
איך למצוא את מספר הדוגמאות הדרושות ללמידת מכונה?
ערכת את הניסוי ומצאת ערך p-value ממש קרוב למשמעותי אבל עדיין לא (לדוגמה, 0.06 בעוד הסף הוא 0.05). יכול להיות שאתה בכיוון הנכון אבל התוצאות לא תומכות במסקנה. אולי זה בגלל שהכוח הסטטיסטי של הניסוי לא מספיק חזק. מה אתה יכול לעשות? לפני שאתה עורך ניסוי נוסף כדאי לך לעשות power analysis כדי לקבוע את גודל המדגם הקטן ביותר שיאפשר לך לדחות את השערת האפס בסבירות גבוהה יותר.
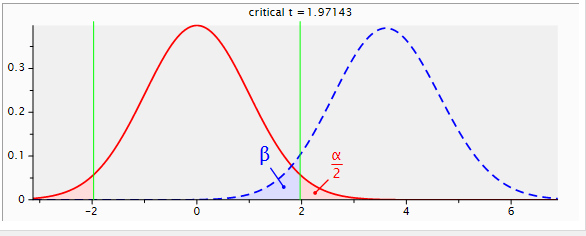
שימוש בגודל המדגם עליו המליץ ה-power analysis, יתן לך מספיק ביטחון שהניסוי הבא שתערוך יוכל לזהות השפעה, במידה וקיימת.
את ה-power analysis נערוך באמצעות התוכנה החינמית והמצויינת g*power.
כוח סטטיסטי statistical power הוא הסיכוי שמבחן יזהה השפעה במידה וקיימת. הערך המקובל הוא 80% לפחות.
ככל שהכוח הסטטיסטי של הניסוי גבוה יותר הסיכוי לעשות שגיאה מסוג False negative קטן. כאשר False negative הוא מצב בו קיימת השפעה אבל הניסוי לא מצליח לאשר אותה.
כדי לחשב את גודל המדגם שייתן למערך הניסוי מספיק כוח סטטיסטי אנחנו צריכים לדעת את ערך הסף (מכונה גם alpha או p-value), את הכוח הסטטיסטי אליו אנו שואפים ולדעת לפחות בקירוב את מידת ההשפעה (effect size).
- מקובל שהכוח הסטטיסטי של ניסוי צריך להיות לפחות 80%. מה שאומר שאנחנו מוכנים לסבול שב-20% מהמקרים המבחן לא יזהה השפעה אף שהיא קיימת.
- מקובל שערך הסף (alpha) שמעריך את הסיכוי המקסימלי ל-False positive, זיהוי השפעה בלתי קיימת, הוא 5% או פחות במבחן דו-זנבי two tails.
- את מידת ההשפעה אפשר להעריך מניסוי מקדים או מסקירת הספרות בנושא.
את מידת ההשפעה מעריכים באמצעות Cohen's d המחושב באמצעות חלוקת הפרש הממוצעים בין קבוצת הניסוי והביקורת בסטיית התקן:
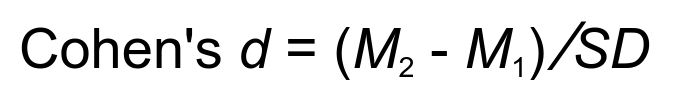
- הנוסחה מניחה סטיית תקן SD שווה בין הקבוצות.
במידה וסטיית התקן שונה, נחשב אותה באופן שמתחשב בסטיית התקן של שתי הקבוצות:
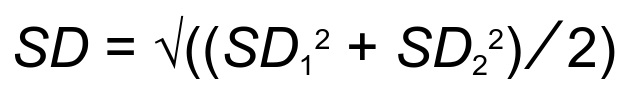
Cohen's d הוא גודל האפקט המנורמל. משמע, ההפרש בין ממוצעי הקבוצות חלקי סטיית התקן.
ההפרש בין שתי הקבוצות הוא גודל ההשפעה effect size. אותו אפשר למצוא כתוצאה מעריכת ניסויים מקדימים או מקריאה בספרות או שימוש בידע שיש לך על הנושא אותו אתה חוקר. דרך מקובלת להעריך מסתמכת על גודל ההשפעה הקטן ביותר שיש לו משמעות מעשית practically significant. לדוגמה, אם אתה בודק את השפעת תוכנית הלימוד על ציוני הנבחנים בבחינות הבגרות אפשר להגדיר ששינוי הנמוך מ-5 נקודות אינו מעשי. על פי תרחיש זה, בשביל למצוא את ערך d נחלק את 5 בסטיית התקן של ממוצע הנבחנים בבחינת הבגרות.
