
התפלגות בטא ותהליך העדכון הבייסיאני
הרבה פעמים אנחנו משתמשים בסטטיסטיקה על מנת לייצר מודל של אי ודאות לגבי הסתברויות: בין אם זה הסיכוי של מטבע לנחות על ראשו או שיעור ההצלחה של קמפיין שיווקי. התפלגות בטא, התחומה לרוב בין הערכים [0,1], היא בחירה טבעית עבור משימות אילו. מדריך זה יציג את התפלגות בטא, את מקרי השימוש בה, יציג עדכון בייסיאני כמסגרת לבחינת הסתברויות, ויסיים בדוגמה מעשית של קוד Python.
מברנולי לבינומי: קיצור תולדות ההתפלגות הבינומית
הסיפור מתחיל בהתפלגות ברנולי, המטפלת בניסוי יחיד עם שתי תוצאות אפשריות. לדוגמה, הטלה של מטבע. או שהמטבע נופל על "עץ" או שנופל על "פלי".
כאשר עושים מספר ניסויים עצמאיים של ברנולי, המספר הכולל של ההצלחות מתואר על ידי התפלגות בינומית. לדוגמה, הטלה של מספר מטבעות.
התפלגויות בסיסיות אילה משמשות לתיאור תהליכים בינארים, ומהוות בסיס להתפלגות בטא.
התפלגות בטא
התפלגות בטא נכנסת לתמונה כאשר מחלקים את מספר ההצלחות (והכישלונות) במספר הכולל של הניסויים דבר המעביר את המיקוד מספירת הצלחות לכימות אי הוודאות לגבי ההסתברות הבסיסית להצלחה אשר ערכה, כמו התפלגות בטא, תחום בין 0 ל-1. לדוגמה, ניסוי בהטלת מטבע כאשר "הצלחה" מוגדרת כקבלת "עץ". לאחר 10 הטלות, מתוכם 7 נפלו על "עץ" שיעור ההצלחה הוא 7/10=0.7 ושיעור הכישלון הוא המשלים ל-1, דהיינו 3/10=0.3.
התפלגות בטא מאופיינת בשני פרמטרים α ו-β שערכם נקבע על פי מספר ההצלחות והכישלונות:
Beta(α+1, β+1)
כאשר המוסכמה היא שיש להוסיף 1 לפרמטרים:
- למספר הצלחות מוסיפים 1 וזה הערך של α.
- למספר הכישלונות מוסיפים 1 וזה ערכה של β.
α ו-β קובעים את צורת ההתפלגות כפי שאפשר לראות בתרשים הבא:
![Beta distribution for [1,1] [2,6] [6.2]](/assets/img/uploads/27_02_2025_04_48_10-1740631690.png)
-
פונקצית הצפיפות (PDF) של הסתברות בטא מחושבת באמצעות הנוסחה:
$$ f(x; \alpha, \beta) = \frac{x^{\alpha-1} (1-x)^{\beta-1}}{\int_0^1 t^{\alpha - 1} (1 - t)^{\beta - 1} dt} $$
כאשר:
- α ו-β קובעים את הצורה.
- x מוגדר בטווח שבין 0 ל-1.
- המכנה הוא פקטור מנרמל.
-
השכיח mode מחושב באמצעות הנוסחה:
$$ \text{Mode} = \frac{\alpha - 1}{\alpha + \beta - 2}, \quad \alpha, \beta > 1 $$
והוא נמצא בערך המקסימום של הפונקציה.
הממוצע מחושב באמצעות הנוסחה:
$$ \text{Mean} = \frac{\alpha}{\alpha + \beta} $$
והוא נוטה לעבר מרכז הכובד של הפונקציה. לדוגמה במקרה של 2,6 הוא יטה מעט ימינה מהשכיח בגלל שההתפלגות נוטה לימין.
סטיית התקן קטנה ככל שמספר הדוגמאות גדול יותר דבר המעיד על ביטחון רב יותר בהערכה.
