
מודלים ללמידת מכונה של SciKit-Learn
scikit-learn היא הספרייה הפופולרית ביותר של פייתון ללמידת מכונה הודות למתודות רבות המשמשות לסיווג ורגרסיה והודות לקלות השימוש. במדריך זה נדגים את השימוש ב-scikit-learn בלמידת מכונה, ונראה כמה זה פשוט להגיע לתוצאה. בנוסף, נסקור מודלים שימושיים במיוחד שמציעה הספריייה.

למידת מכונה מורכבת מ-5 שלבים:
- ייבוא הספריות
- ייבוא מסד הנתונים
- הכנת הנתונים ללמידת מכונה
- אימון המודל
- הערכת המודל
את כל השלבים נדגים במדריך על ידי כך שנפתח ונעריך מודל רגרסיה פשוט במיוחד שחוזה את מחירי בתים על סמך גודלם.
ייבוא הספריות
import numpy as np
import pandas as pd
from sklearn import linear_model- Numpy לעבודה עם מערכים רב-ממדיים.
- Pandas לסידור ולסינון מידע בדומה לאקסל.
- SciKit-Learn משמשת ללמידת מכונה. במקרה זה, אנו מייבאים את המתודה linear_model שמתאימה קו לנקודות כמו שלמדנו בבית ספר. כי המדריך הוא בסיסי ואני רוצה להתחיל ממשהו פשוט וטוב.
ייבוא מסד הנתונים
מסד הנתונים במדריך מכיל את המחיר של בתים שנמכרו במדינת סקרמנטו בארה"ב לצד גורמים שעשויים להשפיע על המחיר דוגמת שטח הבית ומספר החדרים. תוכלו להוריד אותו מכאן.
df = pd.read_csv("../data/sacramentorealestatetransactions.csv",usecols=["sq__ft", "price"])המתודה read_csv של ספריית pandas קורא את נתוני הקובץ בפורמט CSV, ומאכלס את המשתנה df (ר"ת של data frame).
מסד הנתונים כולל 2 עמודות בלבד, מחיר ושטח. נסקור את מסד הנתונים:
האם חסרים נתונים?
df.isnull().sum().sum()0
- לא
מה הנתונים הסטטיסטיים? דוגמת: ממוצע, סטיית תקן וחציון ?
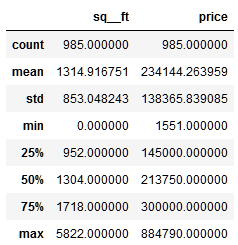
הכנת הנתונים ללמידת מכונה
הכנת הנתונים ללמידת מכונה כוללת בדרך כלל את ניקוי הנתונים ונורמליזציה לפני שמפצלים את הנתונים לקבוצות. מקבוצת הלימוד המודל לומד, וקבוצת המבחן משמשת להערכת ביצועי המודל.
ננקה את מסד הנתונים מדוגמאות חריגות:
# Remove the outliers
filtered_data = df[(df.sq__ft > 10) & (df.sq__ft < 5000)]אנחנו מעוניינים למצוא את המחיר המיוצג בעמודה price על סמך שטח הבתים המיוצג בעמודה sq__ft. המחיר הוא המשתנה התלוי y על סמך יתר המשתנים הבלתי תלויים המיוצגים באות X גדולה.
# Define the independent variable (X) vs. the dependent (y)
X = df[["sq__ft"]].values
y = df["price"].valuesנשתמש במתודה train_test_split כדי לפצל את הנתונים בין קבוצת לימוד ומבחן.
# Split the data to test and train groups
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)- המתודה מערבבת את הדוגמאות ומפצלת את לשתי קבוצות כאשר קבוצת הלימוד מכילה 67% מדוגמאות מסד הנתונים ויתר הדוגמאות מוקצות לקבוצת המבחן.
אימון המודל
העבודה עם המתודות של SciKit-Learn עשויה להיות פשוטה מאוד. ,כל מה שצריך הוא ליצור אובייקט מהמתודה ולהפעיל את המתודה fit() של האובייקט על קבוצת דוגמאות הלמידה:
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(X_train, y_train)זהו! המודל שלנו למד. עד כמה הוא מוצלח?
