
cross-validation להערכת ביצועי מודל
עד עכשיו בסדרת למידת המכונה נהגתי לחלק את הנתונים בין קבוצת לימוד ומבחן (test ו-train). הגישה שבוחנת את המודל על נתונים שהוא לא ראה מלמדת עד כמה המודל למד להכליל מדוגמאות האימון לדוגמאות חדשות אבל הבעיה ששיטת החלוקה מטה את התוצאות, וכמו שנראה במדריך קיימת טכניקה טובה יותר.

ייבוא הספריות והמודלים
נייבא את הספריות הבסיסיות ואת המודלים שישמשו במדריך:
import numpy as np- numpy כדי לעבוד עם מערכים של מספרים.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from xgboost.sklearn import XGBClassifierשלושת המודלים מוכרים ונעשה בהם שימוש נרחב לסיווג:
- KNN (k-nearest neighbor)
- Random forest
- XGB
from sklearn.metrics import f1_score- בגלל שסט הנתונים לא מאוזן נשתמש ב-f1 להעריך את הביצועים שלו.
מסד הנתונים
מסד הנתונים wine quality dataset מכיל מדידות עם הרכבם הכימי של יינות. נייבא אותו:
from sklearn.datasets import load_wine
df = load_wine()המטרה של סט הנתונים היא לסווג דוגמאות של יינות לאחת משלוש דרגות טיב: 0, 1 או 2 על בסיס המידע הכימי על הרכב הדוגמאות.
האם מסד הנתונים מאוזן?
import collections
collections.Counter(df.target)Counter({0: 59, 1: 71, 2: 48})
- סט הנתונים לא מאוזן.
אחרי שהבאנו את הנתונים השאלה הראשונה היא באיזה מודל להשתמש כדי לקבל את התוצאות הטובות ביותר.
הבנת הבעיה
כדי לבחור את המודל הטוב ביותר אנחנו צריכים להעריך את ביצועי המודלים השונים, וכדי לעשות את זה אנחנו קודם כל צריכים לפצל את סט הנתונים בין דוגמאות אימון ומבחן באמצעות train_test_split:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.data, df.target, test_size=0.3,random_state=42, stratify=df.target)- חשוב להעביר את הפרמטר stratify כדי לשמור על היחס בין קבוצות המטרה כי סט הנתונים לא מאוזן.
- הפרמטר random_state הוא זרע האקראיות לפיו המודל בוחר את הדוגמאות, ומיד נראה ששינוי שלו משפיע על התוצאות, וזו הבעיה.
נאמן את המודל KNN על נתוני קבוצת האימון ונעריך את ביצועיו על קבוצת המבחן:
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
knn.score(X_test, y_test)0.722
מדד הדיוק accuracy הוא 0.72, אבל כיוון שסט הנתונים לא מאוזן מדד f1 נחשב אמין יותר:
y_pred = knn.predict(X_test)
f1_score(y_test, y_pred, average='weighted')0.727
מכיוון שאנחנו חוזרים על התהליך עם יתר המודלים מוטב להשתמש בפונקציה:
def get_score(model, X_train, X_test, y_train, y_test):
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
return f1_score(y_test, y_pred, average='weighted')- הפונקציה get_score מקבלת את המודל, ואת נתוני קבוצת האימון והמבחן, מאמנת אותו, ומחזירה את המדד f1.
נפעיל את הפונקציה על המודל של KNN שכבר יצרנו:
get_score(knn, X_train, X_test, y_train, y_test)0.727
נמצא את מדד f1 עבור מודל מסוג XGB. גם כן באמצעות הפונקציה:
xgb = XGBClassifier(objective='binary:logistic', use_label_encoder=False)
get_score(xgb, X_train, X_test, y_train, y_test)1.0
כנ"ל מודל random forest:
rf = RandomForestClassifier(n_estimators=10)
get_score(rf, X_train, X_test, y_train, y_test)0.98
לפחות בסיבוב הראשון, יש לנו מנצח. XGB נותן את המדד f1 הגבוה ביותר והמושלם של 1, אחריו בהפרש קטן random forest עם ערך 0.98. נשרך מאחור KNN שמסתפק ב-0.72
הבעיה היא שכל פעם שחזרתי על הניסוי עם פרמטרים שונים של random_state אותם העברתי לפונקציה train_test_split קיבלתי תוצאות שונות של f1:
- לדוגמה, עבור random_state=7 ערכי f1 של Random forest ו-XGB נתנו תוצאות טובות באותה מידה, 0.96
- לעומת זאת, עבור random_state=1234 ערך f1 של XGB היה 0.96 ונמוך יותר מ-random forest 0.98
סיכמתי את הנתונים בטבלה:
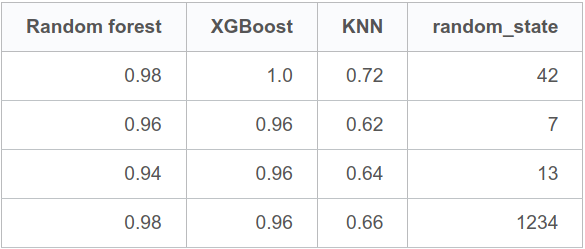
חלוקות שונות בין מסד נתוני אימון ומבחן נותנות תוצאות שונות בגלל האופי הסטוכסטי של המודלים אז קשה להסתמך על תוצאה אחת. מזה אנו למדים שהחלוקה לשתי קבוצות בלבד, ניסוי ומבחן, נותנת תוצאות שקשה לשחזר כי הם מושפעות מגורמים אקראיים.
