
שימוש ב-TensorBoard לניטור מודלים של למידת מכונה
מעקב אחר פרמטרים מדידים של למידת מכונה דוגמת, דיוק ו-loss, הכרחיים כדי שנוכל להעריך את האפקטיביות של המודל שלנו. במדריך זה נכיר את TensorBoard המאפשר מעקב אחר ביצועי המודל בזמן אמת ובפירוט רב.
נייבא את הספריות הדרושות למדריך:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats import zscore
from sklearn.model_selection import train_test_split
from tensorflow import keras
from keras.models import Sequential
from keras import layers- ספריות של פייתון המהוות את הבסיס ללמידת מכונה הם: numpy לעבודה עם מערכים רב-מימדיים, pandas להפיכת הנתונים ל-dataframe נוח לעבודה, sklearn להכנת הנתונים ללמידת מכונה ו-matplotlib להצגת תרשימים וגרפים (לכולם יש מדריכים ברשת טק).
- Keras הוא הממשק הידידותי של TensorFlow ספריית למידת מכונה המפותחת ע"י גוגל.
במהלך האימון הפונקציה fit() של TensorFlow רושמת את הנתונים לתוך תיקיית לוגים. נגדיר את תיקיית לוגים נפרדת עבור כל מקרה. לדוגמה, תיקייה של ניסוי ששמו 'experiment_0':
# tensorboard logs
filename = 'experiment_0'
log_name = f'./tf_logs/{filename}'- התיקייה experiment_0 בתוך תיקיית הלוגים tf_logs.
אין צורך ליצור ידנית את התיקיות. בזה יטפל Keras בשבילנו. אבל בהרצות חוזרות צריך למחוק את תוכן התיקייה בה נשמרים הנתונים באמצעות הרצת הפקודה הבאה בטרמינל (שורת הפקודות):
# clear the logs for the experiment
rm -rf ./tf_logs/experiment_0- בשביל המחיקה אני משתמש בפקודה של לינוקס למחיקה של תוכן התיקייה (כיצד לעבוד עם קבצים ותיקיות של לינוקס).
נגדיר את פונקצית ה-call back של TensorBoard לה נקרא מתוך המתודה fit() שמריצה את המודל:
# tensorboard callback
tensorboard = keras.callbacks.TensorBoard(
log_dir=log_name,
histogram_freq=1
)כך נראית הצורה הכללית של קריאה לפונקציה TensorBoard שזה עתה יצרנו מתוך fit() - המתודה להרצת המודל:
model.fit(x_train, y_train,
epochs=100,
callbacks=[tensorboard])- בהמשך המדריך, ניישם את הקריאה לפונקציה במסגרת דוגמת שימוש.
נקליד את השורה הבאה לתוך הטרמינל (שורת הפקודות) כדי להריץ את שרת TensorBoard שיציג את הנתונים בדפדפן:
tensorboard --logdir ./tf_logs/ --port=6006נוכל לעקוב אחר הנתונים שמציג TensorBoard אם נגלוש לכתובת הבאה בדפדפן: https://localhost:6006/
- כרגע לא נראה יותר מדי כי לא הרצנו את הניסוי.
עדיף לסגור את השרת באופן מסודר כשמסיימים לעבוד איתו באמצעות הקלקה על צירוף המקשים: Ctrl + C.
מסד הנתונים
את המודל שנפתח במדריך הסברתי בפירוט במדריך על סיווג בינארי באמצעות למידת מכונה שמלמד את המחשב לסווג יינות לשני סוגים: משובחים ונחותים באמצעות מודל TensorFlow. את נתוני היינות הורדתי מ-Wine Quality Dataset.
