצים לשפר (RMSE).
- הירידה המשמעותית ביותר ב-RMSE היא בנסיון trial מספר 25, אחרי כן ירידה משמעותית נוספת בין הניסיונות 139 ו-144, וההתקדמות נמשכת עד לנסיון 1,000. אולי אם הייתי מוסיף עוד מספר נסיונות ל-study הייתי יכול לשפר עוד את התוצאות.
מה ערך ה-RMSE הנמוך ביותר אליו הגענו בתהליך האופטימיזציה?
trial = study1.best_trial
print('RMSE: {}'.format(trial.value))RMSE: 1551
- תוצאה טובה יותר מאשר ה-baseline שעמד על 1798 עבור קבוצת הולידציה.
מה הפרמטרים שנותנים את התוצאה הטובה ביותר?
study1.best_params{'max_depth': 10,
'reg_alpha': 1.9125077561907289,
'reg_lambda': 9.381709354188311,
'min_child_weight': 2,
'gamma': 5.511870736514373,
'learning_rate': 0.3077222110009254,
'colsample_bytree': 0.9,
'subsample': 0.7445496617050331}
מה הביצועים של קבוצת המבחן שהשארנו בצד?
נאמן מודל חדש עם הפרמטרים שמצא optuna:
model = xgb.train(study1.best_params,
dtrain,
num_boost_round=100,
evals=[(dval, 'eval')],
early_stopping_rounds=10,
verbose_eval=0)נעריך את ביצועי המודל על סט המבחן שלא השתתף בתהליך האימון:
y_pred = model.predict(dtest) # Predictions
y_true = y_test # True values
MSE = mse(y_true, y_pred)
RMSE = np.sqrt(MSE)
R_squared = r2_score(y_true, y_pred)
print("\nRMSE: ", np.round(RMSE, 2))
print()
print("R-Squared: ", np.round(R_squared, 2))RMSE: 2303.93 R-Squared: 0.93
- ה-RMSE ירד מ-2316 ל-2303 וגם R2 עלה מ-0.92 ל-0.93
התקדמנו יפה אבל אנחנו שואפים להשתפר. לשם כך, נערוך study חדש בו נתמקד בטווח הפרמטרים שעל פי הניסוי הראשון הביאו לערך RMSE הנמוך ביותר.
נאתר את הטווחים של הפרמטרים שגרמו לתוצאות הטובות ביותר של ה-study באמצעות התרשים הבא:
optuna.visualization.plot_slice(study1)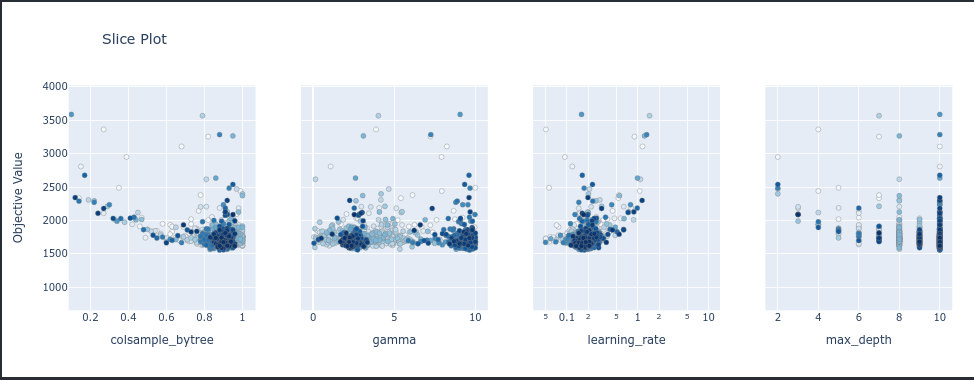
- על ציר ה-Y ערך RMSE ועל ציר X ערכי הפרמטר.
- נבחר את הטווחים עבור הפרמטרים שנותנים את הערך הנמוך ביותר על ציר Y. לדוגמה, הערכים שמביאים למינימום עבור colsample_bytree נמצאים בטווח שבין 0.8 ל- 1.0, ואת זה אפשר לראות כי הערך על ציר ה-Y הוא נמוך וגם יותר trials מרוכזים באזור מה שגורם לו להופיע בצבע כהה יותר.
- אני מציג רק 4 תכונות. את היתר אפשר לראות במחברת.
