
מודל למידת מכונה - XGBoost - לראות את העצים בתוך היער
פורסם לראשונה:
בתאריך:
הוספתי את הפרק על feature importance.
XGBoost הוא מודל למידת מכונה מבוסס עצי החלטה שמוכיח עליונות על למידת מכונה עמוקה ברוב המקרים וכל עוד מסד הנתונים אינו גדול ומסובך מדי. לדוגמה, המודל זיכה את המשתמשים בו בהצלחה בתחרויות Kaggle על מסדי נתונים מבוססי טבלה.
העליונות של XGBoost מתבטאת לא רק בדיוק המודלים אלא גם בהפחתה משמעותית בצריכת משאבי מחשב והאפשרות של אדם לקרוא את עצי ההחלטה שהמודל מפתח ולהבין מה הסיבה לתוצאה בעוד בלמידה עמוקה קשה מאוד להבין מדוע המודל מגיע למסקנה מסוימת.
ניתן להשתמש ב-XGBoost לרגרסיה או לסיווג (קלסיפיקציה). במדריך זה נדגים את יכולות הסיווג של המודל שיצטרך לחזות מי שרד את טביעת הטיטניק.
במדריך נלמד להכין מסד נתונים טבלאי ללמידת מכונה באמצעות-XGBoost, כיצד להשתמש במודל, וכיצד לשפר את היכולות שלו באמצעות hyper parameter tuning כוונון פרמטרים.
המדריך מתייחס לכל הנקודות העקרוניות אבל אין דבר טוב יותר מאשר קריאת המחברת שעליה מתבסס המדריך אז אתם מוזמנים להוריד את הקובץ מכאן: titanic_xgboost_300121.zip.
התקנת XGBoost
התקנת XGBoost היא מאוד פשוטה אבל עשויה להשתנות בין מחשבים ומערכות הפעלה. אני מצאתי את הוראות ההתקנה על ידי חיפוש בגוגל של pip + XGBoost.
יבוא הספריות הבסיסיות
הספריות הבסיסיות במדריך, כמו ביתר המדריכים מסדרת למידת מכונה, הם:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')- numpy ,pandas - בשביל החישובים
- matplotlib ,seaborn - בשביל התרשימים
מסד הנתונים
את מסד הנתונים מצאתי בגיטהאב, העתקתי אותו לפרויקט וייבאתי ל-data frame:
# data source: https://gist.github.com/michhar/2dfd2de0d4f8727f873422c5d959fff5
df = pd.read_csv('titanic.csv')במדריך קודם השתמשתי ב-TensorFlow ובלמידת מכונה עמוקה כדי לחזות מי ישרוד את טביעת הטיטאניק.
נסקור את מסד הנתונים:
# How many rows and columns
df.shapeוהתוצאה:
(891, 12)
- במסד הנתונים 891 רשומות המתחלקות בין 12 עמודות.
- כל רשומה מכילה את פרטיו של אחד הנוסעים. כולל האם שרד את טביעת האונייה.
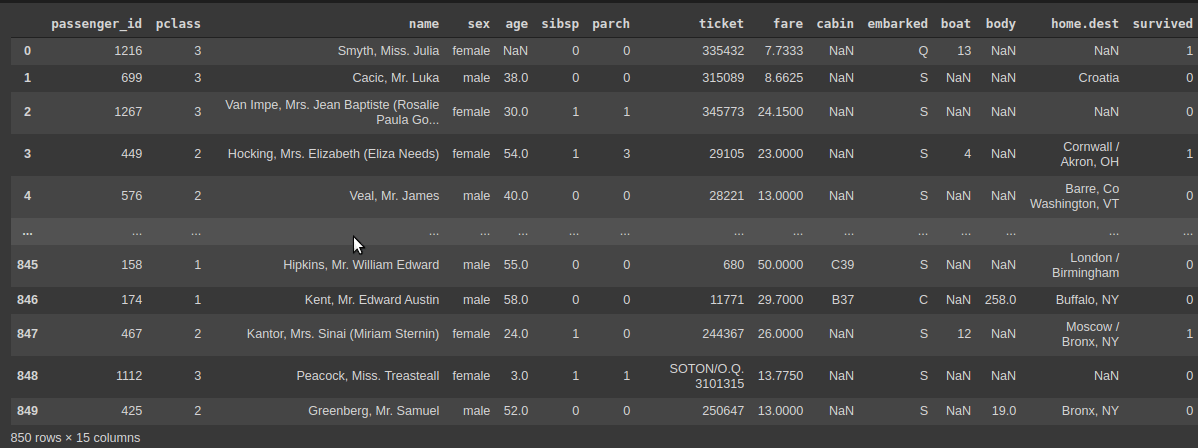
מה בכל עמודה?