נוריד את מסד הנתונים ל-DataFrame:
# using the wine dataset (classify wine quality) as an example
# import dataset
wine = pd.read_csv('wine-quality.csv', sep=';')נכין את המידע ללמידת מכונה:
# preprocessing
z0 = wine.apply(zscore)
z = np.abs(zscore(wine))
z_in = (np.abs(zscore(wine)) < 3)
wine_clean = wine[z_in.all(axis=1)]
x = wine_clean.iloc[:, :-1]
y = wine_clean.iloc[:, -1]
# Divide the target (y) into 2 categories
bins = [3.0, 5.0, 8.0]
labels = ['bad','good']
wine_clean['quality_points'] = pd.cut(y, bins, labels=labels)
d = pd.get_dummies(wine_clean.loc[:,'quality_points'])
y = d.drop('bad', axis=1)
x0 = x
x = x.apply(zscore) # standardiseנחלק את מסד הנתונים לשניים - למידה ובקרה (ראה הסבר במדריך הכנת הנתונים ללמידת מכונה בעזרת sklearn):
# split between train and validation datasets
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size=0.3, random_state=42)
המודל
נבנה את המודל ונקמפל בתוך הפונקציה הבאה:
# build and compile a Keras model
def make_model(units1, units2, dropout):
model = Sequential()
model.add(layers.Dense(units1, input_shape=(11,), activation='relu'))
model.add(layers.Dropout(dropout))
model.add(layers.BatchNormalization(axis=1))
model.add(layers.Dense(units2, activation='relu'))
model.add(layers.Dropout(dropout))
model.add(layers.BatchNormalization(axis=1))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(optimizer=keras.optimizers.Adam(),
loss='binary_crossentropy',
metrics=['accuracy'])
model.summary()
return model
units1 = 256
units2 = 256
dropout = 0.1
model = make_model(units1, units2, dropout)את הלמידה עושה בפועל הפונקציה fit() לתוכה נעביר callbacks לביצוע משימות בזמן הרצת המודל.
פונקצית callback חשובה במיוחדת היא ModelCheckpoint ששומרת באופן אוטומטי את המודל הטוב ביותר:
# save the best model
from tensorflow.keras.callbacks import ModelCheckpoint
filepath = f'{filename}_model.hdf5'
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1,
save_best_only=True, save_weights_only=False,
mode='auto', save_frequency=1)- המידע של המודל נשמר בתור קובץ hdf5 הנושא את שם המודל, וכולל בתוכו את משקולות המודל.
וכמובן פונקצית callback של TensorBoard למעקב אחר ביצועי המודל בזמן אמת:
# tensorboard settings
log_name = f'./tf_logs/{filename}'
tensorboard = keras.callbacks.TensorBoard(
log_dir=log_name,
histogram_freq=1
)הפונקציה fit() שתקרא לשתי פונקציות ה-callback לעיל:
history = model.fit(x_train, y_train,
batch_size=100,
epochs=100,
validation_data=(x_val,y_val),
callbacks=[tensorboard, checkpoint])- המידע שצוברת הפונקציה במהלך הריצה על המדדים השונים דוגמת accuracy ו-loss נשמרים לתוך המשתנה history בו אפשר להשתמש כדי לעקוב אחר התפתחות ביצועי המודל.
