
מודל לחיזוי השרדות נוסעים על סיפון הטיטניק באמצעות למידת מכונה אוטומטית ו-AutoKeras
הספינה טיטאניק שקעה במצולות הים בשעות הבוקר המוקדמות של 1912 למרות שהיא נחשבה לגדולה והמשוכללת מבין הספינות של התקופה. מ-2,224 נוסעי הספינה שרדו רק 724 מה שהופך את התאונה לאחד האסונות הימיים הגדולים בהיסטוריה. במדריך זה ננסה לחזות אילו נוסעים שרדו את האסון על סמך נתונים דוגמת נמל המוצא, מין הנוסע וגילו. את החיזוי נעשה באמצעות ספריית AutoKeras שתמצא באופן אוטומטי את המודל הטוב ביותר של Keras, ממשק הלמידה העמוקה של גוגל.

AutoKeras היא ספריה שעושה אוטומציה של למידת מכונה המאפשרת למחשב לבחור בשבילנו את המודלים המתאימים ביותר לביצוע המשימה שמעניינת אותנו. במדריך קודם ראינו למידת מכונה אוטומטית באמצעות auto-sklearn ספרייה שמוצאת את הרכב האלגוריתמים המוצלח ביותר מתוך המבחר שמציעה ספריית sklearn. במדריך זה נשתמש בAutoKeras שמוצא את המודל הטוב ביותר של Keras.
סביבת העבודה
את המדריך פתחתי על סביבת Colab שמציעה לכל מי שרשום לגוגל סביבת עבודה חינמית ללמידת מכונה על השרתים של ענקית הטכנולוגיה.
את המחברת המלאה שנפתח במדריך בשלבים ניתן להוריד מכאן.
את ספריית AutoKeras התקנתי באמצעות פקודות שלקחתי מהתיעוד הרשמי של הספרייה:
!pip install autokeras
!pip install git+https://github.com/keras-team/[email protected]ייבאתי את TensorFlow ואת AutoKeras כיוון שהגרסה האחרונה של TensorFlow משתמשת כברירת מחדל בממשק Keras:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.python.keras.utils.data_utils import Sequence
import autokeras as akייבאתי ספריות נוספות:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')- numpy ,pandas - בשביל החישובים
- matplotlib ,seaborn - בשביל התרשימים
מסד הנתונים
את מסד הנתונים titanic הורדתי מ-Kaggle, אתר התחרויות בתחום data science , בשיטה המתוארת במדריך על סיווג תמונות באמצעות מודל מאומן.
אחזור על התהליך בקצרה:
- נרשמתי לאתר Kaggle.
- בדף התחרות הרשמי Titanic: Machine Learning from Disaster הסכמתי לתנאי התחרות, ומשם העתקתי את הפקודה להורדת מסד הנתונים.
- נכנסתי לחשבון שלי כדי להוריד אסימון API token בפורמט json. את האסימון העליתי לתיקיית העבודה בסביבת colab.
- על פי הנחיות Kaggle יצרתי בתוך התיקייה, תיקייה נוספת אליה העברתי את קובץ ה-json.
# file configuration
!mkdir -p ~/.kaggle/
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.jsonהורדתי את מסד הנתונים באמצעות הפקודה הבאה:
!kaggle competitions download -c titanic-datasetנצפה במסד הנתונים לאחר שנייבא אותו:
# import the dataset
df = pd.read_csv('titanic_train.csv')
df.shape(850, 15)
- במסד הנתונים 850 רשומות המתחלקות בין 15 עמודות.
- כל רשומה מכילה פרטים אודות אחד הנוסעים. כולל האם שרד את האסון.
