
סיווג טקסטים (בעיקר) באמצעות מודלים של Naive Bayes Classifier
עולם סיווג הטקסט בנוי על רעיון פשוט: המרת מסמכים לוקטורים מספריים, והחלטה לאיזו מחלקה הם שייכים.
גישות שונות של למידת מכונה פותחו כדי לענות על השאלה "לאיזו מחלקה שייך המסמך" ואחת הבולטות מבוססת על Naive Bayes אשר נחשב לסוס העבודה עולם עיבוד השפה NLP (Natural Language Processing).
בגלל שכל כך מקובלת להשתמש ב-Naive Bayes לצורך NLP נתרכז באופן השימוש בו במסגרת חבילת scikit-learn תוך הבאת קוד המממש pipeline הכולל: preprocessing → vectorization → classification.
אחרי שנבסס את הצורך ואת אופן השימוש ב-pipeline נראה כמה קל להחליף את המודל המסווג בתהליך למודלים שאינם Naive Bayes דוגמת: Logistic Regression ו-SVM.
לבסוף, מדריך זה יעזור לך להבין את ההבדלים בין המודלים המסווגים, את היתרונות של כל אחד, ובעיקר לאילו משימות כדאי לבחור בכל אחד מהם.
להורדת הקוד אותו נפתח במדריך (imbd_classifier_nb.zip)

מסווג בייס נאיבי Naive Bayes Classifier הוא אלגוריתם למידת מכונה הסתברותי הנמצא בשימוש נרחב למשימות סיווג טקסט. הוא מבוסס על משפט בייס, עם הנחה "נאיבית" לפיה הפיצ'רים, דוגמת שכיחות מילים, הם נפרדים ואינם תלויים זה בזה.
במדריך זה נדגים את השימוש ב-Naive Bayes Classifier ומודלים נוספים של sklearn לצורך סיווג הסנטימנט של ביקורות על סרטים אשר נאספו לתוך מסד הנתונים IMDB.
במדריכים קודמים הסברנו את משפט בייס ואת ההצדקה לשימוש בהנחת הנאיביות כאשר מסווגים באמצעות Naive Bayes Classifier. קריאה של מדריכים אילו תסייע רבות להבנת המדריך הנוכחי.
לצורך סיווג מסמכים documents לקבוצות מוגדרות במסגרת מחלקות classes נשתמש במשפט בייס באופן הבא:
P(Class|Document) = [P(Document|Class) * P(Class)] / P(Document)
כאשר:
P(Class|Document): הסתברות פוסטריורית להשתייכות המסמך למחלקה מסוימת.
P(Document|Class): הסבירות likelihood לצפייה במסמך בהינתן המחלקה.
P(Class): הסתברות קודמת prior של המחלקה.
P(Document): הסתברות המסמך בכלל מסד הנתונים (בין אם במחלקה ובין אם לאו).
ההנחה הנאיבית היא שקיום מילה מסוימת אחת במסמך אינה תלויה בנוכחות של מילים אחרות, בהינתן מחלקת המסמך. הנחה אשר מפשטת את החישוב לכדי:
P(Document|Class) = P(word1|Class) * P(word2|Class) * ... * P(wordN|Class)
בלמידת מכונה מבחינים בין שני שלבים: אימון ובחינה.
בשלב האימון המודל לומד את ההסתברויות הפריוריות prior של כל מחלקה P(Class) ואת ההסתברות המותנית של כל מילה בהינתן מחלקה P(word|Class) מסט נתוני האימון. דוגמה למחלקות הם ביקורות חיוביות או שליליות.
בשלב הבחינה המודל נחשף לסט נתוני הבחינה, אליהם הוא לא נחשף בעת האימון, והוא נדרש לסווג כל מסמך תוך חיזוי איזו מהמחלקות היא הסבירה ביותר בהינתן המסמך.