שימוש ב-TensorBoard
TensorBoard רץ על שרת ומוצג בדפדפן. נריץ את השרת על פורט 6006 באמצעות הקלקת הפקודה הבאה לטרמינל (שורת הפקודות):
tensorboard --logdir ./tf_logs/ --port=6006נוכל לעקוב אחר הנתונים שמציג TensorBoard בכתובת הבאה בדפדפן: https://localhost:6006
בלשונית SCALARS אנחנו יכולים לראות את הגרפים עם הנתונים. לדוגמה, דיוק של קבוצת האימון והבקרה:
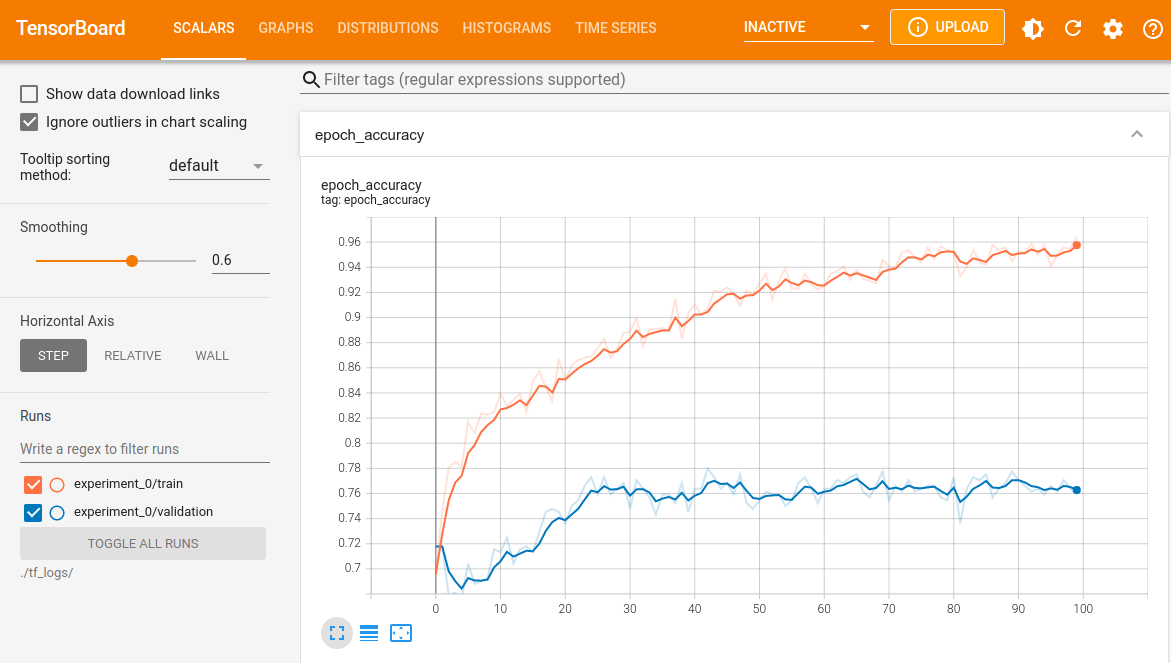
ונתוני ה-loss:
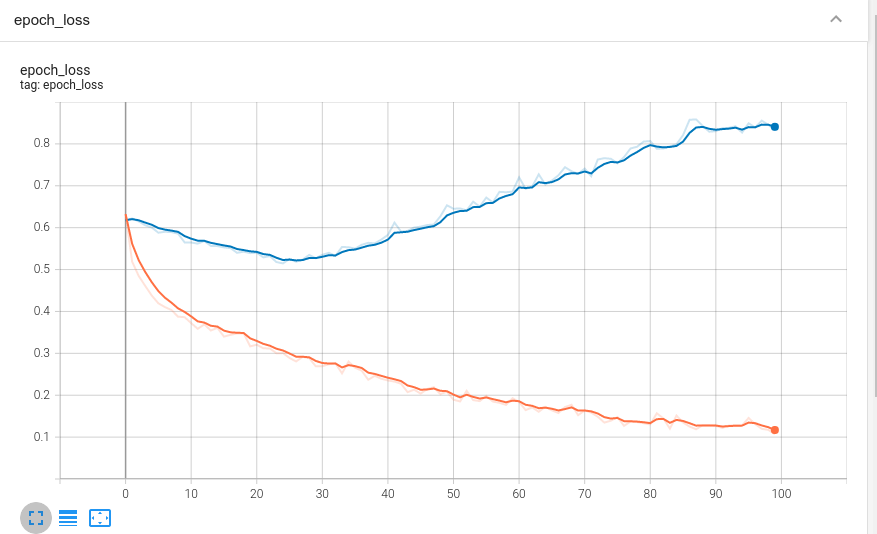
בעמודה השמאלית ניתן לבחור נתוני אילו ניסויים runs להציג:
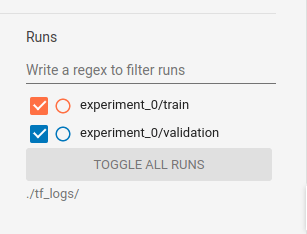
- אם עקבת אחרי המדריך אז יש לך נתונים של ניסוי אחד אבל יכול להיות מצב שתרצה להקליט ולהשוות בין נתונים של מספר ניסויים runs שונים לדוגמה, כדי לבחון האם שינוי שעשית למבנה המודל או קצב הלמידה משפר את הביצועים.