# show the dataset
df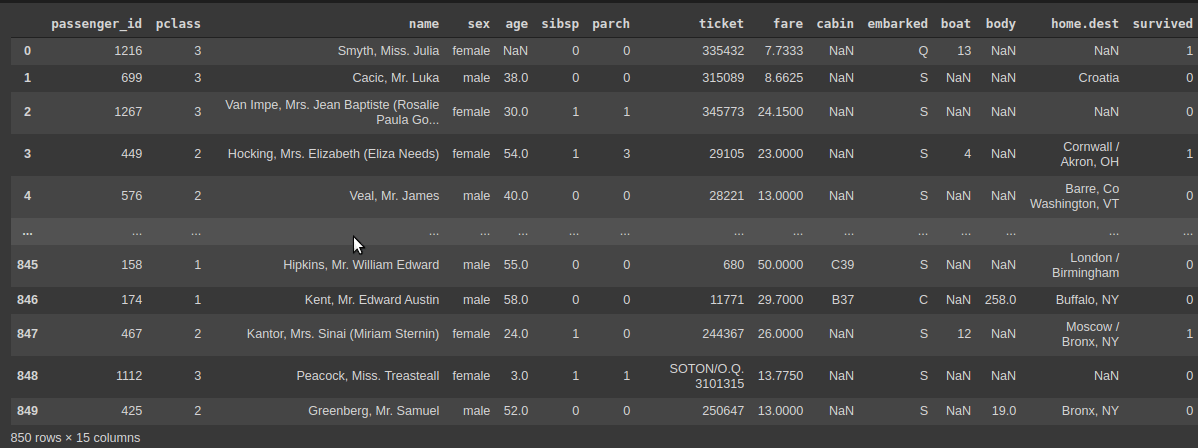
- pclass - מעמד סוציו אקונומי (1=גבוה, 2=בינוני, 3=נמוך)
- name - שם הנוסע
- sex - מין הנוסע
- age - גיל
- sibsp - מספר אחים של הנוסע
- parch - האם נסע בליווי הורה
- fare - מחיר כרטיס
- embarked - הנמל ממנו עלה הנוסע לאונייה (C = Cherbourg; Q = Queenstown; S = Southampton)
- survived - האם הנוסע שרד
עד כמה המידע שלם?
# describe the columns
df.info()RangeIndex: 850 entries, 0 to 849 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 passenger_id 850 non-null int64 1 pclass 850 non-null int64 2 name 850 non-null object 3 sex 850 non-null object 4 age 676 non-null float64 5 sibsp 850 non-null int64 6 parch 850 non-null int64 7 ticket 850 non-null object 8 fare 849 non-null float64 9 cabin 191 non-null object 10 embarked 849 non-null object 11 boat 308 non-null object 12 body 73 non-null float64 13 home.dest 464 non-null object 14 survived 850 non-null int64 dtypes: float64(3), int64(5), object(7) memory usage: 99.7+ KB
- חסרים נתונים. בפרט אודות הגיל, תא הנוסעים, וסירות ההצלה. אחד ההסברים הוא שלא היו סירות הצלה לכולם.
כמה נוסעים שרדו?
# how many survived
df.survived.value_counts()0 537 1 313 Name: survived, dtype: int64
- 331 נוסעים שרדו ו-537 נספו. סט הנתונים לא מאוזן.
כמה זכרים ונקבות?
# how many of each sex
df.sex.value_counts()male 551 female 299 Name: sex, dtype: int64
- שיעור גבוה יותר של זכרים.
מהי התפלגות הגילאים?
sns.displot(df.age, binwidth=10)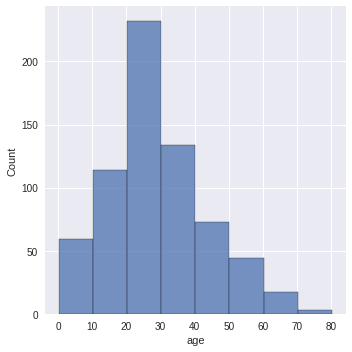
- התפלגות נורמלית עם שיעור גבוה של נוסעים בשנות ה-30 וה-40 לחייהם.
מהי התפלגות מחירי כרטיסי הנסיעה?
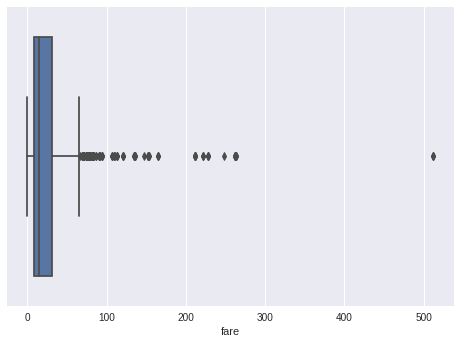
- התפלגות מחירי הכרטיסים מראה ריבוי של נתונים קיצוניים. צריך להתחשב בכך בבניית המודל.
