
מה הגורמים החשובים ביותר המנבאים הכנסה גבוהה?
במדריך זה ננסה למצוא את הגורמים האינדיקטיביים ביותר להכנסה גבוהה. לשם כך, נשתמש בנתוני סקר שנאסף בארה"ב בשנת 1994 שסקר גורמים שונים, דוגמת השכלה, מין וארץ מוצא, וסיווג את הדוגמאות על פי הכנסה גבוהה או נמוכה מ-50,000$. במדריך נאמן מודל XGBoost בסיווג דוגמאות על פי רמת הכנסה, וננתח את הנתונים באמצעות SHAP שימצא קשרים בין רמת ההכנסה לבין הגורמים בסקר.
את מסד הנתונים Census Income Dataset הורדתי מ-UCI Machine Learning Repo.
מטרת המודל היא להבחין בין אנשים שהכנסתם גבוהה או נמוכה מ-50K לשנה.
ייבוא הספריות
הספריות הבסיסיות:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
ייבוא מסד הנתונים
נייבא את מסד הנתונים ל-dataframe של Pandas:
# https://archive.ics.uci.edu/ml/datasets/adult
df = pd.read_csv('data/census.csv', header=None, na_values='?')
df.columns = ['id','workclass','fnlwgt','education','education-num','martial-status','occupation','relationship','race','sex','capital-gain','capital-loss','hours-per-week','native-country','income-class']
סקירת מסד הנתונים
כמה עמודות ושורות?
# How many rows and columns
df.shape(32561, 15)
df.head(5)מה העמודות, מה סוג הנתונים, האם חסרים נתונים?
df.info()
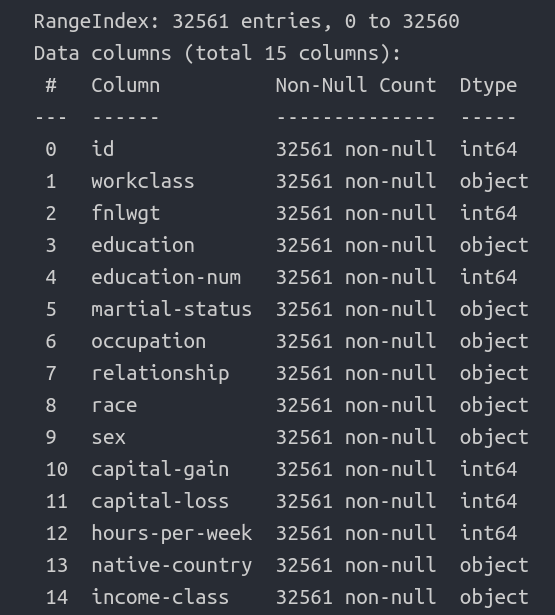
- תערובת של נתונים מספריים ושמיים \ קטגוריים.
- לכאורה, לא חסרים נתונים.
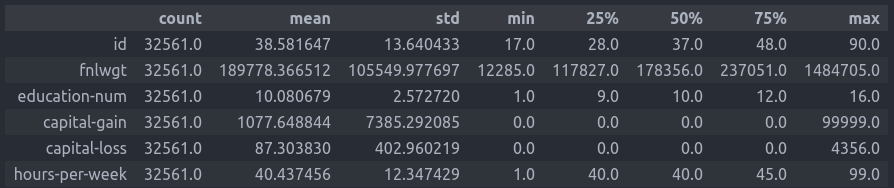
נתאר את העמודות המספריות באמצעות מדדי מרכז:
df.describe().T
נציץ בהתפלגות אחת העמודות הקטגוריות:
df.occupation.value_counts()Prof-specialty 4140 Craft-repair 4099 Exec-managerial 4066 Adm-clerical 3770 Sales 3650 Other-service 3295 Machine-op-inspct 2002 ? 1843 Transport-moving 1597 Handlers-cleaners 1370 Farming-fishing 994 Tech-support 928 Protective-serv 649 Priv-house-serv 149 Armed-Forces 9
- 1843 רשומות מצוינות באמצעות "?" כי זו הדרך שבה בחרו עורכי הסקר לציין את הנתונים החסרים.