בעוד את גודל ההשפעה effect size מקובל להעריך על פי הערך הנמוך ביותר של הפרשים בין הקבוצות שיש לו משמעות מעשית, את סטיית התקן עדיף להשיג מניסויים קודמים (שלך או של אחרים). אם אין לך תוצאות אז תערוך ניסויים מקדימים ותשפר את ההערכה בכל פעם שיהיו לך תוצאות טובות יותר.
חישוב גודל האפקט d יכול להיות מסובך הרבה פעמים פשוט יותר להעריך את גודל ההשפעה הצפויה: גדול, קטן או בינוני. סטטיסטיקאים מעריכים את גודל ההשפעה effect size של Cohen's d כקטן כאשר הוא נע סביב 0.2, כבינוני אם הוא בערך 0.5, ואם סביב 0.8 אז הוא ההשפעה נחשבת לגדולה. אבל אילו רק כללי אצבע.
power analysis הלכה למעשה באמצעות תוכנת g*power
ישנם מחשבונים אונליין שיכולים לעזור בקביעת הכוח של ניסוי. במדריך אדגים power analysis עבור מבחן t-test באמצעות תוכנה חינמית ששמה g*power מכיוון שהיא הנוחה ביותר לעבודה.
את התוכנה הורדתי מאתר https://gpower.hhu.de, התקנתי והרצתי.

מלשונית Tests בוחרים את המבחן הסטטיסטי. יש הרבה אבל לצורך הדוגמה בחרתי במבחן t-test:
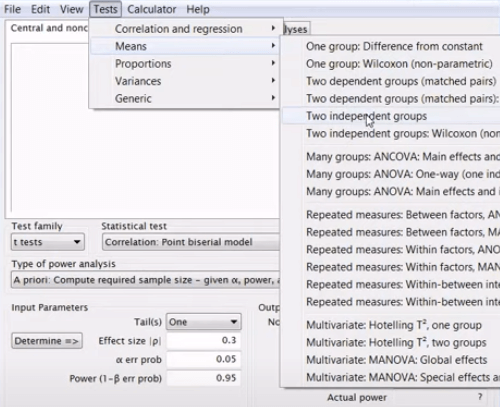
Test family: t tests
Statistical test: Means: Difference between two independent means (two groups)
נזין את הפרמטרים לתוך השדות Input parameters:
- Tail(s) - נבחר בהתפלגות דו-זנבית
- Effect size - נבחר בגודל אפקט בינוני של 0.5
- err probe α - את ערך הסף נשאיר על 0.95
- Power - נקבע על ערך מינימלי של 0.8
- Allocation ratio - הוא היחס בין מספר הדוגמאות בקבוצת הניסוי והמבחן. נשאיר את ברירת המחדל של יחס שווה.
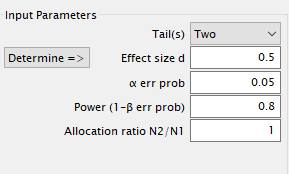
נלחץ על כפתור Calculate ונקבל תוצאה שמעריכה את גודל המדגם הדרוש בשביל הכוח הסטטיסטי אותו אנו דורשים:
- בשביל הכוח הסטטיסטי הדרוש לנו נזדקק ל- 64 דוגמאות מכל קבוצה (סה"כ 128 דוגמאות).
איך משתנה גודל המדגם עם שינוי הפרמטרים?
-
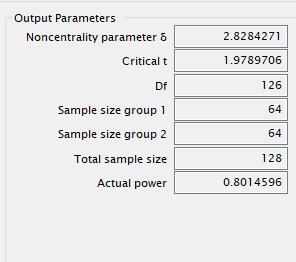
במקרה של השפעה (d) גדולה יחסית של 0.8:
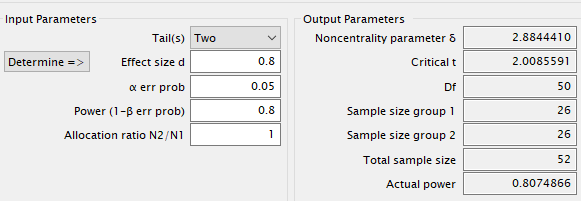
יפחת מספר הדוגמאות הדרושות בניסוי ל-26 בכל קבוצה. לעומת זאת הקטנת ההשפעה (d) ל-0.2, גורמת להגדלת מספר הדוגמאות הדרושות ל-394 מכל קבוצה.