ננסה למצוא מתאם (קורלציה) בין נתונים מספריים המשכיים (מחיר, גיל) והישרדות:
# survival rate vs continuous data
df[['fare','age','survived']].corr()| fare | age | survived | |
|---|---|---|---|
| fare | 1.000000 | 0.194609 | 0.251249 |
| age | 0.194609 | 1.000000 | -0.042683 |
| survived | 0.251249 | -0.042683 | 1.000000 |
- יש מתאם חיובי חלש 0.25 בין מחיר כרטיס והישרדות. אבל נראה שלגיל אין השפעה (אולי מפני שחסרים נתונים).
ננסה לתאר את הקשרים בין נתונים קטגוריים (גיל, נמל, מעמד סוציו אקונומי) והישרדות נוסעים:
# survival rate vs categorical data
cols = ['sex', 'embarked', 'pclass', 'parch']
n_rows = 2
n_cols = 2
fig, axs = plt.subplots(n_rows, n_cols, squeeze=False)
for r in range(0,n_rows):
for c in range(0,n_cols):
i = r*n_cols+ c
ax = axs[r][c]
sns.countplot(df[cols[i]], hue=df["survived"], ax=ax)
ax.set_title(cols[i])
ax.legend(title="survived") 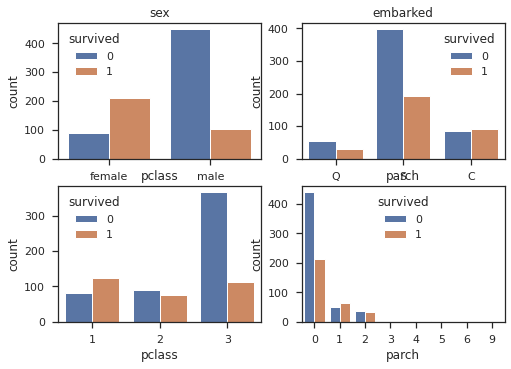
- רוב הנשים שרדו בעוד רוב הגברים טבעו.
- שיעור הנספים בין המצטרפים בנמל שרבורג (Cherbourg) גבוה יותר מאשר בשני הנמלים האחרים.
- שיעור השורדים מבין נוסעי המחלקה הראשונה הוא הגבוה ביותר. רוב נוסעי המחלקה השלישית נספו.
הכנת מסד הנתונים ללמידת מכונה
נכין את מסד הנתונים ללמידת מכונה בתוך הפונקציה preprocess:
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
def preprocess(df):
# remove columns with lots of missing values
df = df.drop(['cabin', 'boat', 'body','home.dest'], axis=1)
# set the index
df.set_index('passenger_id', inplace=True)
# remove non relevant columns
df_clean = df.drop(['name','ticket'], axis=1)
# handle missing age values
med = df_clean.age.median()
df_clean.age = df_clean.age.fillna(med)
# drop rows with missing values
df_clean = df_clean.dropna(axis=0)
# sex and embarked are categorical - let's make them numerical
df_clean.loc[:,'sex'] = label_encoder.fit_transform(df_clean.loc[:,'sex'])
df_clean.loc[:,'embarked'] = label_encoder.fit_transform(df_clean.loc[:,'embarked'])
return df_clean- נסיר עמודות עם נתונים חסרים.
- נסיר עמודות שמייצרות רעש כי הנתונים בהם יחידאים (שם הנוסע והכרטיס).
- נשלים את נתוני הגיל החסרים באמצעות החציון כי בניגוד לממוצע הוא פחות מושפע מדוגמאות חריגות.
- נסיר רשומות עם נתונים חסרים.
- נהפוך נתונים קטגוריים (מין ונמל מוצא) למספריים באמצעות LabelEncoder.
