
תיאום קנה מידה (feature scaling) בהכנת הנתונים ללמידת מכונה
עבור מודלים רבים של למידת מכונה תיאום קנה המידה (feature scaling) הוא חלק חשוב ואף חיוני של הכנת הנתונים. במדריך זה נסביר מדוע צריך לתאם את קנה המידה, ונלמד את שתי הגישות העיקריות, סטנדרטיזציה ונורמליזציה.

מדוע לתאם את קנה המידה של הנתונים?
הצורך בתיאום קנה המידה של הנתונים (feature scaling) קיים באותם המקרים בהם תכונות של מסד הנתונים הם בעלות קנה מידה שונה. לדוגמה, מודל בשירות חקלאי שמגדל אבטיחים ומבחין בין אבטיחים לשיווק לחנויות לבין פרי פסול. את המודל מזינים בנתונים על משקל הפרי ומספר הפגיעות על הקליפה (מעיכות, קילופים, שברים). הנתונים אינם על אותה הסקאלה כי המשקל נע בין 1,000 ל-5,000 גרם בעוד מספר הפגיעות נמדד ביחידות בודדות. לרוב, לא יותר מפגיעה אחת או שתיים.
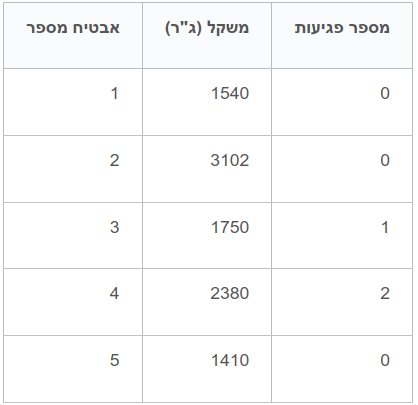
במודלים מבוססי מרחק דוגמת KNN סדרי גודל שונים של עמודות הנתונים עלולים לגרום לעיוות ניבויי המודל. לדוגמה, מודל המסייע לחקלאי לזהות אבטיחים לשיווק יביא בחשבון את משקל הפרי הנמדד באלפי גרמים אולם יזניח את כמות הפגיעות הנמדדת ביחידות בודדות.
הבעיה של הטיית המודל לתכונות בגלל שקנה המידה שלהם גבוה יותר אופיינית למודלים אשר מחשבים את המרחק בין נתונים, דוגמת: KNN, k-means ו-PCA. בעיה אחרת קיימת במודלים שמשתמשים ב-gradient descent, דוגמת רשתות נוירונים ורגרסיה לינארית או לוגיסטית, בהם נתונים שלא עברו תיאום קנה מידה (feature scaling) מעכבים את התכנסות המודל לתוצאה.
איך לגרום למודל להתחשב במשקל וגם במספר הפגיעות? ובהקשר יותר רחב, איך נגרום למודל להתחשב בגודל היחסי של הנתונים במקום בגודל האבסולוטי? הפתרון הוא תיאום קנה המידה (feature scaling) שגורם לעמודות הנתונים השונות להיות באותו קנה מידה.
איך לתאם את קנה המידה של הנתונים?
השיטות המקובלות ביותר לתיאום קנה המידה (feature scaling) הם סטנדרטיזציה ונורמליזציה. נתונים שעוברים סטנדרטיזציה מקבלים ממוצע 0 וסטיית תקן 1. נורמליזציה תוחמת את הנתונים בין 0 ל-1.
מתי לתאם את קנה המידה של הנתונים?
תיאום קנה המידה של נתונים באמצעות סטנדרטיזציה ונורמליזציה חיוני במקרה של מודלים מבוססי מרחק גיאומטרי, דוגמת: k-means, KNN, PCA ו-SVM. במקרה של KNN וk-means המחשבים את המרחק האוקלידי בין הנתונים הבדל של סדרי גודל מעוות את התמונה לטובת תכונות מסדר גודל גבוה. PCA מנסה ללכוד את התכונות שהשונות בהם היא הגבוהה ביותר, והשונות היא גבוהה יותר עבור תכונות מסדרי גודל גבוהים.
גם במקרה של מודלים המשתמשים ב-gradient descent, דוגמת רשתות נוירונים ורגרסיה (לינארית ולוגיסטית) רצוי לתאם את קנה המידה של הנתונים כדי להאיץ את הלמידה בגלל שההתכנסות למינימום היא מהירה יותר כשהערכים המספריים של הנתונים נמוכים וההתפלגות אחידה.
איך לתאם את קנה המידה של הנתונים?
שתי שיטות משמשות לתיאום קנה המידה של הנתונים: סטנדרטיזציה ונורמליזציה.