# describe the columns
df.info()RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB
- בעמודות: Age, Cabin, Embarked חסר מידע.
- עמודות שאינם מספריות נצטרך לקודד כי XGBoost יודע לעבוד עם מספרים ובוליאנים בלבד.
מעניין לבחון את מידת האיזון של מסד הנתונים:
# the ratio of surviving passengers
df.Survived.value_counts()0 549 1 342 Name: Survived, dtype: int64
- במסד הנתונים יש יותר שורדים מכאלה שלא שרדו. בהמשך המדריך אתייחס לכך בהרחבה.
כמה אנשים מכל מין?
# how many of each gender
df.Sex.value_counts()male 577 female 314 Name: Sex, dtype: int64
- כמעט פי-2 יותר זכרים מנקבות.
נבחן את התפלגות הגילאים:
# what about the distribution of ages
sns.displot(df.Age, binwidth=10)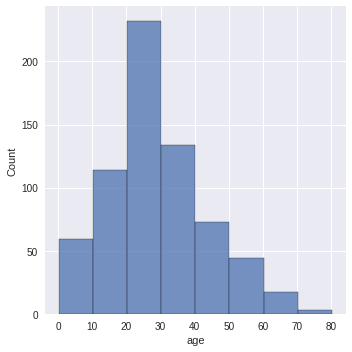
- התפלגות נורמלית ששיאה בגילאים 20-30 שנים.
האם קיים מתאם (קורלציה) בין הנתונים ההמשכיים, גיל ומחיר הכרטיס, והישרדות?
# survival rate vs continuous data
df[['Fare','Age','Survived']].corr()
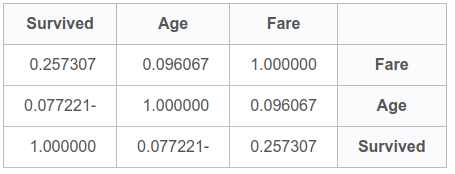
- ישנו מתאם חיובי חלש 0.26 בין מחיר כרטיס והישרדות. אבל נראה שהגיל אינו משפיע אולי בגלל שחסרים נתונים בעמודה.
ננסה למצוא קשר בין נתונים קטגוריים ושיעור ההישרדות:
# survival rate vs categorical data
cols = ['Sex', 'Embarked', 'Pclass', 'Parch']
n_rows = 2
n_cols = 2
fig, axs = plt.subplots(n_rows, n_cols, squeeze=False)
for r in range(0,n_rows):
for c in range(0,n_cols):
i = r*n_cols+ c
ax = axs[r][c]
sns.countplot(df[cols[i]], hue=df['Survived'], ax=ax)
ax.set_title(cols[i])
ax.legend(title='survived')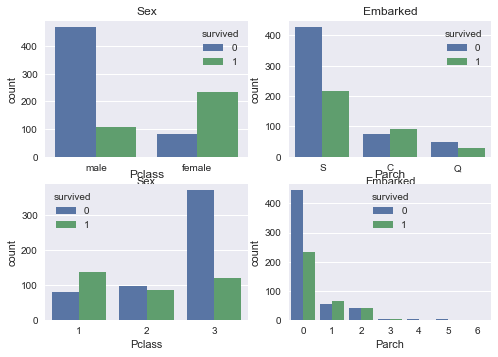
- בעוד רוב הנשים שרדו, רוב הגברים טבעו.
- שיעור הנספים בין הנוסעים שעלו לספינה בנמל שרבורג (Cherbourg) גבוה יותר מאשר בשני הנמלים האחרים.
- בעוד רוב נוסעי המחלקה הראשונה שרדו, רוב נוסעי המחלקה השלישית טבעו.