התוצאה של הפעלת הפונקציה preprocess על מסד הנתונים היא מסד נתונים נקי יותר:
df_clean = preprocess(df)נפריד את מסד הנתונים לעמודות תלויות (y) ובלתי תלויות (x):
# separate into dependent and independent variables
y = df_clean.pop('survived')
x = df_cleanכך נראות עמודות x הבלתי תלויות מהם נחזה את עמודת ההישרדות:
| pclass | sex | age | sibsp | parch | fare | embarked | |
|---|---|---|---|---|---|---|---|
| passenger_id | |||||||
| 1216 | 3 | 0 | 28.0 | 0 | 0 | 7.7333 | 1 |
| 699 | 3 | 1 | 38.0 | 0 | 0 | 8.6625 | 2 |
| 1267 | 3 | 0 | 30.0 | 1 | 1 | 24.1500 | 2 |
| 449 | 2 | 0 | 54.0 | 1 | 3 | 23.0000 | 2 |
| 576 | 2 | 1 | 40.0 | 0 | 0 | 13.0000 | 2 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 158 | 1 | 1 | 55.0 | 0 | 0 | 50.0000 | 2 |
| 174 | 1 | 1 | 58.0 | 0 | 0 | 29.7000 | 0 |
| 467 | 2 | 0 | 24.0 | 1 | 0 | 26.0000 | 2 |
| 1112 | 3 | 0 | 3.0 | 1 | 1 | 13.7750 | 2 |
| 425 | 2 | 1 | 52.0 | 0 | 0 | 13.0000 | 2 |
וכך נראית העמודה התלויה y - עמודת ההישרדות:
passenger_id
1216 1
699 0
1267 0
449 1
576 0
..
158 0
174 0
467 1
1112 0
425 0
Name: survived, Length: 848, dtype: int64
נפצל את הנתונים לסט אימון (train) ממנו ילמד AutoKeras את המודל הטוב ביותר וסט בקרה (test) שנשמור בצד כדי שנוכל בהמשך להעריך את יכולות המודל:
# split into train and test datasets
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size=0.1,
random_state=17)סטנדרטיזציה (תיקנון) משמעותה מרכוז והאחדת סטיית התקן עבור כל אחת מעמודות מסד הנתונים.
התיקנון כולל:
- מרכוז (centering) - הופך את הממוצע לאפס.
- האחדת סטיית התקן (scaling) - גורמת לסטיית התקן להיות שווה ל-1.
תיקנון מאפשר לעמודות להיות באותו סולם. במקרה שלנו תיקנון יכול לעזור כיוון שהעמודות השונות נמדדות בסדרי גודל שונים. לדוגמה, הגיל נמדד בעשרות (שנים) ומחירי הכרטיסים במאות (פאונדים), ואם לא נתקנן קיימת סכנה שעמודות מסדרי גודל גבוהים יהוו השפעת יתר על המודל.
את התיקנון תעשה בשבילנו הפונקציה StandardScaler:
# feature scaling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
x_train = scaler.fit_transform( x_train )
x_test = scaler.transform( x_test )
מציאת המודל המוצלח ביותר באמצעות AutoKeras
AutoKeras ימצא את המודל הטוב מתוך סידרה של מודלים שהוא מייצר על בסיס האלגוריתמים בהם הוא מצויד. נאתחל את AutoKeras על ידי כך שנעביר לפונקציה את מספר המודלים שהוא צריך לנסות (15). כל מודל ירוץ מספר מחזורי אימון (10) שבסופם יבחר המודל הטוב ביותר:
# initialize the structured data classifier with 15 different models
clf = ak.StructuredDataClassifier(max_trials=15)
# find the best model
clf.fit(x=x_train, y=y_train, epochs=10)בתום הריצה נציג את המודל ש-AutoKeras מחשיב לטוב ביותר:
# get the best performing model
model = clf.export_model()
# summarize the model
model.summary()_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 7)] 0 _________________________________________________________________ multi_category_encoding (Mul (None, 7) 0 _________________________________________________________________ normalization (Normalization (None, 7) 15 _________________________________________________________________ dense (Dense) (None, 32) 256 _________________________________________________________________ batch_normalization (BatchNo (None, 32) 128 _________________________________________________________________ re_lu (ReLU) (None, 32) 0 _________________________________________________________________ dense_1 (Dense) (None, 1024) 33792 _________________________________________________________________ batch_normalization_1 (Batch (None, 1024) 4096 _________________________________________________________________ re_lu_1 (ReLU) (None, 1024) 0 _________________________________________________________________ dense_2 (Dense) (None, 1) 1025 _________________________________________________________________ classification_head_1 (Activ (None, 1) 0 ================================================================= Total params: 39,312 Trainable params: 37,185 Non-trainable params: 2,127 _________________________________________________________________
מה האופטימייזר?
