
בחירת התכונות (feature selection) עבור מודל למידת מכונה
כשאתה עובד על מודלים של למידת מכונה אתה כל הזמן מחפש דרכים לסחוט מהמודל תוצאות טובות יותר בכל מיני דרכים. לדוגמה, על ידי מציאת מודל מוצלח יותר. הרבה פעמים הכנת הנתונים ללמידה משפיעה יותר מבחירת המודל. בפרט בחירת התכונות מהם המודל לומד.
יש גישות רבות לבחירת התכונות feature selection ללמידת מכונה. במדריך זה נסביר כיצד לשפר תוצאות של מודלים מסוג XGBoost תוך הסתמכות על המדד feature importance שנותן ניקוד לתכונות לפי מידת התרומה שלהם לתוצאות, ושימוש רק באותם התכונות שקיבלו ניקוד גבוה.
למה כדאי להשתמש בתכונות הרלוונטיות ביותר לביצועי המודל? כי נתונים רלוונטיים מפחיתים את הרעש ומגבירים את הסיגנל דבר המביא להפחתה בצריכת משאבי מחשוב ולעלייה בדיוק התוצאות.
במדריך קודם על סיווג באמצעות מודל למידת מכונה XGBoost השתמשנו באותה דוגמה בה נעשה שימוש במדריך כדי לחזות מי מנוסעי הטיטאניק ישרוד את טביעת הספינה. במדריך זה אנסה לשפר את התוצאות באמצעות בחירת התכונות המשמשות ללמידת מכונה feature selection.

המדריך מתייחס לכל הנקודות העקרוניות אבל אלוהים נמצא בפרטים אז אני ממליץ בחום להוריד את המחברת ולעיין בה: xgboost_feature_selection.ipynb.
יבוא הספריות
נייבא את הספריות:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import xgboost as xgb- numpy ו-pandas בשביל החישובים ועבודה עם מערכי נתונים
- matplotlib בשביל התרשימים
- XGBoost הוא מודל למידת מכונה
מסד הנתונים
מסד הנתונים מספק מידע על הנוסעים על סיפון הטיטאניק דוגמת: גיל, מין, מצב כלכלי, או מיקום התא בספינה. הורדתי אותו מהקישור: titanic data set
וייבאתי ל-dataframe:
df = pd.read_csv('titanic.csv')כמה עמודות ודוגמאות במסד הנתונים?
# How many rows and columns
df.shape(891, 12)
- 12 עמודות השייכות ל-891 דוגמאות.
נסקור את העמודות:
df.info()# Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object
- חלק מהעמודות מספריות, אחרות קטגוריות.
- חלק מהנתונים חסרים. לדוגמה, 77% מנתוני העמודה Cabin.
את סקירת הנתונים המלאה ניתן למצוא במדריך "סיווג באמצעות מודל למידת מכונה XGBoost".
הכנת הנתונים ללמידת מכונה
כיוון שמטרת המדריך היא להסביר על בחירת הנתונים נשים לב לתכונות (=עמודות) אותם ניתן להסיר.
מועמד ראשון במעלה להסרה אילו עמודות המתאפיינות בשיעור שונות גבוה. לדוגמה, עמודת האינדקס (PassgengerId). כיוון שלכל נוסע יש id ייחודי המודל לא יכול ללמוד מזה שום דבר.
נשתמש בפונקציה unique() כדי למצוא את הערכים הייחודיים בכל עמודה:
לדוגמה, מה שיעור הערכים הייחודיים בעמודה Survived? (כאשר מספר הדוגמאות הכולל הוא 891)
percentage = len(df[col].unique())/891*100
print(col, "{:.1f}".format(percentage))Survived 0.2
- 0.2% הוא שיעור הייחודיים בעמודה Survived.
נעזר בלולאה כדי למצוא את שיעור הייחודיים בכל עמודה של מסד הנתונים:
for col in df.columns:
percentage = len(df[col].unique())/891*100
print(col, "{:.1f}".format(percentage))PassengerId 100.0 Survived 0.2 Pclass 0.3 Name 100.0 Sex 0.2 Age 10.0 SibSp 0.8 Parch 0.8 Ticket 76.4 Fare 27.8 Embarked 0.4
העמודות בהם שיעור הנתונים הייחודיים הוא גבוה במיוחד הם: Ticket (מזהה כרטיס הנסיעה) עם 76.4% ערכים ייחודיים. 100% משמות הנוסעים (העמודה Name) וה-PassengerId הינם ייחודיים. עמודות בהם השונות גבוהה במיוחד לא תורמות, ואף עלולות להזיק כי הם מכניסות רעש שמפריע למודל ללמוד. נסיר אותם:
# remove high variance features
df_clean = df.drop(['PassengerId','Name','Ticket'], axis=1)מקור נוסף של רעש לא רצוי שעלול להפריע למודל ללמוד מקורו בעמודת בהם אחוז גבוה מהמידע חסר. אפשר למלא את החסר באמצעות נתון גנרי, כפי שתיכף נראה. מצד שני, אפשר להסיר את העמודה. זה המקום להפעיל שיקול דעת. את העמודה Cabin בה חסרים 77% מהנתונים בחרתי להסיר:
# remove columns with lots of missing values
df_clean = df_clean.drop(['Cabin'], axis=1)מלבד הסרה של עמודות יש לנו עוד כמה דברים שצריך לעשות כדי להכין את מסד הנתונים. אליהם נתייחס בקצרה בשורות הבאות.
