
האם נצליח ללמד את המחשב להבחין בין יינות משובחים ופשוטים?
מה גורם ליין משובח להצטיין בטעמו? זו חידה שרק מעטים יודעים את פתרונה. עד כה יחידי הסגולה שידעו להבחין בטיב היין ניחנו בחך רגיש המסוגל להבחין בין אלפי סוגי המולקולות במשקה המשכר – נצר לקבוצות עילית שזוכה לטעום אלפי דוגמאות מכל העולם בחסות ייננים מומחים. במדריך זה ננסה ללמד את המחשב להבחין בין יינות משובחים ופשוטים על סמך מספר מצומצם של תכונות כימיות. מעניין האם המכונה תצליח לעמוד במשימה שמעטים האנשים שמסוגלים לעמוד בה?

אחרי שבמדריך קודם למדנו לסווג זני פרחים באמצעות מודל למידת מכונה מבוסס Keras, במדריך זה נלמד כיצד לסווג בינארית כאשר קיימות שתי חלופות בלבד. במדריך, ננסה ללמד את המחשב להבחין בין יינות משובחים לפשוטים על סמך מסד נתונים הכולל 1,500 דוגמאות יינות שטיבם הוערך על ידי טועמים אנושיים וידוע לנו הרכבם הכימי. כולל: רמת חומציות, אלכוהול, ריכוז סוכרים וסולפטים. מעניין האם המודל במדריך יצליח לחקות את יכולת הטעימה של החך האנושי?
המדריך מתייחס לנקודות עקרוניות, ומשמיט חלק מהקוד. צרפתי קובץ ipynb של המדריך שאותו אתם מוזמנים להוריד מכאן:binary_classification_keras.ipynb
ייבוא תלויות
נייבא את החבילות הבסיסיות :
# Import the basic packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as snsNumpy - היא ספרייה של פייתון שמאפשרת לעבוד עם מערכים ובפרט מערכים רב-מימדיים.
Pandas - תלויה ב-Numpy ומאפשרת לעבוד עם מידע שניתן לסדר בטבלה. הספרייה מאפשרת לסקור את המידע, לחלק לקבוצות, להוסיף ולהוריד עמודות, לבחור טווח של נתונים, ועוד.
ב- Matplotlib ו- seaborn נשתמש להצגת מידע באמצעות גרפים ותרשימים.
בהמשך נייבא ספריות נוספות: חלוקת הנתונים לקבוצת אימון וביקורת תעשה באמצעות sklearn, לאיתור נקודות חריגות וסטנדרטיזציה נשתמש ב- scipy ואת המודל נבנה באמצעות tensorflow.keras.
2. מטרת המדריך
ננסה לגרום למחשב להבחין בין יינות משובחים לנמוכי איכות על בסיס מסד נתונים המכיל מדידות עם הרכבם הכימי של יינות.
3. ייבוא מסד הנתונים
את מסד הנתונים הכולל נתונים אודות הרכבם הכימי של דוגאות יין אדום הורדתי מ- Wine quality database. מסד הנתונים בפורמט CSV כולל 12 עמודות: 11 עמודות של מידע כמותי הכולל מדידות חומציות, סוכר, גופרית, ועמודה נוספת עם דירוג האיכות של היין כפי שקבעו טועמים אנושיים.
wine = pd.read_csv('winequality-red.csv', sep=';')wine.head()
4. סקירת הנתונים
נסקור את מסד הנתונים - כמה דוגמאות יש לנו, מה סוג הנתונים בעמודות וכמה דוגמאות חסרות.
wine.info()class 'pandas.core.frame.DataFrame' RangeIndex: 1599 entries, 0 to 1598 Data columns (total 12 columns): fixed acidity 1599 non-null float64 volatile acidity 1599 non-null float64 citric acid 1599 non-null float64 residual sugar 1599 non-null float64 chlorides 1599 non-null float64 free sulfur dioxide 1599 non-null float64 total sulfur dioxide 1599 non-null float64 density 1599 non-null float64 pH 1599 non-null float64 sulphates 1599 non-null float64 alcohol 1599 non-null float64 quality 1599 non-null int64 dtypes: float64(11), int64(1) memory usage: 150.0 KB
מסד הנתונים כולל 1599 דוגמאות, כולן מסוג float מספרי, ללא ערכים חסרים (כל העמודות non-null).