איך עושים סטנדרטיזציה?
נתונים שעוברים סטנדרטיזציה מקבלים ממוצע 0 וסטיית תקן 1 ע"פ הנוסחה:
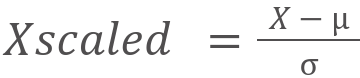
- X הוא הערך המקורי של הדוגמה
- μ הוא ממוצע העמודה
- σ היא סטיית התקן
- החישוב נעשה על כל עמודת נתונים בנפרד.
חשוב שהנתונים הגולמיים יציגו התפלגות נורמלית.
כדי להדגים כיצד עובדת נורמליזציה נחזור לדוגמה איתה פתחנו את המדריך של מודל לסיווג אבטיחים.
בשביל לעשות לנתונים סטנדרטיזציה נשתמש במתודה StandardScaler של SciKit-Learn.
נייבא את התלויות:
import pandas as pd
import numpy as npנייבא את המתודה של sklearn:
from sklearn.preprocessing import StandardScalerנהפוך את הנתונים ל-dataframe:
df = pd.DataFrame({'weight': [1540, 3102, 1750, 2380, 1410],
'defects': [0,0,1,2,0]},
index = [1,2,3,4,5])weight defects 1 1540 0 2 3102 0 3 1750 1 4 2380 2 5 1410 0
כרגיל כשעובדים עם מתודות של sklearn, ניצור אובייקט מהמתודה:
scaler = StandardScaler()נשתמש במתודה fit כדי לאפשר לאלגוריתם ללמוד את סט הנתונים:
scaler.fit(df)נשתמש במתודה transform לעשות את הסטנדרטיזציה של מסד הנתונים בפועל:
scaler.transform(df)התוצאה:
array([[-0.78995343, -0.75 ],
[ 1.69575822, -0.75 ],
[-0.45576685, 0.5 ],
[ 0.54679291, 1.75 ],
[-0.99683084, -0.75 ]])
- כל פריט ברשימה שייך לדוגמה אחת. בכל פריט הערך הראשון הוא המשקל שעבר סטנדרטיזציה. השני - מספר הפגיעות בפרי.
איך מנרמלים?
נורמליזציה תוחמת את הנתונים בטווח מוגדר. בדרך כלל, בין 0 ל-1. החישוב נעשה על כל עמודת נתונים בפני עצמה באמצעות הנוסחה:
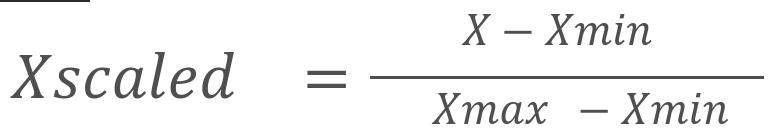
נשתמש בשיטה כאשר סטיית התקן קטנה וההתפלגות אינה גאוסיאנית. צריך לקחת בחשבון שהשיטה רגישה לנקודות קיצוניות (outliers).
בשביל לנרמל את הנתונים נשתמש במתודה MinMaxScaler של SciKit-Learn.
from sklearn.preprocessing import MinMaxScalerניצור אובייקט מהמתודה:
scaler = MinMaxScaler()נפעיל את המתודות fit ואחריה transform כדי לאפשר לאלגוריתם לתאם את הנתונים:
scaler.fit(df)
scaler.transform(df)התוצאה:
array([[0.07683215, 0. ],
[1. , 0. ],
[0.20094563, 0.5 ],
[0.57328605, 1. ],
[0. , 0. ]])
- ערכם של המשתנים שעברו נורמליזציה נמצא בטווח שבין 0 ל-1.
מתי אין צורך בתיאום קנה מידה?
מודלים שלא דורשים תיאום קנה מידה (feature scaling) מסתמכים על חוקים, ולכן אינם מושפעים מסדרי גודל. לדוגמה, עצי החלטה, Random Forest, XGBoost ושאר טכניקות ה-boosting.
מודלים דוגמת LDA ו-Naive Bayes מודעים להבדלים בסדרי הגודל בין התכונות ולכן אין צורך לעשות feature scaling לנתונים שמזינים לתוכם.
בכל מקרה, כשעובדים עם מודל חשוב מאוד להיוועץ בתיעוד כדי לבדוק על איזו שיטה ממליצים מפתחי האלגוריתם. כשהתשובה לא ברורה כדאי לערוך ניסוי מקדים ללא תיאום ועם תיאום בשתי הגישות, נורמליזציה וסטנדרטיזציה. ובכל מקרה, אם קיים ספק עדיף לתאם את קנה המידה של הנתונים. אם לא יועיל, כנראה שלא יזיק.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.