הכנת הנתונים ללמידת מכונה באמצעות XGBoost
הפונקציה preprocess תשמש להכנת סט הנתונים ללמידת מכונה בעזרת XGBoost:
# clean the dataset
def preprocess(df):
# remove columns with lots of missing values
df = df.drop(['Cabin'], axis=1)
# remove non relevant columns
df_clean = df.drop(['Name','Ticket','PassengerId'], axis=1)
# XGBoost requires no missing cells
# since it is age and we already saw that it has a normal distribution
# we can replace the missing values with the median
# med = df_clean.Age.median()
# the XGBoost way is replacing the missing values with 0
df_clean.Age = df_clean.Age.fillna(0)
# drop rows with missing values
df_clean = df_clean.dropna(axis=0)
# we have to one hot encode categorical columns before using XGBoost
categorical_columns = ['Sex', 'Embarked', 'Pclass', 'Parch']
for cname in categorical_columns:
dummies = pd.get_dummies(df_clean[cname], prefix=cname)
df_clean = pd.concat([df_clean, dummies], axis=1)
df_clean.drop([cname], axis=1, inplace=True)
return df_cleandf_clean = preprocess(df)הפונקציה עושה את הדברים הבאים:
- מסירה את את העמודה Cabin שבה חסרים רוב הנתונים.
- מסירה עמודות לא רלוונטיות כדוגמת שם הנוסע ומספר סידורי.
- מסירה רשומות המכילות נתונים חסרים.
- מחליפה את ערכי הגיל החסרים באפס.
- מקודדת נתונים קטגוריים, דוגמת מין, נמל ומחלקה בשיטת One hot.
XGBoost לא יכול לעבוד עם נתונים חסרים. את נתוני הגיל החסרים הייתי יכול להחליף בערך חציון הגילאים בהתאמה לעובדה שההתפלגות היא נורמלית. גישה אחרת היא להחליף ב-0, ובה אני נוקט כי היוצרים של XGBoost ממליצים לנהוג כך במקרה של נתונים חסרים.
XGBoost לא יודע לעבוד עם נתונים שאינם מספרים או בוליאנים. לכן את הנתונים הקטגורים דוגמת: מין, נמל ומחלקה קודדתי בשיטת one hot encode. אומנם יכולתי להקצות לכל קטגוריה מספר אבל זה לא היה כדאי כיוון שזה היה רומז למודל על יחסים כמותיים ואז הוא היה נוטה לקבץ את הקטגוריות בעלות ערכים מספריים דומים ביחד. לדוגמה, לקבץ את הערכים 3 ו-4 בקבוצה נפרדת מ 1 ו-2.
נוודא שלא חסרים נתונים ושכל הערכים הם מספריים כדי לעמוד בדרישות XGBoost:
# for XGBoost we need validate that all
# the columns are numeric and have values
df_clean.info()Int64Index: 889 entries, 0 to 890 Data columns (total 19 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Survived 889 non-null int64 1 Age 889 non-null float64 2 SibSp 889 non-null int64 3 Fare 889 non-null float64 4 Sex_female 889 non-null uint8 5 Sex_male 889 non-null uint8 6 Embarked_C 889 non-null uint8 7 Embarked_Q 889 non-null uint8 8 Embarked_S 889 non-null uint8 9 Pclass_1 889 non-null uint8 10 Pclass_2 889 non-null uint8 11 Pclass_3 889 non-null uint8 12 Parch_0 889 non-null uint8 13 Parch_1 889 non-null uint8 14 Parch_2 889 non-null uint8 15 Parch_3 889 non-null uint8 16 Parch_4 889 non-null uint8 17 Parch_5 889 non-null uint8 18 Parch_6 889 non-null uint8 dtypes: float64(2), int64(2), uint8(15) memory usage: 47.7 KB
- מסד הנתונים עומד בדרישות של XGBoost מבחינה זו שלא חסרים ערכים וכל הנתונים הם מספריים.
- אפשר לראות שינוי בהרכב העמודות הודות ל- one hot encoding דוגמת 2 עמודות Sex_female, Sex_male שמחליפות את את העמודה Sex .
נפריד את סט הנתונים למשתנים תלויים ובלתי תלויים:
# separate into dependent and independent variables
y = df_clean.pop('Survived')
X = df_cleanנוודא ש-X לא מכיל את העמודה Survived שאותה אנו מעוניינים שהמודל יחזה:
# make sure X does not contain the 'Survived' column
X.columns.valuesarray(['Age', 'SibSp', 'Fare', 'Sex_female', 'Sex_male', 'Embarked_C',
'Embarked_Q', 'Embarked_S', 'Pclass_1', 'Pclass_2', 'Pclass_3',
'Parch_0', 'Parch_1', 'Parch_2', 'Parch_3', 'Parch_4', 'Parch_5',
'Parch_6'], dtype=object)
כיוון שסט הנתונים אינו מאוזן נפריד לסט אימון ומבחן תוך הקפדה שהתפלגות השורדים בסטים תשמר את היחס במסד הנתונים. לשם כך נשתמש בפרמטר stratify:
# split into train and test datasets
# stratify to keep the ratio of y
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=.7,
random_state=42,
stratify=y)נוודא שהסטים אימון ומבחן שומרים על היחס המקורי.
