
subclassing של שכבות ומודלים בספריית Keras
אחרי שעבדנו עם ה-API הסדרתי sequential של Keras שהוא הכי ידידותי וגם הכי פחות גמיש ועם ה-API הפונקציונלי שהוא פחות ידידותי ויותר גמיש, במדריך זה נלמד לעשות subclassing של שכבות ומודלים.
הדוגמה במדריך מבוססת על מדריך קודם זיהוי ספרות שכתב אדם על ידי בינה מלאכותית שם למדנו להשתמש ברשת נוירונית מבוססת קונבולוציה CNN, Convolutional Neural Network לעבודה עם תמונות. רשת CNN בנויה מאחד או יותר בלוקים של קונבולוציה שכל אחד מהם מורכב משכבה אחת או יותר של קונבולוציה שאחריה שכבת pooling. במדריך הסתפקנו בשתי שכבות בגלל שהמשימה היתה פשוטה: סיווג תמונות של ספרות קטנות (28X28 פיקסלים) שאנשים כתבו בכתב יד לאחת מ-10 קטגוריות (0 - 9). במציאות, יכולים להיות הרבה יותר קטגוריות וגם התמונות יכולות להיות גדולות הרבה יותר מה שדורש יותר בלוקים של קונבולוציה וגם ארכיטקטורה מורכבת. אפשר לחסוך חלק מהמורכבות אם מתייחסים לבלוק של הקונבולוציה בתור מודול ואז משלבים כמה מודולים כאלה בבניית הרשת הנוירונית. כדי לעשות זאת נשתמש ב-API ה-subclassing של Keras. וזו רק דוגמה לשימוש ב- subclassing לצורך בניית מודלים מורכבים של למידת מכונה.

למדריך זה שני חלקים. בחלק הראשון נלמד לעשות subclassing של שכבות. בשני subclassing של מודלים.
נייבא את הספריות הדרושות למדריך:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow import keras
from keras import layersנייבא את מסד הנתונים MNISTהכולל 70,000 תמונות של ספרות שכתבו אנשים שעברו סטנדרטיזציה לגודל של 28 על 28 פיקסלים בצבעים אפורים. 60,000 תמונות ישמשו לאימון והיתר למבחן:
from keras.datasets import mnist
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()את התמונות נעצב מחדש לתמונות שגודלם 28X28 פיקסלים עם ערוץ צבע 1. את התוצאה נחלק ב-225 כדי לנרמל:
# reshape to be [samples][pixels][width][height][channels_number]
# float32 is the data type that keras expects
img_width=28
img_height=28
X_train = X_train.reshape(X_train.shape[0], img_width, img_height, 1).astype('float32')
X_test = X_test.reshape(X_test.shape[0], img_width, img_height, 1).astype('float32')
# normalize inputs from 0-255 to 0-1
X_train = X_train / 255
X_test = X_test / 255את ערכי ה-y נקודד בשיטת one hot encode:
# one hot encode outputs
from keras.utils.np_utils import to_categorical
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
Subclassing של layers
ספריית Keras מצוידת במגוון של שכבות layers דוגמת: Dense ו-Conv2D, שנכתבו על ידי מיטב המומחים בתחום ועונים על מגוון רחב של צרכים בתחום למידת המכונה אבל כשרוצים שכבה שלא קיימת בספרייה פונים ל-subclassing.
רשת CNN בנויה מאחד או יותר בלוקים של קונבולוציה שכל אחד מהם מורכב משכבה אחת או יותר של קונבולוציה שאחריה שכבת pooling כשבסוף אפשר להוסיף שכבת dropout. במדריך השתמשנו בשני בלוקים של קונבולוציה כי המשימה פשוטה. במודלים מתוחכמים אנחנו יכולים למצוא 5 בלוקים של קונבולוציה (לדוגמה, VGG16), ואף יותר. במקום לכתוב את הבלוקים כל אחד בנפרד אנחנו יכולים ליצור subclass של layer שהוא בלוק קונבולוציה ואח"כ להשתמש בו כמה שצריך.
כדי להדגים subclassing של layers ניצור שכבה layer שתהיה בלוק קונבולוציה המורכב מ-3 שכבות:
- Conv2D
- Pooling
- Dropout
שכבה שיוצרים באמצעות subclassing מיישמת את keras.layers.Layer והיא כוללת שתי מתודות הכרחיות: __init__() ו-call():
class ConvBlock(keras.layers.Layer):
def __init__(self):
super().__init__()
pass
def call(self, input_tensor):
passההסבר המדויק ביותר הוא שהמתודה __init__() מחזיקה את המשקלות, בעוד המתודה call() מבצעת את החישובים forward pass.
נכתוב את זה:
class ConvBlock(keras.layers.Layer):
def __init__(self, out_channels, kernel_size=3):
super().__init__()
self.conv = layers.Conv2D(out_channels, kernel_size, activation="relu", padding="same")
self.max_pooling = layers.MaxPooling2D(pool_size=(2, 2))
self.dropout = layers.Dropout(0.2)
def call(self, input_tensor):
x = self.conv(input_tensor)
x = self.max_pooling(x)
x = self.dropout(x)
return x- במתודה __init__() הגדרנו את השכבות: Conv2D, MaxPooling2D ,Dropout.
