
כיצד לשלב בין pandas ל-SQL?
ספריית Pandas של פייתון הכרחית לניתוח ומניפולציה של נתונים בתחום של למידת מכונה. רבים מהעוסקים בתחום באים מרקע של עבודה מול מסדי נתונים מבוססי SQL בשבילם היכולת להשתמש ב-Pandas באמצעות תחביר SQL היא משמעותית. ספריית pandasql מחברת בין DataFrames של Pandas למסד נתונים SQLite. במדריך זה מספר דוגמאות לשאילתות שניתן לבצע באמצעות pandasql.

נייבא את הספריות הדרושות ללמידת מכונה:
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltהתקנתי את pandasql באמצעות מנהל החבילות pip.
נייבא את החבילה:
from pandasql import sqldfאת הנתונים במדריך הורדתי מאתר הבנק העולמי ויש בהם נתוני אוכלוסייה ותל"ג של 7 מדינות (ביניהן ישראל) בשנים 2015 ל-2020.
הורדתי את הנתונים בשני קבצי CSV (מצורף). נטען את הנתונים כ-DataFrame של Pandas:
gdp_df = pd.read_csv("./data/gdp.csv")
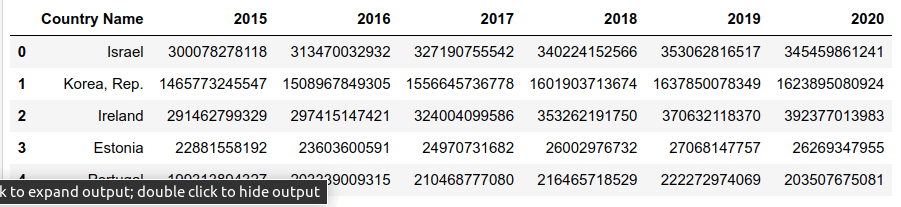
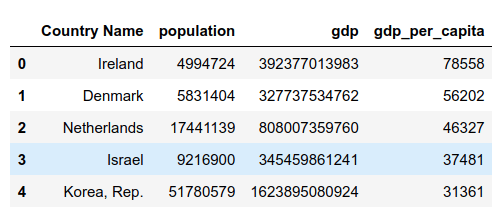
pop_df = pd.read_csv("./data/population.csv")התל"ג:
gdp_df.head()
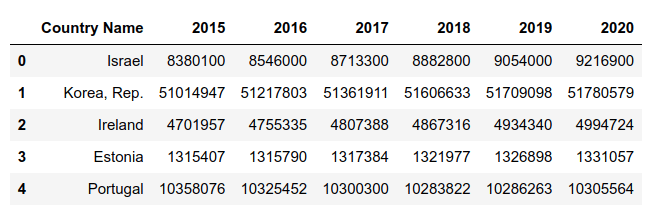
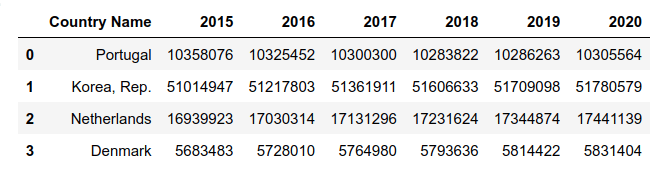
נתוני האוכלוסייה:
pop_df.head()
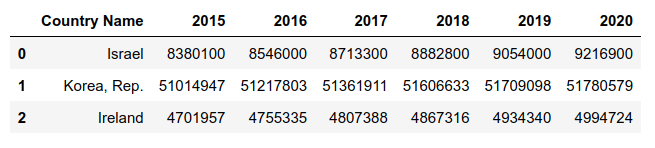
נריץ שאילתה פשוטה על נתוני האוכלוסייה:
q = """
SELECT
*
FROM
pop_df
LIMIT 3;"""
sqldf(q)
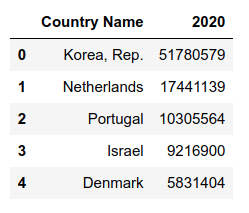
נוסיף תנאי:
q = """
SELECT
`Country Name`,
`2020`
FROM
pop_df
WHERE
`2020` >= 4994724
ORDER BY `2020` DESC
LIMIT 5;
"""
sqldf(q)
אנחנו יכולים לסדר את הנתונים באמצעות ORDER BY:
q = """SELECT
*
FROM
pop_df
ORDER BY RANDOM()
LIMIT 4;"""
sqldf(q)

ניתן להשתמש בפונקצית אגרגציה:
q = """
SELECT `Country Name`, MAX(`2020`)
FROM pop_df;
"""
sqldf(q)
אין בעיה להריץ תת שאילתות:
q = """
SELECT
`p`.`Country Name`,
`p`.`2020` AS `population`,
AVG(`p`.`2020`)
FROM
pop_df AS p
WHERE
`p`.`2020` >= (SELECT AVG(`2020`) FROM pop_df)
"""
sqldf(q)
אפשר לצרף טבלאות באמצעות JOIN:
q = """
SELECT
`g`.`Country Name`,
`p`.`2020` AS `population`,
`g`.`2020` AS `gdp`,
CAST(`g`.`2020` AS DECIMAL)/CAST(`p`.`2020` AS DECIMAL) AS `gdp_per_capita`
FROM
pop_df AS p
INNER JOIN
gdp_df AS g
on `g`.`Country Name` = `p`.`Country Name`
ORDER BY
`gdp_per_capita` DESC;
"""
joined = sqldf(q)
joined.head(5)

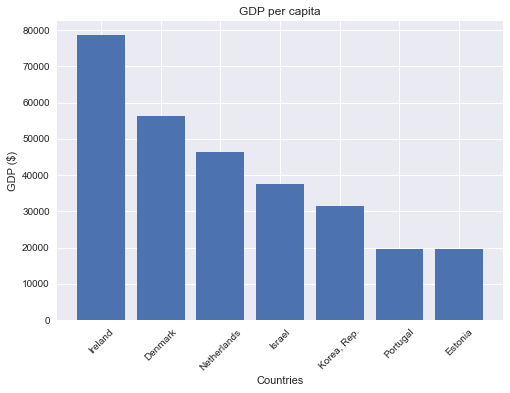
נעזר ב-matplotlib על מנת לצייר גרף:
q = """
SELECT
`g`.`Country Name`,
`p`.`2020` AS `population`,
`g`.`2020` AS `gdp`,
CAST(`g`.`2020` AS DECIMAL)/CAST(`p`.`2020` AS DECIMAL) AS `gdp_per_capita`
FROM
pop_df AS p
INNER JOIN
gdp_df AS g
on `g`.`Country Name` = `p`.`Country Name`
ORDER BY
`gdp_per_capita` DESC;
"""
df = sqldf(q)
plt.title("GDP per capita")
plt.xlabel("Countries")
plt.ylabel("GDP ($)")
xpos = np.arange(len(df["Country Name"]))
plt.xticks(xpos, df["Country Name"])
plt.xticks(rotation = 45)
plt.bar(xpos, df["gdp_per_capita"])
מגבלות
pandasql לא מאפשרת לעדכן או להוסיף נתונים למסד הנתונים.
לקריאה נוספת
18 פעולות שאתה צריך להכיר כשאתה עובד עם Pandas של Python
12 דברים שאתה חייב לדעת כשאתה מייצר תרשימים באמצעות matplotlib של python
מודלים ללמידת מכונה של SciKit-Learn
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.