היחס במסד הנתונים לפני החלוקה:
sum(y)/len(y) #0.38245219347581555
היחס בסט האימון והמבחן:
sum(y_train)/len(y_train) #0.38263665594855306
sum(y_test)/len(y_test) #0.38202247191011235
בניית מודל XGBoost ראשוני
אפשר להשתמש ב-XGBoost למשימות רגרסיה או סיווג. כדי לחזות מי שרד את הטיטאניק נשתמש בו כמסווג באמצעות הפונקציה xgboost.XGBClassifier:
import xgboost as xgb
xgb_classifier = xgb.XGBClassifier(objective='binary:logistic', missing=1, seed=42)
xgb_classifier = xgb_classifier.fit(X_train,
y_train,
verbose=True,
early_stopping_rounds=10,
eval_metric='aucpr',
eval_set=[(X_test,y_test)])- missing=1 כי זה מה שעבד לי בניסוי מקדים.
- early_stopping_rounds=10 מספר הסיבובים עד לעצירה מוקדמת בתנאי שהמודל לא מתקדם. בסוף כל סיבוב המודל יעריך את ביצועיו על סט המבחן ואם לא תהיה התקדמות במשך 10 סיבובים הוא יפסיק לרוץ.
- AUC הוא המדד להתקדמות המודל.
[0] validation_0-aucpr:0.80068 Will train until validation_0-aucpr hasn't improved in 10 rounds. [1] validation_0-aucpr:0.79519 [2] validation_0-aucpr:0.79128 [3] validation_0-aucpr:0.80007 [4] validation_0-aucpr:0.81092 [5] validation_0-aucpr:0.80871 [6] validation_0-aucpr:0.81126 [7] validation_0-aucpr:0.81616 [8] validation_0-aucpr:0.81539 [9] validation_0-aucpr:0.81521 [10] validation_0-aucpr:0.81572 [11] validation_0-aucpr:0.81069 [12] validation_0-aucpr:0.81155 [13] validation_0-aucpr:0.81436 [14] validation_0-aucpr:0.81368 [15] validation_0-aucpr:0.81003 [16] validation_0-aucpr:0.80966 [17] validation_0-aucpr:0.81101 Stopping. Best iteration: [7] validation_0-aucpr:0.81616
החל מסיבוב 7 לא נרשמה התקדמות ולכן המודל עצר את עצמו בסיבוב 17 ע"פ דרישת הפרמטר עצירה מוקדמת early stopping. זה אומר שהמערך הטוב ביותר של עצי החלטה שאליו הגיע המודל היה בסיבוב 7, ועל כן זה המערך שבו נשתמש להערכת ביצועי המודל על סט המבחן.
הערכת ביצועי המודל הראשוני
נעריך את איכות המודל שמצא XGBoost על דוגמאות המבחן.
מהם הערכים שהמודל חזה?
y_pred = xgb_classifier.predict(X_test)print(y_pred)array([1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 0,
0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1,
0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0,
0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0,
0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0,
0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0,
1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0,
0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1,
0, 0, 1])
הפונקציה הבאה תציג confusion matrix שיעזור לנו להעריך את התוצאות:
from sklearn.metrics import classification_report, confusion_matrix
def plot_confusion_matrix(cf_matrix):
print('Confusion Matrix')
ax= plt.subplot()
sns.heatmap(cf_matrix, annot=True, ax = ax, fmt='d', cmap='Blues', cbar=False)
# labels, title and ticks
ax.set_title('Confusion Matrix')
ax.set_xlabel('Predicted labels')
ax.set_ylabel('Actual labels')
ax.xaxis.set_ticklabels(['Survived', 'Not'])
ax.yaxis.set_ticklabels(['Survived', 'Not'])נשווה את ערכי ההישרדות החזויים לערכים בפועל:
cf_matrix = confusion_matrix(y_test, y_pred)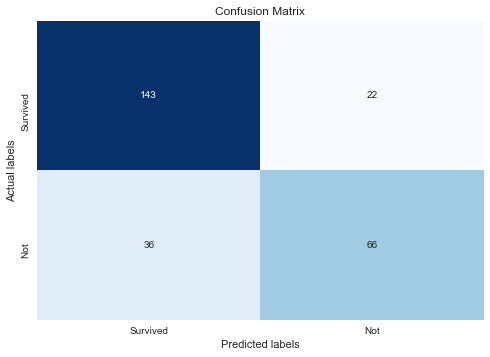
נראה שהמודל הצליח יותר בסיווג מי ששרד לעומת אילו שטבעו. נצלול למספרים:
# it is important to estimate the model overall but also by dividing into segments
# especially since the dataset is imbalanced
from sklearn.metrics import classification_report, f1_score
print(classification_report(y_test, y_pred)) precision recall f1-score support
0 0.80 0.87 0.83 165
1 0.75 0.66 0.70 102
accuracy 0.79 267
macro avg 0.78 0.76 0.77 267
weighted avg 0.78 0.79 0.78 267
- בחיזוי מי ששרד המודל מציג יחס F1 של 83% שהוא גבוה משמעותית מהיחס עבור מי שטבע (70% בלבד). יחס F1 חשוב לנו בגלל שסט הנתונים אינו מאוזן בין קבוצת המיעוט והרוב.