כמעט 20% מנתוני העמודה Age חסרים. אפשר למלא את החסר באמצעות מדד אמצע, דוגמת ממוצע וחציון. הדרך המומלצת על ידי XGBoost היא למלא את החסר באפסים:
# XGBoost requires no missing cells
# we can replace the missing values with the median
# med = df_clean.Age.median()
# the XGBoost way is replacing the missing values with 0
df_clean.Age = df_clean.Age.fillna(0)נסיר דוגמאות בהם חסרים נתונים:
# drop rows with missing values
df_clean = df_clean.dropna(axis=0)את הנתונים הקטגוריים נקודד בשיטת one-hot encode:
# we have to one hot encode categorical columns before using XGBoost
categorical_columns = ['Sex', 'Embarked', 'Pclass', 'Parch']
for cname in categorical_columns:
dummies = pd.get_dummies(df_clean[cname], prefix=cname)
df_clean = pd.concat([df_clean, dummies], axis=1)
df_clean.drop([cname], axis=1, inplace=True)נפריד את הנתונים למשתנה מטרה (y) ומשתנים בלתי תלויים (x):
# separate into dependent and independent variables
y = df_clean.pop('Survived')
x = df_cleanנפצל את מסד הנתונים לשני סטים, אימון ומבחן (train and test):
x_train, x_test, y_train, y_test = train_test_split(x, y,
train_size=.7,
random_state=42,
stratify=y)
מודל הבסיס
המטרה שלנו היא לשפר את המודל על ידי הסרת חלק מעמודות ש-XGBoost נותן להם ניקוד נמוך במדד החשיבות feature importance. כדי שיהיה לנו למה להשוות נאפשר ל- XGBoost ללמוד ממסד נתונים שיש בו את כל העמודות, זה יהיה מודל הבסיס, אליו נשווה את ביצועי המודל אחרי הסרת העמודות.
אפשר להשתמש ב-XGBoost למשימות רגרסיה או סיווג. כדי לחזות מי שרד את טביעת הטיטאניק נשתמש בו כמסווג באמצעות הפונקציה xgboost.XGBClassifier:
def classify(x_train, x_test):
model = xgb.XGBClassifier(objective='binary:logistic', missing=1, seed=42)
model = model.fit(x_train,
y_train,
verbose=True,
early_stopping_rounds=10,
eval_metric='aucpr',
eval_set=[(x_test,y_test)])
return model- את האלגוריתם שמתי בתוך הפונקציה classify כדי שנוכל להשתמש בה עם הרכבים שונים של סט הנתונים הבלתי תלויים (x_train, x_test) שהפונקציה מקבלת בתור פרמטר.
המדד בו נשתמש להערכת ביצועי המודל הוא f1 כי הוא פחות מוטה ממדד accuracy בפרט במסד נתונים שאינו מאוזן. הפונקציה evaluate תשמש אותנו לביצוע ההערכה:
def evaluate(model, x_test):
y_pred = model.predict(x_test)
return classification_report(y_test, y_pred)הפונקציה מקבלת בתור פרמטרים את המודל של XGBoost והרכב שונה של סט הנתונים הבלתי תלויים של קבוצת המבחן x_test.
נאפשר ל-XGBoost ללמוד מסט נתוני האימון, הכולל את מלוא הנתונים, על מנת שיחשב את מודל הבסיס. מיד לאחר מכן, נבחן את ביצועי המודל:
model = classify(x_train, x_test)
print(evaluate(model, x_test))התוצאות:
f1-score
0 0.83
1 0.70
- מודל הבסיס מציג מדד f1 של 83% עבור קטגוריה 1 ו-70% עבור קטגוריה 0.