ככל שמצליחים לאסוף יותר נתונים ההתפלגות מצטמצמת כיוון שסטיית התקן קטנה ככל שהתוצאה מבוססת על מספר רב יותר של דוגמאות:
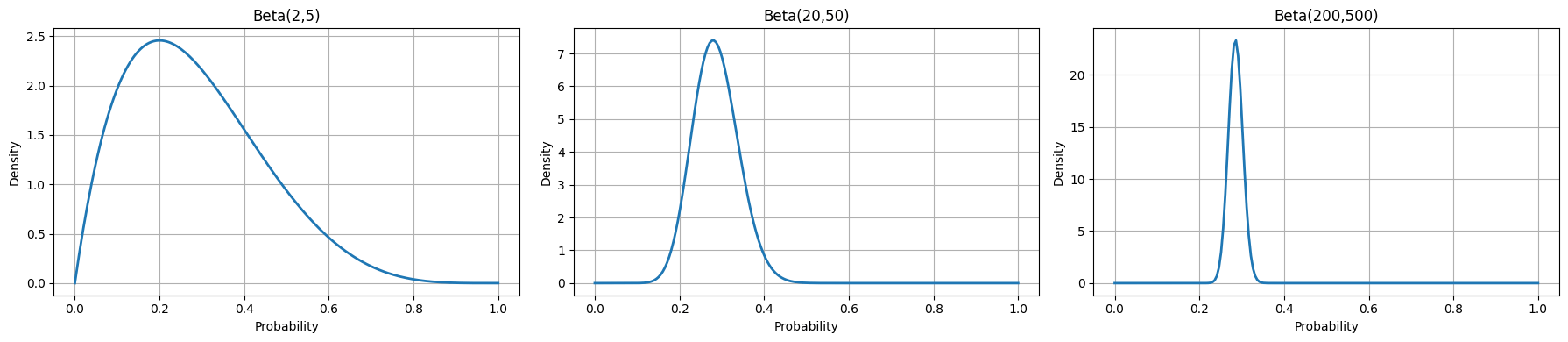
בהתפלגות בטא משתמשים, בין השאר:
- להערכת הסתברויות ופרופורציות: לדוגמה, הערכת שיעור ההצלחה של ניסויים קליניים או הפרופורציה של הקלקות על מודעה באינטרנט.
- להערכת משך זמן ביצוע: בניהול פרויקטים משתמשים בהסתברות כדי להעריך את משך הזמן הדרוש להשלמת משימות.
הסתברות בטא שימושית במסגרת של סטטיסטיקה בייסיאנית בגלל תכונות אותם נסביר בחלקו הבא של המדריך.
סטטיסטיקה בייסיאנית: מסגרת לעדכון אמונות בהינתן מידע חדש
מה שתהליך ההסקה הבייסיאני (Bayesian) עושה הוא לעדכן את האמונות הקודמות שלנו בהינתן ראיות חדשות. את התהליך נתחיל מהתפלגות מוקדמת, פריורית (prior), המייצגת את אי הוודאות הראשונית שלנו לגבי ההסתברות. בעקבות איסוף נתונים במסגרת ניסוי או מחקר מעדכנים את את המודל, אשר מפיק התפלגות מעודכנת, פוסטיריורית (posterior), המתחשבת בנתונים הראשוניים כמו גם בנתונים הנוספים.
העניין הוא שלא תמיד קל להפיק תוצאות שקל לעבוד איתם. יתרונה הגדול של התפלגות בטא כהתפלגות מוקדמת (פריורית) טמון בכך שההתפלגות הפוסטיריורית אשר מפיק המודל גם היא בטא מה שמקל על הפיתוח המתמטי ופירוש התוצאות. בזכות התכונה המאפשרת לקבל מתהליך העדכון הבייסיאני תוצאה השייכת לאותה משפחת התפלגויות ממנה מתחילים בטא קרויה התפלגות צמודה conjugate של סטטיסטיקה בייסיאנית.