על סמך הניתוח לעיל הגדרתי מחדש את טווחי הפרמטרים שנעביר לפונקציה שעושה אופטימיזציה:
def objective1(trial):
params = {
#'n_estimators' : trial.suggest_int('n_estimators', 0, 500),
'max_depth':trial.suggest_int('max_depth', 8, 10),
'reg_alpha':trial.suggest_uniform('reg_alpha', 6, 9),
'reg_lambda':trial.suggest_uniform('reg_lambda', 3.0, 6.5),
'min_child_weight':trial.suggest_int('min_child_weight', 0, 1),
'gamma':trial.suggest_uniform('gamma', 1, 4),
'learning_rate':trial.suggest_loguniform('learning_rate', 0.1, 0.3),
'colsample_bytree':trial.suggest_discrete_uniform('colsample_bytree', 0.85, 1, 0.01),
'subsample': trial.suggest_uniform('subsample', 0.8, 1.0),
'nthread' : -1
}
return(get_rmse(params))נערוך ניסוי חדש, study2:
study2 = optuna.create_study(direction='minimize', sampler=TPESampler())
study2.optimize(objective1, n_trials= 1000, show_progress_bar = True)נאמן מודל חדש עם הפרמטרים הטובים ביותר שמצא study2:
model2 = xgb.train(study2.best_params,
dtrain,
num_boost_round=100,
evals=[(dval, 'eval')],
early_stopping_rounds=10,
verbose_eval=0)נעריך את ביצועי המודל החדש, model2 על סט המבחן:
y_pred = model2.predict(dtest) # Predictions
y_true = y_test # True values
MSE = mse(y_true, y_pred)
RMSE = np.sqrt(MSE)
R_squared = r2_score(y_true, y_pred)
print("\nRMSE: ", np.round(RMSE, 2))
print()
print("R-Squared: ", np.round(R_squared, 2))RMSE: 2222.0 R-Squared: 0.93
- אפשר לראות התקדמות מכיוון שירדנו ב-RMSE ל-2222 ועלינו ב-R2 ל-0.93.
- ערך R2 של 0.93 מלמד שהמודל מצליח להסביר 93% מהשונות במחירים ורק 7% ניתן לתלות בגורמים אחרים ואקראיות.
האם ערך ה-RMSE הוא גבוה או נמוך? כדי לענות על השאלה אנחנו צריכים קודם כל להסתכל על המדדים הסטטיסטיים של עמודת המחיר:
y_test.describe().Tcount 2346.000000 mean 6595.794625 std 8425.017230 min 299.990000 25% 2670.000000 50% 4500.000000 75% 6950.000000 max 72000.000000
- המחיר הממוצע של המכוניות הוא 6,595$ עם סטיית תקן 8,425. מה- RMSE אנחנו לומדים שהשגיאה הממוצעת עבור מחיר מכונית אותו חוזה המודל היא 2,222$. ערך סביר בהחלט.
נסביר את המודל
המודל מצליח לחזות את מחירי המכוניות בדיוק רב אבל לא ברור מהם השיקולים עליהם הוא מסתמך בקביעת המחיר. למזלנו, XGBoost הוא מודל שקוף יחסית, והוא מאפשר לנו להציץ במשקל שהוא נתן לתכונות השונות בחיזוי התוצאות.
הפונקציה הבאה מסדרת את העמודות לפי המשקל שנתן להם המודל בקביעת המחיר:
# first, feature importance
def get_feature_importance(model):
features_list = list(model.get_fscore().items())
features_df = pd.DataFrame(features_list, columns=['feature','importance']).sort_values('importance', ascending=False)
return features_dfget_feature_importance(model)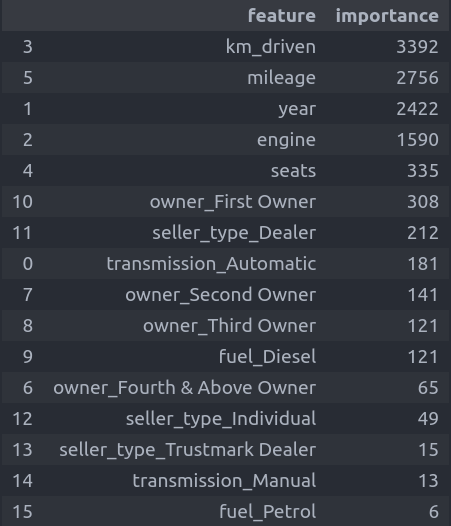
אפשר גם בתרשים:
from xgboost import plot_importance
from matplotlib import pyplot
# plot feature importance
plot_importance(model)
pyplot.show()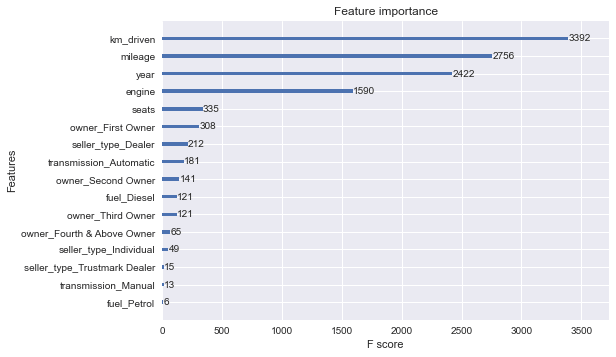
- התכונה המשפיעה ביותר על קביעת המחיר היא מספר הק"מ. ואחריו מספר מיילים לגלון, שנת הייצור, סוג המנוע (בנזין או דיזל), מספר המושבים, תמסורת (אוטומטית או ידנית) ויש גורמים נוספים.