נסקור את הנתונים הסטטיסטיים אודות העמודות באמצעות:
wine.describe()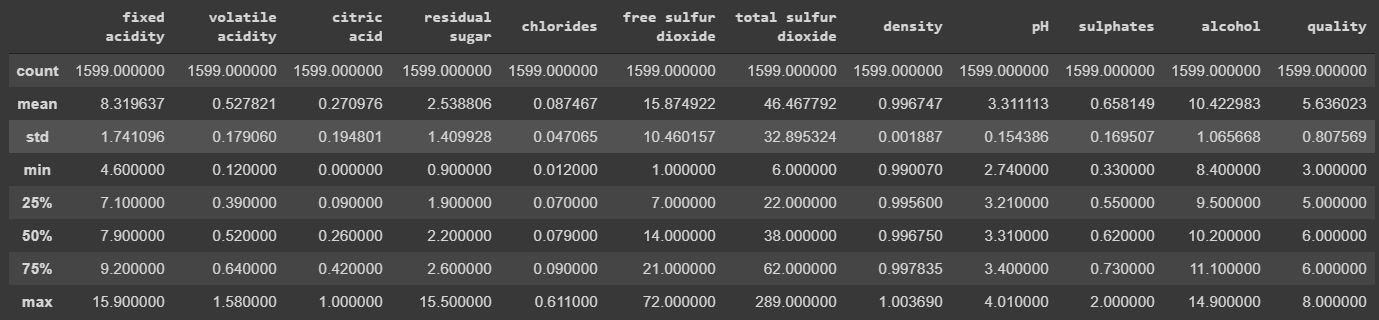
אפשר לראות שעמודות שונות נמצאות על סקאלות שונות. לדוגמה, המקסימום של עמודת chlorides הוא 0.6 לעומת זאת המקסימום של total sulfur dioxide הוא 289. הבדל גדול בין העמודות עלול לגרום למודל להחשיב יותר מדי את התכונות הגבוהות בשקלול התוצאות. בהתאם, משימה עיקרית בהכנת הנתונים ללמידת מכונה יהיה סטנדרטיזציה של הנתונים כדי שהם יתפרשו על פני אותה סקאלה.
5. ניקוי מסד הנתונים מדוגמאות חריגות
נשתמש ב-boxplot כדי לקבל תחושה לגבי קיומם של חריגים:
chart = sns.boxplot(x="variable", y="value", data=pd.melt(wine))
chart.set_xticklabels(chart.get_xticklabels(), rotation=45)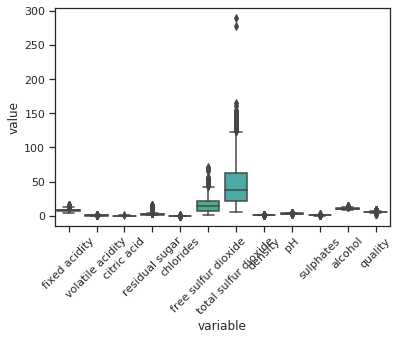
התמונה מלמדת שיש חריגים בעמודות בהם ערכים מסדר הגודל הגבוה ביותר אבל קשה לראות מה קורה בעמודות בהם הערכים נמוכים. לשם זיהוי החריגים באופן ודאי, נשתמש בפונקצית zscore שמחשבת את שיעור סטיית התקן (z) עבור כל ערך ביחס לעמודה שבתוכה הוא נמצא:
from scipy.stats import zscorez0 = wine.apply(zscore)
z0.describe()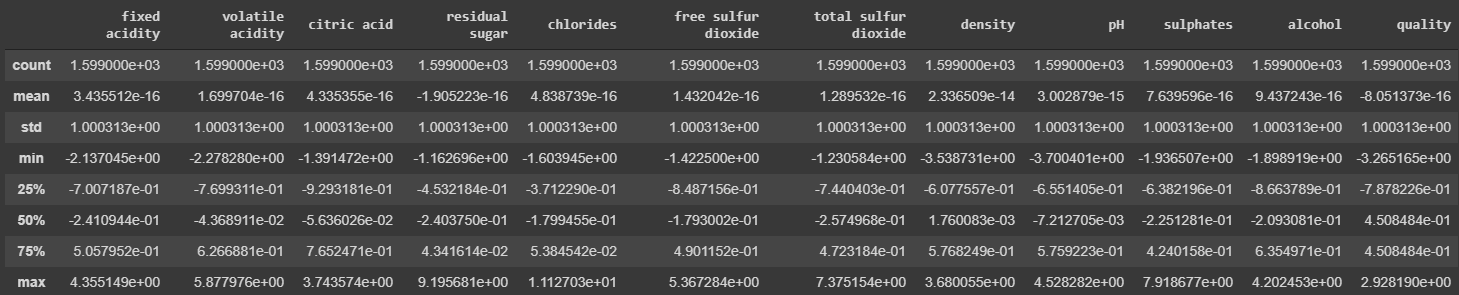