למה התפלגות בטא מכונה "הסתברות של הסתברויות"?
כאשר אנו עוסקים בבעיות שבהן קיימת אי-וודאות לגבי ערך ההסתברות - למשל, ההסתברות שמטבע שאנחנו חושדים שהוא מוטה ינחת על "עץ" - אנחנו לא יודעים לנקוב בערך הסתברות אחד ספציפי. לגבי מטבע כזה אי אפשר להגיד "ההסתברות היא 0.5" כי אנחנו לא באמת יודעים אבל מה שאנחנו כן יכולים לעשות הוא לתאר את הסיכויים באמצעות התפלגות. במקרה של משתנה בינארי, התפלגות בטא,שהודות לה נוכל לאמר משהו דומה ל "יש לנו הסתברות מסוימת (למשל, 95%) שהערך המבוקש נמצא בטווח שבין 0.3 ל-0.7".
בפועל, במקום להצביע על ערך יחיד של הסתברות, לדוגמה 50%, מגדירים פונקצית הסתברות בה α ו-β מייצגים את הידוע לנו לגבי מספר ההצלחות והכשלונות. בכך, אנחנו למעשה יוצרים התפלגות על ערך ההסתברות. כלומר, אנחנו מתארים את ההסתברות באמצעות טווח x של הסתברויות. זהו הרעיון מאחורי הכינוי "הסתברות של הסתברויות".
כאשר אנו אוספים נתונים ומעדכנים את ההתפלגות בעזרת עדכון בייסיאני, אנחנו מצמצמים את חוסר הוודאות: עם נתונים מועטים, נקבל התפלגות רחבה. ככל שמצטברים נתונים, ההתפלגות מתרכזת, ומצביעה על ערך הסתברות מדויק יותר. כך, באמצעות התפלגות בטא, אנו לא רק מגדירים ערך נקודתי אלא גם מביעים את מידת אי הוודאות שלנו לגבי ערך ההסתברות.
דוגמה לתהליך עדכון בייסיאני
נניח שאתה בעל חנות רהיטים המעוניין לדעת האם אתר האינטרנט המושקע שלך יצליח למכור.
האפשרויות הם שמשתמש הנכנס לאתר שלך ירכוש ("הצלחה") או שלא ירכוש ("כישלון"). בגלל שלניסוי שאתה עורך יתכנו אחת משתי תוצאות זהו ניסוי בינומי, ולכן כדאי לך, כפי שכבר למדת, להשתמש בהתפלגות בטא לצורך עדכון מודל בייסיאני ממנו תלמד על סיכויי ההצלחה של האתר.
אתה לא באמת יודע כמה האתר שלך יצליח במשימה ולכן אתה משתמש בהתפלגות מקדימה (פריורית) "שטוחה" במסגרתה אתה מניח שמתוך 10 כניסות רק 5 ירכשו. זהו יחס של 5:5 בין הצלחה לכישלון מה שאומר:
Beta(α,β) = Beta(5+1, 5+1)
- תוספת של 1 לכמות הינה מוסכמה של שימוש בבטא עבור עדכון בייסיאני המתחיל מפריור שטוח (1:1).
עדכון המודל בפעם הראשונה: בשעה הראשונה אתה מגלה שנכנסו לדף 10 משתמשים מתוכם 4 רכשו בפועל. מה שאומר שיחס הצלחה לכישלון של 6:4. את הנתונים אתה מעדכן על ידי הוספה לפרמטרים הידועים מהצעד הקודם (5:5). לפיכך, ההתפלגות הפוסטיריורית תהיה:
Beta(α,β) = Beta(5+1+4, 5+1+6) = Beta(10, 12)
עדכון המודל פעם שנייה: בשעה השנייה אתה רואה שנכנסו לאתר 20 משתמשים ומתוכם 7 רכשו. יחס של 7:13. מה שאומר שבסך הכול, ולאחר הוספה לנתוני השלב הקודם, ההתפלגות הפוסטיריורית הינה:
Beta(α,β) = Beta(10+7, 12+13) = Beta(17, 25)
קוד פייתון ליישום תהליך העדכון הבייסיאני
קוד הפייתון להלן מחשב את המודל הבייסיאני אשר יסייע לסוחר להעריך כמה אתר האינטרנט שלו עשוי להצליח במכירת הרהיטים:
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import beta
class BayesianUpdater:
"""
A class to perform Bayesian updates on a Beta-Binomial model and visualize the process.