Cohen's d הוא גודל האפקט המנורמל. משמע, ההפרש בין ממוצעי הקבוצות חלקי סטיית התקן. זה החלק שהכי קשה להעריך אותו. יכול להיות שהוא ידוע לך מניסויים קודמים. לדוגמה, אם ידוע שההפרש בין שתי הקבוצות הוא 10 וסטיית התקן היא 15 אז החישוב יהיה: d = 10/15 = 0.67, ובהתאם צריך להזין 0.67 בתור הערך של גודל האפקט, d.
חישוב d יכול להיות מסובך. למזלנו, התוכנה מספקת 3 ערכים ברירת מחדל בהם אנחנו יכולים להשתמש על פי הציפיות שלנו לגבי גודל ההשפעה: 0.2 אם ההשפעה נמוכה, 0.5 במקרה של בינונית ו-0.8 בשביל גבוהה.
-
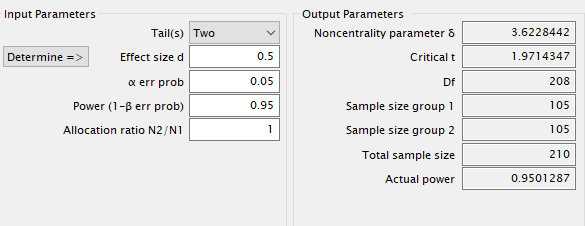
מקרה אחר הוא שלא נוח לי עם כוח סטטיסטי של 0.8 שמשמעותו ש-20% מהמקרים לא יראו השפעה משמעותית גם אם קיימת. אז אני יכול לבחור בכוח סטטיסטי גבוה יותר, לדוגמה, 0.9 עבור d בינוני של 0.5. במקרה כזה דרושות 210 דוגמאות בסה"כ (105 מכל קבוצה). ערכים שונים מקובלים בתחומים שונים ועורך הניסוי צריך להיות מודע למוסכמות בתחום שלו. הערכים המקובלים ביותר הם 0.8 ואחריו 0.9
-
אם יש סיבה מספיק טובה לחשוב שהמבחן אינו דו-כיווני, השימוש בהתפלגות חד-זנבית One tail מפחית את מספר הדוגמאות הדרושות.
-
לפעמים ניתן לשנות את מבנה הניסוי ולהשוות בתוך הקבוצות במקום בין הקבוצות. לדוגמה, להשוות ציוני תלמידים לפני ואחרי קורס הכנה לבחינה כשמשווים כל תלמיד לעצמו. מה שמאפשר שימוש במבחן סטטיסטי מזווג (paired) שכוחו גדול יותר. נשנה את את פרמטר Test family . במקום:
Means: Difference between two independent means (two groups)
נבחר:
Means: Difference between two dependent means (matched pairs)
כיצד להגדיל את הכוח הסטטיסטי של מערך הניסוי?
ככל שהכוח הסטטיסטי של הניסוי עולה גדל הסיכוי למצוא השפעה, במידה וקיימת. לכן חשוב להעלות את הכוח הסטטיסטי של מערך הניסוי.
ערך p-value משמש לקביעת המשמעות הסטטיסטית של תוצאות הניסוי. כדי לחשב p-value מבחני השערות סטטיסטיים לוקחים בחשבון 3 גורמים:
- גודל ההשפעה Effect size - ככל שהטיפול משפיע יותר קטן הסיכוי שהתוצאה מתקבלת כתוצאה משגיאה אקראית.
- גודל המדגם Sample size - מדגמים גדולים מאפשרים זיהוי השפעות קטנות יותר.
- שונות Variability - אם הדוגמאות שונות מאוד אחת מהשנייה בפרמטרים הנמדדים, רעש אקראי יצור הבדלים ניכרים בין הקבוצות.
המשמעות הסטטיסטית תלויה בגודל ההשפעה, גודל המדגם והשונות בין הדוגמאות בתוך כל קבוצה. נשתמש בזה כדי לשפר את הכוח הסטטיסטי של הניסוי:
- הדרך הראשונה, היא הגדלת מספר הדוגמאות. אם כי מעבר לכמות דוגמאות מסוימת תוספת הכוח היא שולית מה גם שאיסוף דוגמאות יכול להיות תהליך יקר. לכן כל כך חשוב לערוך power analysis על מנת להעריך את גודל המדגם.