הפונקציה describe מאפשרת למצוא את ערכי המינימום והמקסימום של סטיית התקן עבור כל עמודה. מקובל להחשיב ערכים שחורגים ב-3 סטיות תקן כחריגים, outliers. נסיר ממסד הנתונים את הדוגמאות המכילות חריגים:
z = np.abs(zscore(wine))
z_in = (np.abs(zscore(wine)) < 3)
wine_clean = wine[z_in.all(axis=1)]בתהליך יצרנו את מסד הנתונים wine_clean באמצעות סינון הדוגמאות שהכילו חריגים. בתהליך, ירדנו מ-1599 דוגמאות ל-1451.
האם קיימת קורלציה בין איכות היין וכל אחת מהתכונות האחרות?
wine_clean.corr()['quality'].sort_values(ascending=False)sns.pairplot(wine_clean, x_vars=wine_clean.columns[:4], y_vars='quality')
sns.pairplot(wine_clean, x_vars=wine_clean.columns[4:8], y_vars='quality')
sns.pairplot(wine_clean, x_vars=wine_clean.columns[8:11], y_vars='quality')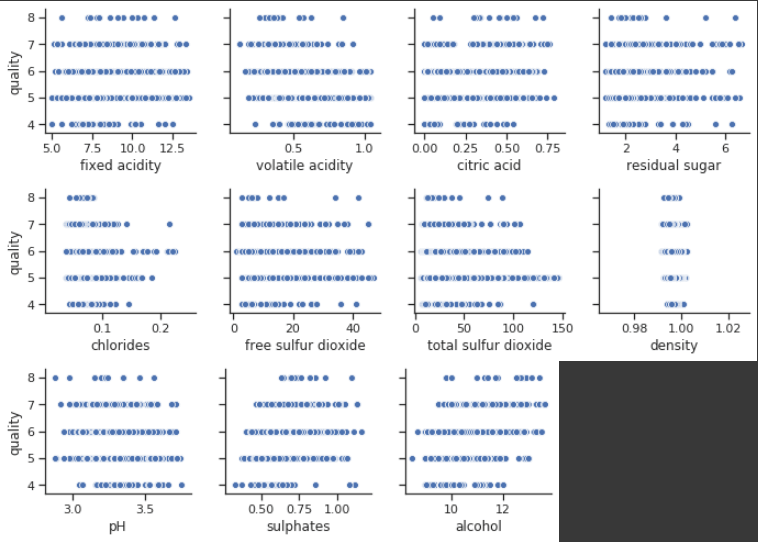
quality 1.000000 alcohol 0.501501 sulphates 0.386567 citric acid 0.243999 fixed acidity 0.145163 residual sugar 0.061482 free sulfur dioxide -0.071202 pH -0.082164 chlorides -0.108787 density -0.167568 total sulfur dioxide -0.237745 volatile acidity -0.353443
הקורלציה הגבוהה ביותר היא עם אלכוהול (0.5), וגם היא בינונית בלבד. כל יתר התכונות מראות קורלציות חלשות ואף שליליות. מעניין האם המודל שלנו יצליח יותר?