The Beta distribution is the prior for the probability of success.
"""
def __init__(self, alpha=1, beta_param=1):
self.alpha = alpha
self.beta = beta_param
# Store the history of (alpha, beta) pairs, starting with the prior
ci = self.credible_interval(self.alpha, self.beta)
self.history = [(self.alpha, self.beta, ci)]
def update(self, successes, failures):
"""Updates the distribution with new data and records the new state."""
self.alpha += successes
self.beta += failures
ci = self.credible_interval(self.alpha, self.beta)
self.history.append((self.alpha, self.beta, ci))
def mean(self):
"""Calculates the current posterior mean."""
return self.alpha / (self.alpha + self.beta)
def mode(self):
"""Calculates the current posterior mode."""
if self.alpha > 1 and self.beta > 1:
return (self.alpha - 1) / (self.alpha + self.beta - 2)
return "Not defined"
def std(self):
"""Calculates the current posterior standard deviation."""
num = self.alpha * self.beta
denom = (self.alpha + self.beta)**2 * (self.alpha + self.beta + 1)
return np.sqrt(num / denom)
def credible_interval(self, a, b, conf=0.95):
"""
Calculates the credible interval for a given alpha and beta.
"""
lower = beta.ppf((1 - conf) / 2, a, b)
upper = beta.ppf(1 - (1 - conf) / 2, a, b)
return lower, upper
def plot_updates(self, labels=None, conf=0.95):
"""
Plots the prior and all posterior distributions on a single graph,
highlighting the credible interval.
"""
x = np.linspace(0, 1, 400)
cmap = plt.get_cmap('viridis')
colors = cmap(np.linspace(0.2, 0.8, len(self.history)))
for i, (a, b, (lower, upper)) in enumerate(self.history):
dist_pdf = beta.pdf(x, a, b)
# Determine the label for the legend
if labels and len(labels) == len(self.history):
label_prefix = labels[i]
else:
label_prefix = "Prior" if i == 0 else f"Update {i}"
label = f'{label_prefix}: {conf*100:.0f}% CI [{lower:.3f}, {upper:.3f}]'
# Plot the main distribution curve
plt.plot(x, dist_pdf, lw=2.5, color=colors[i], label=label)
# Shade the credible interval area
plt.fill_between(x, dist_pdf, where=(x >= lower) & (x <= upper),
color=colors[i], alpha=0.25)
plt.xlabel('Probability Parameter (e.g., Conversion Rate)')
plt.ylabel('Density')
plt.title('Evolution of Beliefs with Bayesian Updating')
plt.legend(title=f"Distribution & {conf*100:.0f}% Credible Interval")
plt.grid(True, linestyle=':', alpha=0.6)
plt.show()נריץ:
# 0. Define the Prior
# Start with a weakly informative prior, Beta(5, 5), suggesting a fair process.
alpha0, beta0 = 5+1, 5+1
updater = BayesianUpdater(alpha=alpha0, beta_param=beta0)
print(f"Prior: Beta({updater.alpha}, {updater.beta})")
print(f" Mean = {updater.mean():.3f}")
print(f" Mode = {updater.mode():.3f}")
print(f" Std. Deviation = {updater.std():.3f}")
lower, upper = updater.credible_interval(updater.alpha, updater.beta)
print(f" 95% Credible Interval = [{lower:.3f}, {upper:.3f}]\n")
# 1. First Update
updater.update(4, 6)
print(f"1st Stage: Beta({updater.alpha}, {updater.beta})")
print(f" Mean = {updater.mean():.3f}")
print(f" Mode = {updater.mode():.3f}")
print(f" Std. Deviation = {updater.std():.3f}")
lower, upper = updater.credible_interval(updater.alpha, updater.beta)
print(f" 95% Credible Interval = [{lower:.3f}, {upper:.3f}]\n")
# 2. Second Update
updater.update(7, 13)
print(f"2nd Stage: Beta({updater.alpha}, {updater.beta})")
print(f" Mean = {updater.mean():.3f}")
print(f" Mode = {updater.mode():.3f}")
print(f" Std. Deviation = {updater.std():.3f}")
lower, upper = updater.credible_interval(updater.alpha, updater.beta)
print(f" 95% Credible Interval = [{lower:.3f}, {upper:.3f}]\n")
# Generate the plot with custom labels
stage_labels = ["Prior Belief", "Day 1", "Day 2"]
updater.plot_updates(labels=stage_labels)התוצאות מסוכמות להלן:
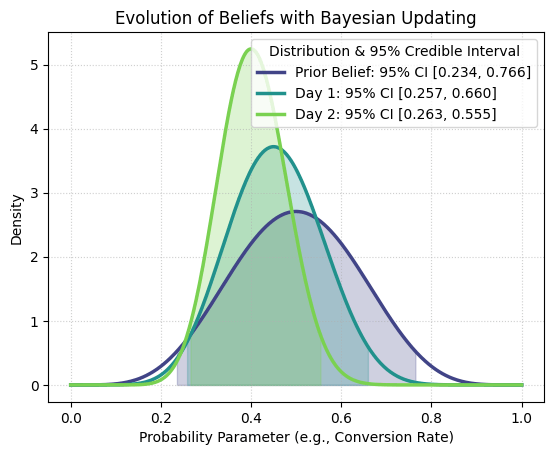
Prior: Beta(6, 6) Mean = 0.500 Mode = 0.500 Std. Deviation = 0.139 95% Credible Interval = [0.234, 0.766] 1st Stage: Beta(10, 12) Mean = 0.455 Mode = 0.450 Std. Deviation = 0.104 95% Credible Interval = [0.257, 0.660] 2nd Stage: Beta(17, 25) Mean = 0.405 Mode = 0.400 Std. Deviation = 0.075 95% Credible Interval = [0.263, 0.555]
ננתח את הממצאים
ככל שנאסוף יותר נתונים, ההתפלגות הפוסטריורית תתרכז יותר סביב הערך האמיתי. כלומר, הרווח בר-המהימנות (Credible Intervals) קטן וסטיית התקן יורדת, מה שאומר שאנו יכולים להיות בטוחים יותר בתוצאות הודות לצמצום חוסר הוודאות.
התכנסות וצמצום חוסר הוודאות
- בשלב הראשוני (Beta(6,6)):
בתחילת הדרך, כאשר השתמשנו בהתפלגות פריורית זו, אמונתנו לגבי שיעור ההצלחה הייתה מפוזרת באופן רחב – סטיית התקן הייתה 0.139 והרווח בר-המהימנות היה בין 0.234 ל-0.766. משמעות הדבר היא שלא היינו מאוד בטוחים והתאפשר טווח רחב של ערכים. - עדכון ראשון (Beta(10,12)):
לאחר שנאסף מידע אמיתי – 10 מבקרים עם 4 רכישות (4 הצלחות ו-6 כישלונות) – המרווח הצטמצם ל-[0.257, 0.660] וסטיית התקן ירדה ל-0.104. הנתונים החדשים עדכנו את האמונות הראשוניות שלנו. - עדכון שני (Beta(17,25)):
בשלב זה, תוספת נתונים של עוד 20 מבקרים עם 7 רכישות (סך הכל מצטבר של 17 הצלחות ו-25 כישלונות) הורידה את חוסר הוודאות עוד יותר: הרווח בר-המהימנות הצטמצם ל-[0.263, 0.555] וסטיית התקן ירדה ל-0.075. כעת יש לנו הערכה מדויקת יותר של שיעור ההצלחה האמיתי.