המודל מציג יכולות חיזוי פחות טובות עבור קבוצת הטובעים בהתאם לעובדה שהוא נחשף לפחות דוגמאות מסוג זה עקב חוסר האיזון של מסד הנתונים.
ניתן לשפר את ביצועי XGBoost במגוון דרכים, בעיקר בזכות העובדה שהוא מגיע עם מגוון של פרמטרים שאותם ניתן לכוונן fine tuning. לדוגמה, ניתן לאלץ את המודל לשפר את הביצועים עבור הקבוצה הפחות שכיחה באמצעות שינוי הפרמטר scale_pos_weight.
שיפור ביצועי המודל XGBoost באמצעות כוונון פרמטרים fine tuning
בחלק זה של המדריך ננסה לשפר את ביצועי המודל באמצעות בחירת הפרמטרים הטובים ביותר בטכניקה של חיפוש רשת grid search עבור הפרמטרים:
- 'scale_pos_weight' שמשפר את ביצועי המודל על דוגמאות המיעוט.
- 'max_depth' השולט בעומק המרבי של העץ.
- 'min_child_weight' שמטפל בהתאמת יתר לסט האימון overfitting.
'scale_pos_weight' מיועד לאופטימיזציה של מערך נתונים לא מאוזן ובחרתי בשני הפרמטרים האחרים מכיוון שהייתה להם ההשפעה הגדולה ביותר על התוצאה בניסוי מקדמי שערכתי.
ישנם פרמטרים רבים אחרים עליהם ניתן לקרוא בתיעוד. אם אתם עובדים על Jupyter notebook או סביבת colab אתה יכולים להזין את הפקודה לתא:
xgb.XGBClassifierולהקליק את צירוף המקשים Shift + Tab כדי לקרוא את התיעוד בתוך הקוד.
לצורך חיפוש הרשת grid search נייבא את התלוית:
from sklearn.model_selection import RandomizedSearchCV, GridSearchCVשיריצו צירופים שונים של מערך הפרמטרים עד לקבלת הצירוף שיקנה למודל את הביצועים הגבוהים ביותר:
params = {
'max_depth':range(3,10,2),
'min_child_weight':range(1,6,2),
'scale_pos_weight': [0.5, 1, 2, 5, 10, 20]
}- הגעתי לטווח הערכים לעיל אחרי שערכתי מספר ניסויים מקדימים.
ניצור את המודל של XGBoost:
xgb_classifier = xgb.XGBClassifier(objective='binary:logistic', missing=1, seed=42)עליו נפעיל את חיפוש הרשת grid search:
random_search = RandomizedSearchCV(xgb_classifier, param_distributions=params, n_iter=5, scoring='roc_auc', n_jobs=-1, cv=5, verbose=3)- AUC משמש להערכת ביצועי המודלים שיווצרו בתהליך.
- cv מציין את מספר ה-cross validations מה שאומר שמעריכים את מסד הנתונים ע"ס סטים שנבחרים באקראי בין החזרות. בסה"כ 5 חזרות ע"פ הפרמטר n_iter.
- n_jobs אומר למודל בכמה מעבדים להשתמש. הערך -1 מתיר למודל להשתמש בכמה שהוא צריך.