6. הכנת הדוגמאות ללמידת מכונה
א. הפרדת מסד הנתונים ל-x ו-y
כל העמודות מלבד האחרונה ישמשו כמשתנים בלתי תלויים מהם נסיק את העמודה האחרונה:
x = wine_clean.iloc[:, :-1]
y = wine_clean.iloc[:, -1]ב. קטגוריזציה של התגיות
התגיות (ציר y) הם מסוג מספרי ועל כן האנליזה המתבקשת היא מסוג רגרסיה. אבל אני רוצה להבחין בין יינות על פי טיבם לכן אחלק את התגיות לשתי קטגוריות, משובחים לעומת נחותים, bad לעומת good:
# Divide the target (y) into 2 categories
bins = [3.0, 5.0, 8.0]
labels = ['bad','good']
wine_clean['quality_points'] = pd.cut(y, bins, labels=labels)כמה דוגמאות מכל סוג?
wine_clean.quality_points.value_counts()good 787 bad 664 Name: quality_points, dtype: int64
sns.countplot(wine_clean.quality_points)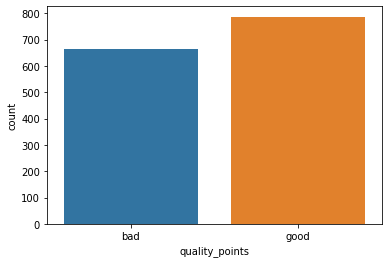
ג. הפיכת הקטגוריות משמיות למשתני דמה dummy variables
הקטגוריות הם שמיות אבל המודל זקוק למספרים:
d = pd.get_dummies(wine_clean.loc[:,'quality_points'])d.head()
נשמיט את עמודת bad ונשאר עם העמודה good כי אנחנו לא צריכים יותר מעמודה אחת לצורך סיווג בינארי:
y = d.drop('bad', axis=1)y.sample(5)
ד. סטנדרטיזציה של הנתונים
מחשבים מתקשים ללמוד מתוך נתונים המתאפיינים בשונות גבוהה בין העמודות. כפי שראינו, עמודות שונות במסד הנתונים נמצאות בסדרי גודל שונים שנעים בין גדלים שהם פחות מ-1 עבור הכלורידים ועד למאות עבור הסולפטים. נערוך סטנדרטיזציה באמצעות zscore כדי שכל הדוגמאות יהיו באותו סדר גודל.