שינוי בהערכות נקודתיות (ממוצע ושכיח)
- בהתחלה:
האמונה המוקדמת שלנו הייתה ממורכזת ב-0.5, כאשר הממוצע וגם השכיח (Mode) היו 0.5. - לאחר איסוף הנתונים: הממוצע והשכיח פחתו הממוצע ירד מ-0.455 (בעדכון הראשון) ל-0.405 (בעדכון השני), והשכיח ירד מ-0.450 ל-0.400. זה מצביע על כך שהאמונה הראשונית הייתה מעט אופטימית ביחס לנתונים בפועל, וששיעור ההצלחה האמיתי נמוך מהצפוי.
פירוש הרווח בר-מהימנות (Credible Intervals)
- לפי העדכון השני, ישנה הסתברות של 95% שההסתברות האמיתית לכך שמבקר יבצע רכישה נמצאת בין 0.263 ל-0.555.
- ההסתברות ששיעור ההמרה האמיתי נמצא מחוץ לטווח זה (על סמך הידע הנוכחי שלנו) היא 5% בלבד.
השלכות עסקיות
- אם נשתמש בנתונים אלו לחיזוי ביצועים עתידיים, ייתכן ונבחר להשתמש בממוצע (0.405) כהערכה נקודתית.
- כאשר מדובר בקבלת החלטות הדורשות זהירות (למשל, קביעת תקציבים לפרסום או הגדרת ציפיות הכנסה), מומלץ להתמקד בגבול התחתון (0.263) כהערכה שמרנית.
- הגבול העליון (0.555) מציג תרחיש מיטבי, אך הסתמכות עליו בלבד עלולה להוביל להערכת יתר ולנטילת סיכונים מוגברת.
עדכונים עתידיים
- ככל שנמשיך לאסוף נתונים, צפוי שסטיית התקן והרווח בר-המהימנות יצטמצמו עוד יותר, מה שיביא להערכות מדויקות בהרבה.
- שינוי בתנאי השוק (למשל, קמפיין שיווקי חדש) עשוי להשפיע על התנהגות הצרכנים ולשנות את צורת ההתפלגות הפוסטריורית.
מסקנות הניתוח
הלקח המרכזי הוא שככל שאנו אוספים יותר נתונים, חוסר הוודאות קטן וההערכות שלנו נעשות מדויקות יותר. מעבר לכך, חשוב לזכור שהדיווח הבייסיאני צריך לכלול לא רק הערכות נקודתיות (כמו ממוצע או שכיח), אלא גם טווחים של חוסר ודאות (דוגמת רווח בר-מהימנות ברמה של 95%) מה שמעניק תמונה מלאה של ה"סיכון" והביטחון בהערכות.
באופן זה, ניתן לקבל החלטות מושכלות תוך שקלול של כל ההסתברויות מהתרחיש השמרני ועד לתרחיש האופטימי.
נסכם
ההתפתחות מהתפלגויות ברנולי ובינומיות להתפלגות בטא טומנת בחובה שינוי מהותי: מספירת הצלחות להבעת מידת אי הוודאות לגבי הסתברויות. המאפיינים של התפלגות בטא הופכים אותה לשימושית במיוחד בתחומים הנעים מבקרת איכות ועד לניסויים קליניים. באמצעות תהליך העדכון הבייסיאני, אתה יכול לדייק את ההערכות שלך ללא הרף, דבר המגביר את מידת הביטחון בתוצאה ככל שאתה מצליח לספק יותר נתונים. נסה את קוד ה- Python במדריך, וראה בעצמך כיצד התפלגות Beta מתפתחת בעקבות כל מידע חדש המוצב לתוכה.
מדריכים נוספים העשויים לעניין אותך
מדריך מעשי על התפלגות פואסנית באמצעות קוד פייתון וציפורים נודדות
מבחני חי בריבוע לבדיקת השערות עם פייתון
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.