נריץ את תהליך האופטימיזציה:
random_search.fit(X_train, y_train)Fitting 5 folds for each of 5 candidates, totalling 25 fits
[Parallel(n_jobs=-1)]: Using backend LokyBackend with 6 concurrent workers.
[Parallel(n_jobs=-1)]: Done 23 out of 25 | elapsed: 1.3s remaining: 0.1s
[Parallel(n_jobs=-1)]: Done 25 out of 25 | elapsed: 1.3s finished
RandomizedSearchCV(cv=5,
estimator=XGBClassifier(base_score=None, booster=None,
colsample_bylevel=None,
colsample_bynode=None,
colsample_bytree=None, gamma=None,
gpu_id=None, importance_type='gain',
interaction_constraints=None,
learning_rate=None,
max_delta_step=None, max_depth=None,
min_child_weight=None, missing=1,
monotone_constraints=None,
n_estimators=100, n_jobs=None,
num_parallel_tree=None,
random_state=None, reg_alpha=None,
reg_lambda=None,
scale_pos_weight=None, seed=42,
subsample=None, tree_method=None,
validate_parameters=None,
verbosity=None),
n_iter=5, n_jobs=-1,
param_distributions={'max_depth': range(3, 10, 2),
'min_child_weight': range(1, 6, 2),
'scale_pos_weight': [0.5, 1, 2, 5, 10,
20]},
scoring='roc_auc', verbose=3)
טוב. מה מערך הפרמטרים שנותן את התוצאות הטובות ביותר?
random_search.best_estimator_XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1, gamma=0, gpu_id=-1, importance_type='gain', interaction_constraints='', learning_rate=0.300000012, max_delta_step=0, max_depth=3, min_child_weight=3, missing=1, monotone_constraints='()', n_estimators=100, n_jobs=6, num_parallel_tree=1, random_state=42, reg_alpha=0, reg_lambda=1, scale_pos_weight=10, seed=42, subsample=1, tree_method='exact', validate_parameters=1, verbosity=None)
- המשתנה random_search.best_estimator_ מציג את ערכי כל הפרמטרים של XGBoost שעליהם מתבסס המודל הטוב ביותר ולא רק את אלה שאת השפעתם בדקנו.
מהם הערכים הטובים ביותר עבור הפרמטרים אותם אנחנו מכווננים?
random_search.best_params_{'scale_pos_weight': 1, 'min_child_weight': 5, 'max_depth': 7}
- הפרמטרים נראים סבירים כי הם מאמצע הטווח שהעברנו לבדיקת הפונקציה. אם הם היו הגבוהים או הנמוכים ביותר בטווח היינו צריכים לחזור על התהליך.
נציב לתוך XGBoost את הפרמטרים האופטימליים אותם מצאנו בתהליך:
xgb_classifier_optimized = xgb.XGBClassifier(objective='binary:logistic',
missing=1,
seed=42,
scale_pos_weight=1,
min_child_weight=5,
max_depth=7)נריץ:
xgb_classifier_optimized = xgb_classifier_optimized.fit(X_train,
y_train,
verbose=True,
early_stopping_rounds=10,
eval_metric='aucpr',
eval_set=[(X_test,y_test)])[0] validation_0-aucpr:0.79159 Will train until validation_0-aucpr hasn't improved in 10 rounds. [1] validation_0-aucpr:0.78150 [2] validation_0-aucpr:0.79851 [3] validation_0-aucpr:0.79582 [4] validation_0-aucpr:0.79792 [5] validation_0-aucpr:0.80055 [6] validation_0-aucpr:0.80353 [7] validation_0-aucpr:0.80822 [8] validation_0-aucpr:0.80224 [9] validation_0-aucpr:0.80248 [10] validation_0-aucpr:0.81121 [11] validation_0-aucpr:0.80428 [12] validation_0-aucpr:0.80266 [13] validation_0-aucpr:0.80650 [14] validation_0-aucpr:0.80724 [15] validation_0-aucpr:0.80111 [16] validation_0-aucpr:0.80554 [17] validation_0-aucpr:0.80586 [18] validation_0-aucpr:0.80336 [19] validation_0-aucpr:0.80075 [20] validation_0-aucpr:0.79873 Stopping. Best iteration: [10] validation_0-aucpr:0.81121
- הפעם נדרשו 10 סיבובים של בניית עצי החלטה כדי להגיע למודל שנותן את הביצועים הטובים ביותר.