x_standard = x.apply(zscore)x_standard.describe()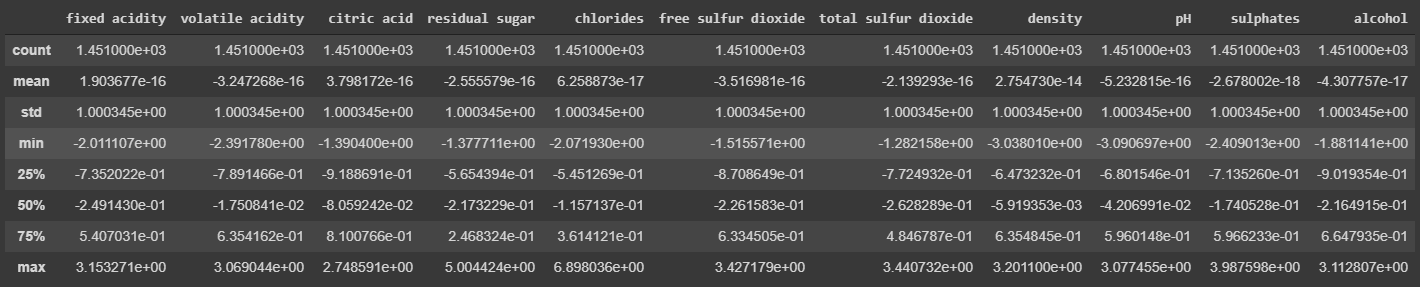
ד. הפרדה לקבוצות: אימון, בקרה ומבחן
נחלק את הנתונים ל-3 קבוצות:
- קבוצת אימון (train) ממנה המודל ילמד לסווג את הדוגמאות.
- קבוצת בקרה (validation) שהמודל יחזה (predict) את הדוגמאות שבה במהלך הלמידה ועל סמך ההפרש בין התחזיות לבין הערך בפועל יעדכן את המשקלים והמשקולות (weights and biases).
- קבוצת מבחן (test) היא קבוצה של דוגמאות שהמודל לא ייחשף אליהם בזמן האימון והם יאפשרו לנו להעריך את ביצועי המודל על דוגמאות ב-"עולם האמיתי".
from sklearn.model_selection import train_test_splitx_train, x_test, y_train, y_test = train_test_split(x_standard, y, test_size=0.3, random_state=1)
x_test, x_val, y_test, y_val = train_test_split(x_test, y_test, test_size=0.7, random_state=1)השתמשתי פעמיים במתודה train_test_split כיוון שהיא מסוגלת להפריד לשתי קבוצות אבל דרושות לי שלוש.
7. בניית המודל
את הרשת הנוירונית בניתי בעזרת keras.
לבניית הרשת הנוירונית בעלת יכולת הסיווג הבינארית השתמשתי בשני כללים עקרוניים:
- שכבת קלט מסוג Dense שבה 11 יחידות קלט כמספר עמודות הפיצ'רים המהווים את ציר ה-x.
- שכבת פלט המיועדת לפלוט תוצאות בינאריות (1 או 0). הכוללת, בהתאם, נוירון בודד ופונקצית אקטיבציה סיגמואידית.
מעבר לשני הכללים לעיל הוספתי היפר-פרמטרים ומבנים שבחינה מקדימה הראתה שהם גרמו לעלייה בשיעור הדיוק של המודל:
- שכבה חבויה בין שכבת הקלט והפלט במטרה להגדיל את יכולת הלמידה.
- Dropout, BatchNormalization ורגולריזציה באמצעות פונקצית l2 להקטנת ה-overfitting במטרה לצמצם את ה-overfitting.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization
from tensorflow.keras.regularizers import l2def baseline_model(units1, units2, dropout):
model = Sequential()
model.add(Dense(units1, input_shape=(11,), activation='relu'))
model.add(Dropout(dropout))
model.add(BatchNormalization(axis=1))
model.add(Dense(units2, activation='relu', activity_regularizer=l2(0.01), kernel_regularizer=l2(0.01)))
model.add(Dropout(dropout))
model.add(BatchNormalization(axis=1))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()
return modelלצורך קומפילציה של המודל הבינארי השתמשתי בפונקציית loss מסוג binary_crossentropy.