- באמצעות המתודה call() נעביר את הטנסורים דרך forward pass העובר מחישוב לחישוב (אצלנו משכבה לשכבה) על פי הסדר הרצוי, כאשר בסוף המתודה מחזירה את הטנסור המתקבל בתהליך החישוב.
עכשיו שיש לנו שכבה שהיא מודול אנחנו יכולים להשתמש בה איך שנרצה. לדוגמה, לבניית מודל במסגרת API מסוג Sequential:
model = keras.Sequential(
[
ConvBlock(32),
ConvBlock(64),
layers.Flatten(),
layers.Dense(128, activation="relu"),
layers.Dense(10, activation="softmax")
]
)השימוש ב-subclassing אפשר לנו לכתוב מודל קומפקטי וקריא יותר בהשוואה לכתיבת אותה רשת באמצעות API מסוג Sequential בלבד כפי שאפשר לראות במדריך "זיהוי ספרות שכתב אדם על ידי בינה מלאכותית".
נקמפל את המודל:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])נריץ:
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=3, batch_size=100)נעריך את ביצועי המודל:
results = model.evaluate(X_test, y_test)
print("loss: {0:.3f}".format(results[0]))
print("accuracy: {0:.3f}".format(results[1]))313/313 [==============================] - 1s 3ms/step - loss: 0.0357 - accuracy: 0.9890 loss: 0.036 accuracy: 0.989
Subclassing של מודלים
כפי שאנו יכולים לעשות subclassing עבור שכבות של מודל Keras אנחנו יכולים לעשות subclassing של מודלים.
הקלאס צריך ליישם את keras.Model ולכלול 2 מתודות: __init__() ו-call():
- בתוך המתודה __init__() נגדיר את השכבות בהם המודל צריך להשתמש.
- במתודה call() מגדירים את ה-forward pass של המודל במסגרתו הוא מעביר את הטנסורים דרך השכבות.
נכתוב subclass לסיווג תמונות:
class ImageClassificationModel(keras.Model):
def __init__(self, num_classes):
super().__init__()
self.conv1 = ConvBlock(32)
self.conv2 = ConvBlock(64)
self.flatten = layers.Flatten()
self.dense1 = layers.Dense(128, activation="relu")
self.classifier = layers.Dense(num_classes, activation="softmax")
def call(self, input_tensor):
x = self.conv1(input_tensor)
x = self.conv2(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.classifier(x)
return xיצירת subclass של model דומה מאוד ליצירת שכבה באמצעות subclassing. הבדל עקרוני הוא שספריית Keras מאפשרת לנו להפעיל את המתודות: fit(), evaluate() ו-predict() על מודלים ולא על שכבות.
נאתחל את המודל:
model = ImageClassificationModel(num_classes=10)נקמפל ונריץ:
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=3, batch_size=100)אחת המגבלות של subclassing היא שרק לאחר שמריצים את המודל אפשר להציג סיכום שלו באמצעות המתודה summary():
model.summary()
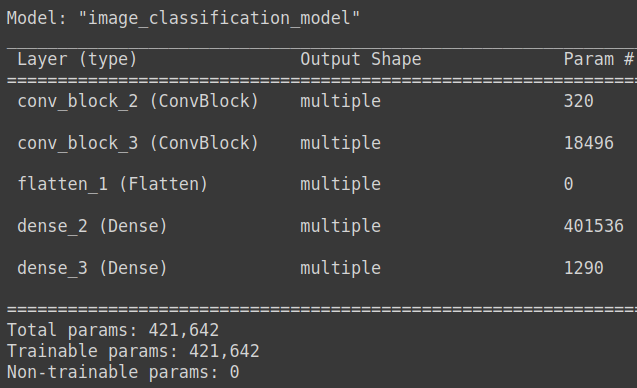
וגם אז התמונה שמקבלים אודות מבנה הרשת הוא חלקי בגלל שאין גרף. זו גם הסיבה שאי אפשר לגשת לשכבה מסוימת כדי לעשות feature extraction כפי שניתן לעשות עם ה-API הפונקציונלי.
נעריך את ביצועי המודל:
results = model.evaluate(X_test, y_test)
print("loss: {0:.3f}".format(results[0]))
print("accuracy: {0:.3f}".format(results[1]))loss: 0.030 accuracy: 0.989
סיכום
subclassing של מודלים של Keras היא הגישה הגמישה ביותר. אחריה לפי סדר יורד ה-API הפונקציונלי והסדרתי sequential. אבל לצד הגמישות subclassing של מודלים סובל מחסרונות רציניים כדוגמת בעיה לדבג, קושי בתיאור הגרף ושימוש חוזר בשכבות. אם צריך להשתמש בגישה זו אז רק כשבאמת אין ברירה. לרוב השימושים, ה-API הפונקציונלי וה-sequential מספיקים בהחלט.
להורדת הקוד אותו פיתחנו במדריך
אולי גם זה יעניין אותך
שימוש ב-TensorBoard לניטור מודלים של למידת מכונה
שימוש ב-TensorBoard לניטור מודלים של למידת מכונה
מה רואות שכבות הביניים כשעושים למידת מכונה עם מודל מבוסס CNN
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.