נבחן את מידת הסיווג הנכון:
y_pred_optimized = xgb_classifier_optimized.predict(X_test)cf_matrix_optimized = confusion_matrix(y_test, y_pred_optimized)
plot_confusion_matrix(cf_matrix_optimized)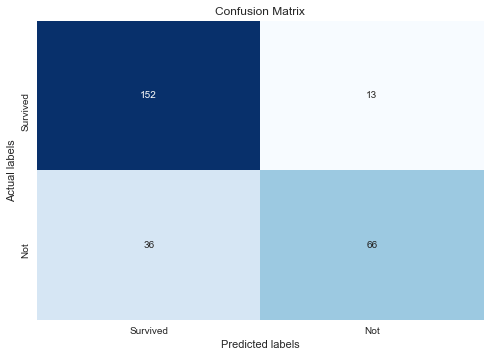
נצלול למספרים:
print(classification_report(y_test, y_pred_optimized)) precision recall f1-score support
0 0.81 0.92 0.86 165
1 0.84 0.65 0.73 102
accuracy 0.82 267
macro avg 0.82 0.78 0.80 267
weighted avg 0.82 0.82 0.81 267
- לא זו בלבד שיחס f1 עלה עבור כל הדוגמאות מ-78% ל-82% גם נרשמה עלייה משמעותית בביצועי המודל עבור 2 הקבוצות, הטובעים והשורדים.
המסקנה היא שכדאי לעשות כיוונון של הפרמטרים של XGBoost כדי לשפר את יכולות המודל.
שימוש בשכל כדי לקבוע את ערכו של הפרמטר scale_pos_weight
אפשר לתת לאקראיות למצוא בשבילנו את הפרמטרים הטובים ביותר, ואפשר להשתמש בידע שלנו על הדרך שבה עובד האלגוריתם כדי לנסות לשפר את התוצאות. הפרמטר scale_pos_weight נועד לטפל במצב של סט נתונים לא מאוזן. הערך ברירת המחדל שלו הוא 1 תחת ההנחה שיש יחס של 1:1 בין הדוגמאות השייכות לקבוצת הרוב והמיעוט. המשמעות היא שהשגיאות שעושה המודל במהלך האימון על קבוצת הרוב מקבלות את אותו המשקל כמו השגיאות על קבוצת המיעוט. אבל במצב שבו סט הנתונים לא מאוזן כדאי לנו שהמודל יתן משקל עודף לטעויות על דוגמאות המיעוט. מה שיעור המשקל העודף? גישה מקובלת היא להציב לתוך ערך זה את היחס של מספר הדוגמאות בין קבוצת הרוב והמיעוט על פי הנוסחה:
scale_pos_weight = count_majority_samples / count_minority_samples
במקרה שלנו, מספר הדוגמאות בקבוצת הרוב והמיעוט הוא:
count_minority = sum(y_test)
count_majority = len(y_test) - count_minority
print(count_minority, count_majority)102 165
ועל כן היחס הוא:
scale_pos_weight = 165 / 102
print("{:.2f}".format(scale_pos_weight))1.62
נאמן את המודל עם הפרמטר scale_pos_weight=1.62
xgb_classifier_optimized = xgb.XGBClassifier(objective='binary:logistic',
missing=1,
seed=42,
scale_pos_weight=1.62,
min_child_weight=5,
max_depth=7)
xgb_classifier_optimized = xgb_classifier_optimized.fit(X_train,
y_train,
verbose=True,
early_stopping_rounds=10,
eval_metric='aucpr',
eval_set=[(X_test,y_test)])נחלץ את התחזיות ונבחן את ההשפעה על התוצאות אליהם מגיע המודל:
y_pred_optimized = xgb_classifier_optimized.predict(X_test)
print(classification_report(y_test, y_pred_optimized)) precision recall f1-score support
0 0.87 0.81 0.84 165
1 0.72 0.80 0.76 102
accuracy 0.81 267
macro avg 0.79 0.80 0.80 267
weighted avg 0.81 0.81 0.81 267
- ערך f1 הכללי נשאר ללא שינוי, ירד קצת עבור קבוצת הרוב ועלה עבור קבוצת המיעוט.
המסקנה היא שכדאי לבדוק כמה גישות בשביל לקבל את התוצאות הטובות ביותר.
אילו תכונות של מסד הנתונים תרמו הכי הרבה לסיווג?