- ניתן להגביר את ההשפעה. לדוגמה, על ידי הגדלת מינון התרופה הניתנת לחולים.
- ניתן להעלות את ערך ה-alpha. מה שיגרום להעלאת הכוח הסטטיסטי אבל גם להעלאת סיכון ה-false positive. בכל מקרה, לא מקובל לעלות מעבר ל-0.05.
- העלאת רמת הדיוק. רעש שמקורו בטעויות מדידה מגדיל את השונות variance ומפחית את הכוח הסטטיסטי. אתה יכול להעזר במבנה ניסוי של טריפליקטים (שלוש מדידות שונות מכל דוגמא) להעלאת רמת הדיוק.
- במידה ויש לך סיבה טובה מספיק להניח שההשפעה שאתה בוחן אינה דו-כיוונית אלא משפיעה בהכרח רק בכיוון אחד אז שימוש במבחן חד-זנבי one-tailed במקום two-tailed מגביר את הכוח הסטטיסטי. בכל מקרה, את ההחלטה להשתמש במבחן חד-צדדי במקום דו-צדדי אתה צריך לקבל עוד לפני עריכת הניסוי ולא אחרי שקיבלת את התוצאות וחסר לך רק קצת כדי לראות השפעה משמעותית.
לסיכום
במדריך קצר זה ראינו כיצד להשתמש ב-power analysis להערכת כמות הדוגמאות הדרושות לזיהוי השפעה, אם קיימת, ולדחיית השערת האפס. הדוגמה עסקה ב-t-test וזו לא האפשרות היחידה. תוכנת g*power מאפשרת הערכת גודל המדגם הדרוש למגוון מבחני השערות סטטיסטיים, דוגמת: ANOVA מבחן לפרופורציות או מבחנים להתפלגות פואסונית Poisson. הערכת כמות הדוגמאות הדרושות לניסוי היא מורכבת ביותר, וכוללת את סוג המבחן, גודל ההשפעה וידע ייחודי לתחום המחקר. כל אילה דורשים הבנה סטטיסטית שהיא לרוב מעבר ליכולתו של החוקר. לכן, כדי למנוע מבוכה, כדאי מראש להשתמש בתוכנה שיכולה לסייע לקבל החלטות מושכלות בנוגע לגודל המדגם כאשר עוסקים בתכנון הניסוי. יתרה מכך, התהליך המדעי הוא חוזר ונשנה. לפיכך, בכל פעם שמתכננים את הניסוי מחדש כדאי להזין את הנתונים שנאספו לתוכנה לקבלת הערכות מדויקות יותר.
דניאל כהנמן, זוכה פרס נובל לכלכלה בשנת 2002 כותב בספרו "לחשוב מהר ולאט" על הנטייה של סטטיסטיקאים מקצועיים להגזים בכוח הסטטיסטי של ניסויים: "הכנו סקר שכלל תרחישים מציאותיים של עניינים סטטיסטיים העולים במחקר. עמוס (טברסקי) אסף את התגובות של קבוצת מומחים שהשתתפו בכנס של האגודה לפסיכולוגיה מתמטית, כולל הכותבים של שני ספרי לימוד לסטטיסטיקה. כצפוי, מצאנו שידידנו המומחים, כמונו, הגזימו מאוד בסבירות של היכולת לשחזר תוצאות של ניסוי המבוסס על מספר קטן של דוגמאות. הם גם נתנו עיצה גרועה מאוד לתלמידת מחקר בנוגע למספר התצפיות שהיא צריכה לאסוף. אפילו סטטיסטיקאים כשלו בהערכה אינטואיטיבית של נתונים סטטיסטיים."
צריך להודות על התקופה שבה אנו חיים בה מתאפשר לנו להשתמש בתוכנה חינמית מצויינת כדי לקבל הערכה טובה של גודל המדגם. אף על פי כן, חשוב תמיד לשמור על עירנות, להיות ביקורתי ולהיוועץ בדעת מומחים לתחום המחקר בו אנו עוסקים, בפרט אם הצטבר מספיק ידע בתחום.
מדריכים נוספים בסדרה על למידת מכונה שיכולים לעניין אותך
לכל המדריכים בסדרה על למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.