שיטה טוב יותר cross validation
הטכניקה של cross validation מחלקת את סט הנתונים בין קבוצת אימון ומבחן יותר מאשר פעם אחת. זה יכול להיות שלוש או ארבע, ובדרך כלל יותר.
נדגים על מערך שמכיל 6 פריטים שנעשה לו cross validation שלוש פעמים:
from sklearn.model_selection import KFold
kf = KFold(n_splits=3)KFold(n_splits=3, random_state=None, shuffle=False)
for train_index, test_index in kf.split([1,2,3,4,5,6]):
print(train_index, test_index)[2 3 4 5] [0 1] [0 1 4 5] [2 3] [0 1 2 3] [4 5]
מכיוון שהגדרנו 3=n_splits לולאת ה-cross validation מייצרת 3 פיצולים שונים בין קבוצת אימון ומבחן:
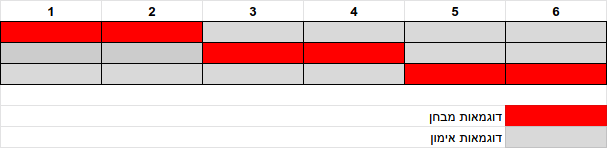
- המערכים משמאל הם קבוצת האימון המכילה 4 דוגמאות, ומימין קבוצת המבחן.
- בפעם הראשונה שהלולאה רצה שתי הדוגמאות הראשונות מופרשות לקבוצת הניסוי.
- בפעם השנייה שתי הדוגמאות האמצעיות.
- בפעם האחרונה שתי הדוגמאות האחרונות.
אפשר לתאר זאת כך:
את המודל נריץ על כל אחד מהפיצולים (בדוגמה שלנו, 3 פעמים). מכל אחת מהריצות נקבל תוצאה. בסוף, נסכם את התוצאות של כל הריצות, ומהסיכום נסיק מסקנות שישקפו באופן אמין יותר את ביצועי המודל.
לפני שניגשים לביצוע יש בעיה אחת נוספת והיא שהפונקציה KFold לא יודעת להתחשב במסדי נתונים לא מאוזנים כמו שלנו, אז במקום להשתמש בה נשתמש בפונקציה StratifiedKFold שלוקחת בחשבון את היחסים בין הקבוצות:
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=10)- מקובל לחלק ל-10 קבוצות כי זה מה שנותן תוצאות טובות יותר.
את הערכות ביצועי המודלים מכל אחת מ-10 הריצות נאסוף למערכים. כל אחד משלושת המערכים אוסף את התוצאות של אחד משלושת המודלים:
scores_knn = []
scores_xgb = []
scores_rf = []
for train_index, test_index in kf.split(df.data, df.target):
X_train, X_test, y_train, y_test = df.data[train_index],
df.data[test_index], df.target[train_index],
df.target[test_index]
scores_knn.append(get_score(knn, X_train, X_test, y_train, y_test))
scores_xgb.append(get_score(xgb, X_train, X_test, y_train, y_test))
scores_rf.append(get_score(rf, X_train, X_test, y_train, y_test))מה ערכי f1 של מודל xgb?
scores_xgb[0.9448329448329448, 1.0, 0.9444444444444444, 0.9448329448329448, 0.8902216610549945, 1.0, 1.0, 0.9444444444444444, 1.0, 1.0]
מה הממוצע וסטיית התקן של ערכי f1?
scores_xgb = np.array(scores_xgb)
print(scores_xgb.mean(), scores_xgb.std())0.95 0.05
נמצא את הממוצע וסטיית התקן של 2 המודלים הנותרים:
scores_knn = np.array(scores_knn)
print(scores_knn.mean(), scores_knn.std())0.69 0.03
scores_rf = np.array(scores_rf)
print(scores_rf.mean(), scores_rf.std())0.96 0.02
- מהפך בצמרת. המודל random forest גבר במעט על XGBoost בזכות ממוצע f1 שעמד על 0.96 לעומת 0.95 המעיד על יתרון במידת הדיוק, ובזכות סטיית תקן קטנה יותר בשיעור 0.02 לעומת 0.05 המעידה על יתרון בחזרתיות.
המסקנה היא שאם משווים בין ביצועי מודלים אז הגישה של cross validation עדיפה על פני פיצול לשתי קבוצות.
יותר מזה, cross validation עדיפה להערכת ביצועי המודל, ויש להשתמש בה ככל האפשר.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.