אתגר מרכזי כשעובדים עם מודלים של למידת מכונה הוא הניסיון להבין מדוע מקבלים תוצאות מסויימות. שיטות שונות מציעות רמות שונות של שקיפות כאשר XGBoost מאפשר לזהות את אותם הפיצ'רים שתורמים הכי הרבה לתחזית באמצעות feature importance.
הפונקציה הבאה מאפשרת לנו לקבל טבלה שבה העמודות מסודרות ע"פ המידה בה תרמו לסיווג המודל:
# make a dataframe of the feature importance
def get_feature_importance(model):
features_list = list(xgb_classifier_optimized.get_booster().get_fscore().items())
features_df = pd.DataFrame(features_list, columns=['feature','importance']).sort_values('importance', ascending=False)
return features_dfנריץ את הפונקציה:
get_feature_importance(xgb_classifier_optimized)התוצאה:
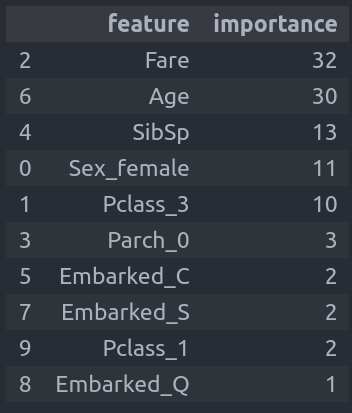
- הפיצ'רים מסודרים בסדר יורד על פי תרומתם לתחזית. קודם כל, מחיר הכרטיס, קצת אחריו הגיל, ואח"כ מספר האחים, המין והמחלקה.
אפשר לתאר את חשיבות הפיצ'רים גם בגרף באמצעות הקוד הבא:
from xgboost import plot_importance
from matplotlib import pyplot
# plot feature importance
plot_importance(xgb_classifier_optimized)
pyplot.show()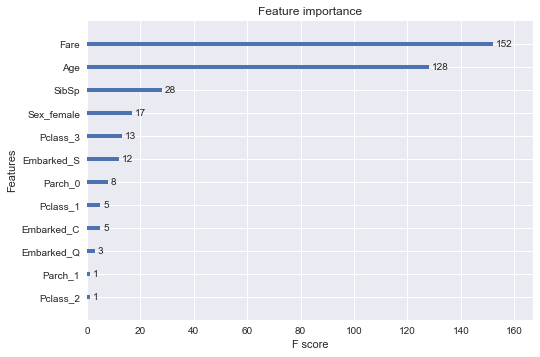
ייצוא ויבוא המודל
אחרי כל העבודה אנחנו רוצים לשמור את המודל להמשך עבודה. אנחנו יכולים לשמור בפורמט של txt או json באמצעות הפונקציה save_model:
# save to JSON
xgb_classifier_optimized.save_model('titanic_model.json')
# save to txt
xgb_classifier_optimized.save_model('titanic_model.txt')כדי לטעון את המודל נשתמש בפונקציה load_model:
loaded_model = xgb.XGBClassifier(objective='binary:logistic', missing=1, seed=42)
loaded_model.load_model('titanic_model.json')ועכשיו, אנחנו יכולים לעבוד עם המודל.
הבנת המודל באמצעות SHAP
דרך מאוד מקובלת היום לנסות ולהסביר את התוצאות היא על ידי שימוש ב-SHAP. נשתמש בכלי כדי לאתר את הפיצ'רים שתרמו הכי הרבה לסיווג ובאיזה אופן הם תרמו:
import shap
shap.initjs()
# 'margin' is the real contribution to the prediction
explainer = shap.TreeExplainer(loaded_model, model_output='margin')
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X)

- הפיצ'רים מוצגים לפי סדר התרומה שלהם לסיווג מהגבוה לנמוך.
- ערך גבוה יותר על ציר ה-X פירושו שהמודל חוזה סיכוי גבוה יותר להשרדות.
- באדום מסומנים המקרים בהם התרומה של הפיצ'ר היא גבוהה ובכחול המקרים בהם התרומה נמוכה.
- הפיצ'ר המשמעותי ביותר הוא מינו של האדם. בהתאם, הנשים והילדות מתקבצות בצד השמאלי.
- Parch_0 מיוחס למקרים בהם הנוסע שט לבד. במקרים אילה עלו סיכויי ההשרדות.
- Fare מראה השפעה חיובית של מחיר הכרטיס על ההשרדות. ככל שמחיר הכרטיס גבוה יותר סיכויי ההשרדות עולים.
- סיכויי ההשרדות קטנים עם הגיל.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.