נשתמש בפונקציה הבאה כדי למצוא את מידת התרומה היחסית של כל אחת מהתכונות (עמודות) ליכולת הסיווג של המודל:
# make a dataframe of the feature importance
def get_feature_importance(model):
features_list = list(model.get_booster().get_fscore().items())
features_df = pd.DataFrame(features_list, columns=['feature','importance']).sort_values('importance', ascending=False)
return features_df
importance = get_feature_importance(model)נתאר את התוצאות בגרף:
# plot feature importance
from xgboost import plot_importance
from matplotlib import pyplot
plot_importance(model)
pyplot.show()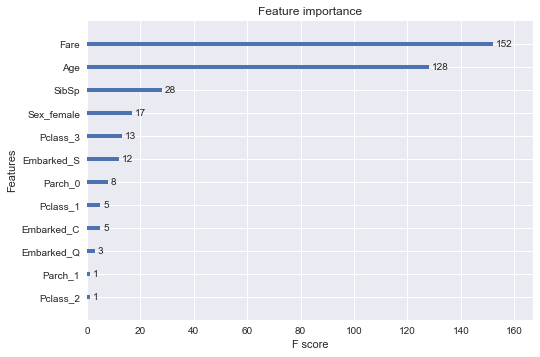
- הגרף מלמד שיש תכונות שהם יותר חשובות ליכולת הסיווג של המודל, דוגמת: Fare ו-Age, ותכונות שתרומתם קטנה בהרבה, דוגמת: Embarked ו-Pclass.
בחינת ההשפעה של בחירת תכונות על ביצועי המודל
עכשיו כשאנחנו יודעים אילו תכונות תורמות פחות מאחרות ליכולת הסיווג של המודל, נוכל להסיר אותם, ולבדוק את ההשפעה על ביצועי המודל.
לדוגמה, נסיר את התכונות אשר תרומתם היחסית נמוכה מ-3.5:
# filter out features below the threshold of 3.5
threshold = 3.5
selected_features = []
for i,r in importance.iterrows():
if r.importance >= threshold:
selected_features.append(r.feature)- דרך אחרת להגיד את זה היא שרמת הסף היא 3.5 ומה שמתחתיה מסונן החוצה.
אילו תכונות נשארו לאחר הסינון?
# which features remained
selected_features['Age', 'Fare', 'SibSp', 'Sex_female', 'Embarked_S', 'Pclass_3', 'Embarked_C', 'Parch_0', 'Pclass_1', 'Parch_2']
ניצור סט נתוני אימון ומבחן מאותם התכונות שעברו את הסינון:
# use only the filtered features for the independent sets
x_train = x_train[selected_features]
x_test = x_test[selected_features]
נסנן עם שלוש רמות סף שונות, 3, 6 ו-12 ונבחן את השפעת הסינון על התוצאות:
# classify then select with the following thresholds
thresholds = [3, 6, 12]
for threshold in thresholds:
selected_features = []
for i,r in importance.iterrows():
if r.importance > threshold:
selected_features.append(r.feature)
model = classify(x_train[selected_features], x_test[selected_features])
print(evaluate(model, x_test[selected_features]))את התוצאות סיכמתי בטבלה הבאה המציגה את ערכי f1 עבור רמות סף שונות של סינון:

- הסרה של עמודות שדירוג ה-feature importance שלהם נמוך או שווה ל-3 גרם לשיפור בביצועי המודל הנמדדים באמצעות f1.
- כשמשתמשים ברמת סף של 6 (ומסירים 4 עמודות מתוך 12) מדד f1 כלל לא נפגע.
- גם ברמת סף 12 (שמשאירה אותנו עם 4 עמודות בלבד) מדד f1 נפגע רק מעט.
סיכום
התרגיל שעשינו מלמד שאפשר להשתמש רק בחלק מתכונות מסד הנתונים ועדיין להגיע לתוצאות שלא נופלות ולעיתים אף עולות על המקור. זה חשוב כי בדרך כלל אנחנו רוצים שהמודלים שלנו יהיו מדויקים כמה שיותר וידרשו כמה שפחות משאבי מחשוב. אבל יש גם משאבים אחרים שבהם אפשר לחסוך. לדוגמה, איסוף המידע עשוי להיות החלק היקר ביותר של התהליך, וככל שאפשר לוותר על תכונות מסוימות נוכל לחסוך בעלויות.
גם זה יעניין אותך
המדריך לסיווג באמצעות XGBoost שמסביר על האלגוריתם, וכיצד ניתן לשפר אותו בשיטות שונות.
המדריך לרגרסיה באמצעות XGBoost שמציג את השיטה החזקה ביותר לשיפור התוצאות וגם כיצד לנתח את התוצאות באמצעות הכלי המוביל בתחום הסברת למידת מכונה - SHAP - explainable AI
PCA היא גישה מתמטית להפחתת מספר התכונות תוך שמירה על רוב השונות. רוצה לדעת יותר? המדריך למידת מכונה בלתי מפוקחת באמצעות PCA יעזור לך בזה.
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.