מטרת המודל היא להבחין בין אנשים שהכנסתם גבוהה או נמוכה מ-50K לשנה. מה התפלגות רמות השכר?
df['income-class'].value_counts(normalize=True)- יש חוסר איזון בעמודת המטרה עם יחס של 1:3 לטובת האנשים בעלי הכנסה נמוכה.
<=50K 0.75919 >50K 0.24081
הכנת הנתונים ללמידת מכונה
הפונקציה הבאה מכינה את הנתונים ללמידה באמצעות XGBoost:
# preprocess the dataset
def preprocess(df):
df_clean = df
# remove non relevant/redundant columns
df_clean.drop(["id"], axis=1, inplace=True)
# replace '?' with mode
cols = ["workclass", "occupation", "native-country"]
df_clean[cols] = df_clean[cols].replace(' ?', np.NaN)
df_clean[cols] = df_clean[cols].fillna(df_clean.mode().iloc[0])
# binary columns
df_clean["sex_bin"] = np.where(df_clean["sex"]==" Male", 0, 1)
df_clean["sex"] = df_clean["sex_bin"]
df_clean.drop(["sex_bin"], axis=1, inplace=True)
df_clean["income_bin"] = np.where(df_clean["income-class"]==" <=50K", 0, 1)
df_clean["income-class"] = df_clean["income_bin"]
df_clean.drop(["income_bin"], axis=1, inplace=True)
# reduce the number of categories
df_clean.education = df.education.replace([' Preschool', ' 1st-4th', ' 5th-6th', ' 7th-8th', ' 9th'], 'some school')
df_clean.education = df.education.replace([' 10th', ' 11th', ' 12th', ' 7th-8th', ' HS-grad'], 'highschool')
df_clean.education = df.education.replace([' Assoc-voc', ' Assoc-acdm', ' Some-college', ' Prof-school'], 'some higher education')
df_clean.education = df.education.replace([' Bachelors', ' Masters', ' Doctorate'], 'higher education')
# we have to one hot encode categorical columns before using XGBoost
categorical_columns = ['workclass', 'education', 'martial-status', 'native-country', 'race', 'occupation', 'relationship']
for cname in categorical_columns:
dummies = pd.get_dummies(df_clean[cname], prefix=cname)
df_clean = pd.concat([df_clean, dummies], axis=1)
df_clean.drop([cname], axis=1, inplace=True)
return df_cleandf_clean = preprocess(df)- הסרנו את העמודה id שלא מועילה לסיווג.
- החלפנו את "?", המציין חוסר במסד הנתונים, ב-mode, הערך הנפוץ ביותר, בעמודות השמיות.
- את העמודות שיש להם שני ערכים (מין ורמת הכנסה) הפכנו לבינאריות (0, 1). הקטגוריה השכיחה קבלה את הערך 0.
- הפחתנו את מספר הקטגוריות בעמודה education.
- קודדנו בשיטת one hot encoding את העמודות השמיות (שאינם בינאריות) כי זה מה שדורש XGBoost.
נפריד את הנתונים למשתנה הכנסה התלוי בכל יתר המשתנים:
y = df_clean.pop('income-class')
X = df_cleanנחלק את הנתונים בין סט אימון ומבחן תוך הקפדה על שמירת היחס בין המחלקות במשתנה התלוי:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
אימון המודל
את המודל נאמן באמצעות מסווג של XGBoost:
xgb_classifier = xgb.XGBClassifier(objective='binary:logistic', missing=1, seed=42)
xgb_classifier = xgb_classifier.fit(X_train,
y_train,
verbose=True,
early_stopping_rounds=10,
eval_metric='aucpr',
eval_set=[(X_test,y_test)])- המדד להתקדמות הלמידה הוא aucpr המבוסס על עקומת ROC-AUC.