מה שחסר בניתוח הוא באיזה אופן משפיעים הנתונים. אז נחפור יותר לעומק עם SHAP.
import shap
shap.initjs()# explain the model's predictions using SHAP
explainer = shap.Explainer(model)
shap_values = explainer(X_test)מה הגורמים שהשפיעו על המחיר החזוי של אחת המכוניות? לדוגמה, המכונית הראשונה:
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])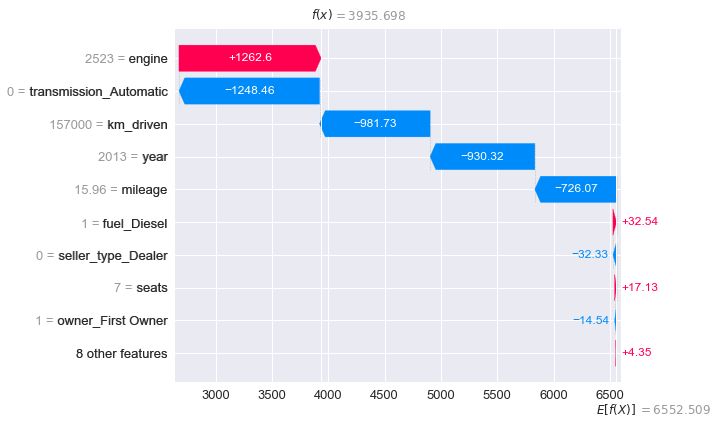
הערך החזוי עבור כל המכוניות הוא E[f(X)]. על הדוגמה פועלים כוחות באדום התורמים לעליית המחיר ובכחול לירידה. הסכום המצטבר של התכונות הגורמות לירידה במחיר עולה על סך התכונות שמייקרות את המחיר ועל כן המחיר אותו חוזה המודל עבור הדוגמה f(x) הוא נמוך יותר (המחיר הצפוי למכונית הוא 3,935$ לעומת 6,552$ מחירה החזוי של מכונית ממוצעת):
- ההשפעה הכי גדולה היא לנפח המנוע הגבוה (2523) שמעלה את המחיר ב- 1,262$.
- אחריו התמסורת הידנית שמפחיתה 1,248$.
- הקילומטרז' במקום השלישי תורם לירידת ערך של 981$.
אפשר לעשות את אותו הדבר על כל אחת מהדוגמאות, ולקבל הסברים מפורטים מאוד.
מעניין מה ההשפעה של כלל התכונות על תחזית המחיר של כל הדוגמאות.
# summarize the effects of all the features
shap.plots.beeswarm(shap_values)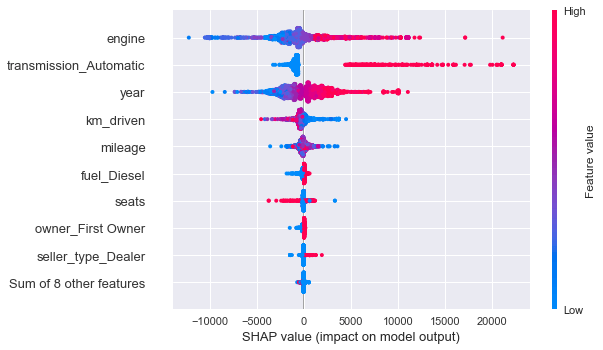
- נפח המנוע הוא הוא בעל ההשפעה הגבוהה ביותר על המחיר. אחריו, סוג התמסורת (ידנית או או אוטומטית), שנת היצור, הקילומטרז', צריכת הדלק, ועוד.
- מנועים בעלי נפח גבוה נוטים להעלות את מחיר הרכב ומנועים קטנים להפחית.
- תמסורת אוטומטית מעלה את המחיר.
- שנת ייצור גבוהה (קרובה לימינו) מעלה את המחיר.
- מספר ק"מ גבוה נוטה להפחית.
נבדוק איך משפיעה התכונה החשובה ביותר אליבא דSHAP, גודל המנוע, על המחיר:
# create a dependence scatter plot to show the effect of a single
# feature across the whole dataset
shap.plots.scatter(shap_values[:,"engine"], color=shap_values)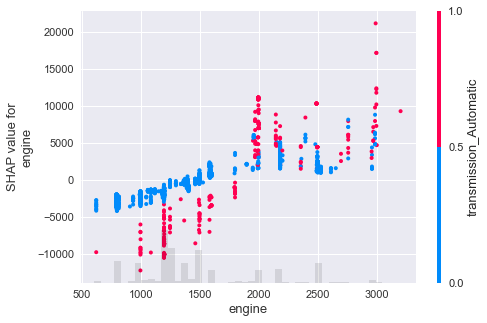
- ככל שנפח המנוע עולה, עולה גם המחיר.
- האינטראקציה העיקרית היא עם התמסורת. תמסורת אוטומטית גורמת לירידת ערך במנועים קטנים ולעלייה במנועים גדולים.
תודה SHAP! מדהים לאיזה עומק של תובנות אפשר להגיע במאמץ לא גדול, והכל ביחידות הנמדדות. במקרה שלנו, קל לתרגם את התכונה (סוג המנוע ושנת הייצור) למחיר בדולרים. מי צריך את לוי יצחק.
את הקוד המלא אותו פתחנו במדריך אפשר למצוא במחברת המצורפת.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.