model.optimizerautokeras.graph.AdamWeightDecay at 0x7f7782545358
נעריך את ביצועי המודל
נעריך את מידת דיוק המודל הטוב ביותר שמצא AutoKeras על דוגמאות האימון:
# predict with the best model
loss, acc = clf.evaluate(x_train, y_train)
print(f'train loss: %.3f' % round(loss, 3))
print(f'train accuracy: %.3f' % round(acc, 3))train loss: 0.475 train accuracy: 0.836
ומה בנוגע לדוגמאות הביקורת ששמרנו בצד:
# evaluate the model performance on the testing dataset
loss, acc = clf.evaluate(x_test, y_test)
print(f'test loss: %.3f' % round(loss, 3))
print(f'test accuracy: %.3f' % round(acc, 3))test loss: 0.482 test accuracy: 0.824
מידת הדיוק דומה בין דוגמאות הניסוי והביקורת ועומדת על 83% ו-82% בהתאמה.
נעזר ב-confusion matrix כדי למצוא באיזו קטגוריה המודל נוטה לדייק יותר.
# use confusion matrix to see the which
# category did the model get wrong
predictions = clf.predict(x_test)ההסתברויות נעות על כל הטווח שבין 0 ל-1. נשתמש בתרגיל הבא כדי לגרום לחיזויים נמוכים או שווים ל-0.5 להיות 0 בעוד כל היתר יקבלו את הערך 1.
y_pred = np.array([0 if n <= .5 else 1 for n in predictions])נעריך באמצעות confusion matrix:
from sklearn.metrics import confusion_matrix
cf_matrix = confusion_matrix(y_test, y_pred)
print(cf_matrix)[[43 3] [12 27]]
- המודל חזה נכונה 43 מתוך 46 הנספים בסט הביקורת, ו- 27 מתוך 39 השורדים.
- נראה שהמודל נוטה לשגות יותר בסיווג השורדים. ייתכן שבגלל שיעורם הנמוך באוכלוסיה.
כיוון שמספר הנספים גדול יותר ממספר השורדים סט הנתונים לא מאוזן ולפיכך כדאי להשתמש במדד f1 כדי להעריך את מידת הדיוק של המודל:
# accuracy score is not enough to evaluate the
# model especially since the dataset is imbalanced
from sklearn.metrics import classification_report, f1_score
print(classification_report(y_test, y_pred)) precision recall f1-score support
0 0.78 0.93 0.85 46
1 0.90 0.69 0.78 39
accuracy 0.82 85
macro avg 0.84 0.81 0.82 85
weighted avg 0.84 0.82 0.82 85
# overall f1 score
f1_score(y_test, y_pred)0.7826086956521738
ערך f1 של 0.78
נייצא את המודל
קיבלנו את המודל הטוב ביותר. עכשיו הזמן לייצא אותו למודל TensorFlow לשימוש בעתיד:
# export as tf model
model.save("titanic_survivor_classifier", save_format="tf")
סיכום
במדריך זה ראינו הדגמה של יכולות הספרייה AutoKeras שבוחרת באופן אוטומטי את המודל הטוב ביותר של Keras לביצוע משימה של למידת מכונה. המשימה שביצענו היא מסוג סיווג מידע טבלאי אבל הספרייה מסוגלת גם לסווג תמונות וטקסט ולבצע משימות של רגרסיה. מומלץ בחום לקרוא את התיעוד המעולה באתר AutoKeras כדי ללמוד עוד אודות הספרייה המרתקת והמבטיחה הזו.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.