- בסוף כל מחזור אימון התוצאות מושוות לסט המבחן.
הערכת ביצועי המודל
נעריך את ביצועי המודל על סט המבחן:
from sklearn.metrics import classification_report, f1_score
y_pred = xgb_classifier.predict(X_test)
print(classification_report(y_test, y_pred))
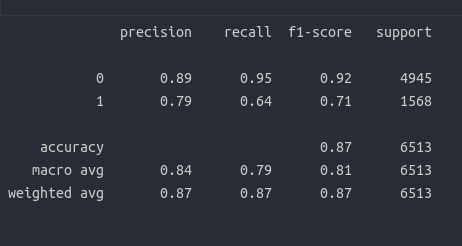
המודל מצליח יותר בזיהוי המחלקה השכיחה (<=50K) על פי ערך F1 של 0.92 לעומת 0.71 בלבד בזיהוי הדוגמאות בהם ההכנסה גבוהה מ-50K בהתאם להעדר האיזון של עמודת המטרה.
הבנת המודל
ננסה להבין את חשיבות העמודות לסיווג בעזרת פונקציה של XGBoost:
from xgboost import plot_importance
def get_feature_importance(model):
features_list_dict = model.get_booster().get_score(importance_type='weight')
features_list_array = np.array(list(features_list_dict.items()))
features_importance_df = pd.DataFrame(features_list_array, columns=['feature','importance'])
features_importance_df['importance'] = features_importance_df['importance'].astype("int")
features_importance_df_sorted = features_importance_df.sort_values("importance", ascending=False)
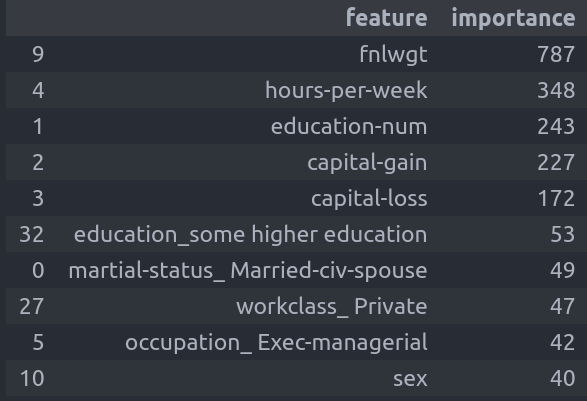
return features_importance_df_sortedמה 10 העמודות החשובות ביותר לסיווג?
get_feature_importance(xgb_classifier)[:10]
SHAP היא ספרייה מובילה בתחום הבנת מודלים של למידת מכונה (explainable ml). מעניין מה אפשר ללמוד ממנה על המודל.
import shap
shap.initjs()
explainer = shap.TreeExplainer(xgb_classifier)
shap_values = explainer.shap_values(X)נציג את סיכום השפעת העמודות על המודל:
shap.summary_plot(shap_values, X)
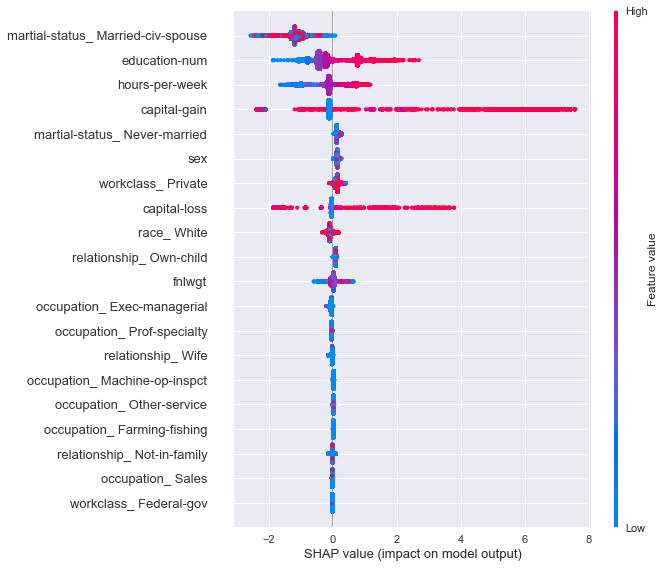
- הפיצ'רים בעלי ההשפעה הגבוהה ביותר הם נישואים, מספר שנות לימוד ומספר שעות בשבוע.