לבד מלשונית SCALARS, שהיינו בה עד עכשיו, קיימות לשוניות נוספות:

- הלשונית Graphs מציגה את מבנה המודל.
- יתר הלשוניות עוקבות אחר התפתחות הטנסורים במודל במהלך הניסוי.
דרך חלופית לעקוב אחר המדדים
לשימוש ב-TensorBoard יתרונות רבים. ביניהם: אפשרות לעקוב אחר הנתונים בזמן אמת, גרפים אינטראקטיביים ויפים, ורמת פירוט גבוהה מאוד. אבל לא תמיד הכלי החזק ביותר הוא המתאים ביותר. ועל כן נראה אפשרות פשוטה יותר להצגת השינוי במדדים במהלך הניסוי. את התוצאה של הקריאה למתודה fit() העברנו לתוך משתנה history אשר קולט לתוכו אובייקט History הכולל סדרות של נתונים אודות התפתחות מדדי המודל במהלך האימון.
נציג את המידע הכלול במשתנה history:
history.historyאם היינו מריצים את המודל במדריך רק 3 epochs היינו מקבלים:
{'loss': [0.6324319839477539,
0.5189041495323181,
0.4846927225589752],
'accuracy': [0.6955664753913879,
0.746798038482666,
0.7802955508232117],
'val_loss': [0.6177687048912048,
0.6220017671585083,
0.6149383783340454],
'val_accuracy': [0.7178899049758911,
0.7178899049758911,
0.6788991093635559]}
- 4 סדרות נתונים מספריים. סדרה לכל מדד. נתוני הסדרות מסודרים לפי סדר ה-epochs.
נשתמש בפונקציה הבאה כדי לספק תרשים של התפתחות המדדים כתלות ב-epoch על סמך הנתונים שנשמרו במשתנה history:
# a simplistic approach to plot the history
def plot_history(history, name, metric):
label_val = 'val_%s' % metric
train = history.history[metric]
test = history.history[label_val]
# Create count of the number of epochs
epoch_count = range(1, len(train) + 1)
# Visualize loss history
plt.plot(epoch_count, train, 'r-')
plt.plot(epoch_count, test, 'b--')
plt.legend(['Train', 'Test'])
plt.xlabel('Epoch')
plt.ylabel(metric)
plt.title('%s : %s' % (metric,name))
plt.show()לדוגמה, התפתחות ה-loss בקבוצת האימון והבקרה:
plot_history(history, 'loss', 'loss')
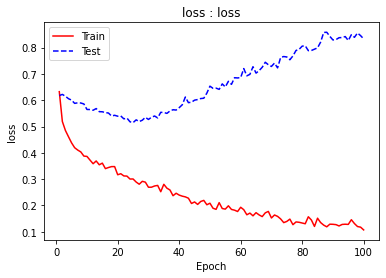
והשינוי ב-accuracy:
plot_history(history, 'accuracy', 'accuracy')
להורדת הקוד אותו פיתחנו במדריך
אולי גם זה יעניין אותך
כיצד להתגבר על overfitting במודלים מבוססי Keras?
דף צ'יטים לבניית מודלים של למידה עמוקה באמצעות Keras
הטרנספורמרים משנים את עולם הבינה המלאכותית
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.