הערכת ביצועי המודל
נעריך את ביצועי המודל על קבוצת המבחן באמצעות המתודה predit():
# Make predictions using the testing set
y_pred = regr.predict(X_test)- המשתנה y_pred מכיל את התחזיות של המודל לגבי המחירים בקבוצת המבחן.
מכיוון שזה מודל רגרסיה נעריך את הביצועים שלו באמצעות מדד השונות המוסברת, R2:
print("R-squared for testing dataset: %.2f" % r2_score(y_test, y_pred))0.45
- המשמעות היא שהמודל המאוד פשוט שלנו יודע להסביר 45% ממחיר דירה.
עכשיו כשאנחנו מנוסים מספיק כדי להבין כמה פשוט להשתמש במודלים של SciKit-Learn נלמד באילו מודלים להשתמש לצורך רגרסיה וסיווג.
10 מודלים פופולריים של SciKit-Learn המשמשים לרגרסיה
1. XGBoost Regressor
from xgboost.sklearn import XGBRegressor- אולי המודל הכי טוב ללמידת מכונה מנתונים טבלאיים. מודל יחסית מתקדם שאפשר לראות דוגמה ליישום שלו במדריך חיזוי מחירי מכוניות באמצעות XGBoost.
2. CatBoost Regressor
from catboost import CatBoostRegressor- מודל טוב לא פחות מ- XGBoost נוח לעבודה עם נתונים קטגוריים.
3. Linear Regression
from sklearn.linear_model import LinearRegressionרגרסיה ליניארית. בדומה למה שראינו במדריך.
4. Kernel Ridge
from sklearn.kernel_ridge import KernelRidge
5. Support Vector Machine
from sklearn.svm import SVR
6. Random Forest Regressor
from sklearn.ensemble import RandomForestRegressor
7. Gradient Boosting Regressor
from sklearn.ensemble import GradientBoostingRegressor
8. Bayesian Ridge
from sklearn.linear_model import BayesianRidge
9. Stochastic Gradient Descent regression
from sklearn.linear_model import SGDRegressor
10. Elastic Net
from sklearn.linear_model import ElasticNet
10 מודלים פופולריים של SciKit-Learn המשמשים לסיווג
1. XGBoost Regressor
rom xgboost.sklearn import XGBClassifier- אולי המודל הכי טוב ללמידת מכונה מנתונים טבלאיים. מודל יחסית מתקדם שאפשר לראות דוגמה ליישום שלו כמודל מסווג במדריך מודל למידת מכונה - XGBoost - לראות את העצים בתוך היער.
2. Support Vector Machine (SVM)
from sklearn.svm import SVC- המודל יוצר מישור וירטואלי שמפריד בין הקבוצות.
3. K-nearest neighbor (KNN)
from sklearn.neighbors import KNeighborsClassifier- מוצא את האופן הטוב ביותר לחלק את המודל ל-K קבוצות.
4. Random Forest
from sklearn.ensemble import RandomForestClassifier- מקבץ עצי החלטה ליער לצורך קבלת תוצאה חזקה יותר מכל עץ בנפרד.
5. Naive Bayes
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
6. Logistic Regression
from sklearn.linear_model import LogisticRegression- אולי מפתיע אבל ניתן להשתמש בפונקציה גם לסיווג. לא רק לרגרסיה.
7. Linear Discriminant Analysis (LDA)
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
8. Gradient Boosting Classifier
from sklearn.ensemble import GradientBoostingClassifier
9. AdaBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
10. Gaussian classifier
from sklearn.gaussian_process import GaussianProcessClassifier
סיכום
לקלות היישום של המתודות של SciKit-Learn אין תחרות בעולם למידת המכונה. אם זאת, חלק מהמתודות היותר מתקדמות דורשות ידע כדי ליישם אותם. מקור עיקרי לרכישת הידע הוא בתיעוד של SciKit-Learn . כשרוצים לפתור בעיה של למידת מכונה כדאי לתקוף אותה באמצעות כמה מתודות, ולהשוות בין התוצאות מבחינת דיוק ומדדים נוספים, כמו גם מבחינת היכולת להבין ולתקשר את המודלים ללקוח.
אולי גם זה יעניין אותך
הכנת הנתונים ללמידת מכונה באמצעות SciKit-Learn
רגרסיה קווית באמצעות TensorFlow 2
מודל למידת מכונה - XGBoost - לראות את העצים בתוך היער
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.