כיצד משפיעות עמודות ספציפיות על הסיווג?
for name in ['hours-per-week', 'education-num']:
shap.dependence_plot(name, shap_values, X, display_features=X)
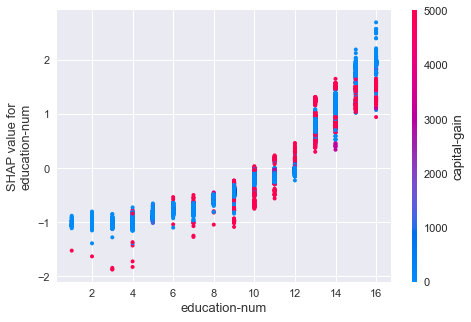
- ההכנסה עולה עם מספר שנות הלימוד.
- האינטראקציה העיקרית היא עם התכונה capital-gain, רווחי הון.
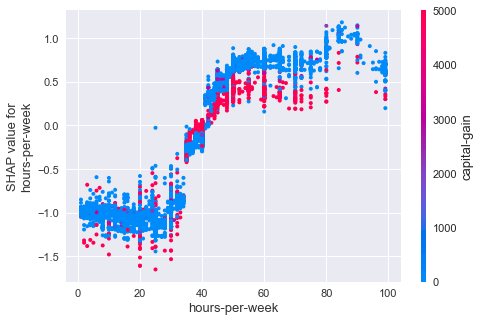
- ככל שמשקיעים יותר שעות בעבודה עולה ההכנסה עד 50 שעות שבועיות ומעבר לזה הגרף מתייצב.
- אנשים שנהנים מרווחי הון נוטים להרוויח פחות אולי בגלל שהם יכולים להרשות לעצמם לעבוד פחות או שהם עושים תכנון מס.
ניסיונות לשפר את המודל
ניסיתי שתי שיטות לשיפור המודל. שתיהן מנסות לפתור את הבעיה של סט נתונים לא מאוזן, ושתיהן לא הצליחו להציג תוצאות טובות יותר בכל הנוגע לערכי F1.
התוצאות מוצגות במחברת.
שימוש בפרמטר scale_post_weight של XGBoost
scale_pos_weight = 0.759175 / 0.240825
xgb_classifier_optimized = xgb.XGBClassifier(objective='binary:logistic',
missing=1,
seed=42,
scale_pos_weight=scale_pos_weight)
xgb_classifier_optimized = xgb_classifier_optimized.fit(X_train,
y_train,
verbose=True,
early_stopping_rounds=10,
eval_metric='aucpr',
eval_set=[(X_test,y_test)])השוואת מספר הדוגמאות השייכות לכל מחלקה באמצעות over_sampling
from imblearn.over_sampling import RandomOverSampler
def oversample(X_train, y_train):
oversample = RandomOverSampler(sampling_strategy='minority')
# Convert to numpy and oversample
x_np = X_train.to_numpy()
y_np = y_train.to_numpy()
x_np, y_np = oversample.fit_resample(x_np, y_np)
# Convert back to pandas
x_over = pd.DataFrame(x_np, columns=X_train.columns)
y_over = pd.Series(y_np, name=y_train.name)
return x_over, y_over
X_train_over, y_train_over = oversample(X_train, y_train)
xgb_classifier = xgb.XGBClassifier(objective='binary:logistic', missing=1, seed=42)
xgb_classifier_over = xgb_classifier.fit(X_train_over,
y_train_over,
verbose=True,
early_stopping_rounds=10,
eval_metric='aucpr',
eval_set=[(X_test,y_test)])לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.