הגבלתי באמצעות פונקציית EarlyStopping את מספר הפעמים שהרשת הנוירונית רצה:
from keras.callbacks import EarlyStoppinges = EarlyStopping(monitor='val_loss', min_delta=0.001, patience=5, verbose=1, mode='auto')
8. מודל למידת מכונה מבוסס TensorFlow
בניתי את המודל עם היפר-פרמטרים שאותם קבעתי על סמך ניסוי מקדים שערכתי בתהליך המוסבר במדריך בחירת המודל המשמש ללמידת מכונה:
units1 = 128
units2 = 128
dropout = 0.25
model = baseline_model(units1, units2, dropout)נסקור את מבנה המודל:
tf.keras.utils.plot_model(model)
נריץ את המודל:
# Fit the model
history = model.fit(x_train, y_train,
batch_size=32,
epochs=100,
validation_data=(x_val,y_val),
callbacks=[es])דיאגרמה המתארת את השתנות מידת הדיוק (accuracy) וה-loss כפונקציה של מספר ההרצות (epochs) מלמדת שהמודל לא סובל מבעית overfitting:
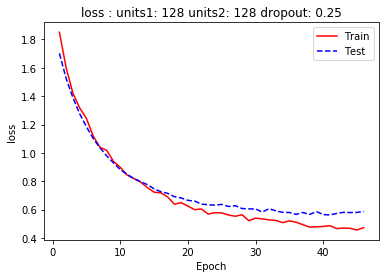
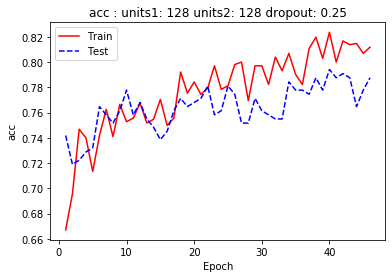
9. הערכת המודל
השוויתי את מידת הדיוק של המודל עבור 3 הקבוצות.
קבוצת האימון:
loss, acc = model.evaluate(x_train, y_train)loss: 0.4230 - acc: 0.8345
קבוצת הבקרה:
loss, acc = model.evaluate(x_val, y_val)loss: 0.5802 - acc: 0.7516
קבוצת המבחן:
loss, acc = model.evaluate(x_test, y_test)loss: 0.6074 - acc: 0.7462
מידת הדיוק הגבוהה ביותר היא עבור דוגמאות האימון (83.45%) והנמוכה ביותר עבור דוגמאות המבחן (74.62%) שהמודל לא נחשף אליהם במהלך האימון.
sklearn מאפשר הבנה טובה יותר של יכולת הסיווג של המודל:
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report, f1_scorey_pred = model.predict(x_test)y_pred = np.array([0 if n <= .5 else 1 for n in y_pred])print(confusion_matrix(y_test, y_pred))[[38 22] [11 59]]
acc = accuracy_score(y_test, y_pred)
print('The accuracy is: %.2f' % acc)The accuracy is: 0.75
print(classification_report(y_test, y_pred, target_names=labels)) precision recall f1-score support
bad 0.78 0.63 0.70 60
good 0.73 0.84 0.78 70
accuracy 0.75 130
macro avg 0.75 0.74 0.74 130
weighted avg 0.75 0.75 0.74 130
print(f1_score(y_test, y_pred))0.7814569536423841
יש הבדל קטן ביכולת הסיווג של המודל בין דוגמאות של יינות משובחים (דיוק 0.78) לעומת כאלה שאינם (דיוק 0.73). ערך מדד f1 האמין יותר מבחינה סטטיסטית הוא 0.78 – תוצאה גבוהה המראה שהמודל מסוגל לסווג בהצלחה רבה דוגמאות אליהם הוא לא נחשף.
10. סיכום
המודל בניסוי הצליח להגיע ל-78% דיוק בזיהוי טיב דוגמאות היין. ניתן לשפר את המודל באמצעות תוספת דוגמאות ובתנאי שיהיו מגוונות יותר.
כדי להעריך את המודל שפתחתי במדריך כנגד מודלים ידועים, המשכתי את הניסוי עם מודלים של sklearn. האלגורימים SVC ו-RandomForest נתנו דיוק של 74% עם ערך f1 של 0.76. ערכים מעט נמוכים יותר מהמודל במדריך.
לכל המדריכים בסדרה על לימוד מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.