לשימוש במודל למידת מכונה מסוג Naive Bayes לצורך סיווג טקסטים יש כמה יתרונות:
- קל ופשוט ליישם מודל מסוג זה.
- תוצאות אמינות אפילו במקרה של מסד נתונים קטן.
- יכולת לסווג לכמה מחלקות ולא רק שתיים.
לשימוש במודל למידת מכונה מסוג Naive Bayes יש חסרון מרכזי הקשור בהנחה הבסיסית לפיה המילים אינם תלויות אחת בשנייה במסמך מה שהניסיון שלנו מלמד שאינו נכון. ואף על פי כן, המודל מצליח להגיע לתוצאות טובות בדרך כלל.
ייבוא הנתונים והכנה ללמידת מכונה
- את המדריך פיתחתי בסביבת Colab של גוגל.
לצורך יישום המדריך, יש לטעון את מערך הנתונים של IMDB, אשר מכיל 50,000 ביקורות סרטים המסומנות כחיוביות או שליליות. מקור מסד הנתונים הוא kaggle שהוא מיזם שכל מדען נתונים מקצועי או חובב חייב להכיר.
import os
BASE_DIR = './'
DATA_DIR = os.path.join(BASE_DIR, 'data/')
# make data directory
!mkdir -p ./data/כדי לייבא את מסד הנתונים:
# import dataset to the data directory
import kagglehub
import pandas as pd
# Download latest version of the IMDB database
path = kagglehub.dataset_download("lakshmi25npathi/imdb-dataset-of-50k-movie-reviews")
imdb_dataset = os.path.join(path, "IMDB Dataset.csv")
print("Path to dataset files:", imdb_dataset)הכי נוח הוא להפוך את מסד הנתונים ל-DataFrame של Pandas:
df = pd.read_csv(imdb_dataset, encoding = "ISO-8859-1")
# df = df[:100] # You could limit the number of items for testing
נסקור את הנתונים.
לסקירת הרשומות הראשונות במסד הנתונים:
df.head()

df.shape(5000, 2)
- יופי הרבה פריטים, מעט פיצ'רים.
האם חסרים נתונים?
df.isnull().sum().sum()np.int64(0)
- לא חסרים נתונים שזה פלוס גדול.
מהם המחלקות אליהם מתחלקים הנתונים?
df.sentiment.unique()array(['positive', 'negative'], dtype=object)
- קיימות 2 מחלקות. הביקורות מסווגות לחיוביות לעומת שליליות.
כמה ביקורות יש בכל קטגוריה?
df.groupby(['sentiment']).count()sentiment --------------------- negative 25000 positive 25000
- מסד הנתונים מאוזן הודות למספר שווה של ביקורות חיוביות ושליליות.
עיבוד מקדים של הטקסט (Text preprocessing) במסגרת הכנתו ללמידת מכונה
נתוני טקסט גולמיים דורשים ניקוי וטרנספורמציה. זה כולל לעתים קרובות:
- הסרת תגיות HTML, תווים מיוחדים ומספרים.
- המרת טקסט לאותיות קטנות.
- הסרת מילות עצירה (מילים נפוצות כמו "the", "a", "is" שאינן נושאות משמעות רבה).
- שימוש בגזירה (stemming) או lemmatization כדי להעמיד מילים על צורת השורש שלהן.
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
def preprocess_text(text):
text = re.sub(r'<br />', ' ', text) # Remove <br /> tags
text = re.sub(r'[^a-zA-Z]', ' ', text) # Remove non-alphabetic characters
text = text.lower()
words = text.split()
words = [stemmer.stem(word) for word in words if word not in stop_words]
return ' '.join(words)
df['review_preprocessed'] = df['review'].apply(preprocess_text)
פיצול מסד הנתונים לקבוצות אימון ובדיקה
כדי להעריך את יכולת המודל להתמודד עם מידע חדש, מפרידים תחילה בין משתני הקלט X, הסקירות שכתבו המשתמשים, לבין משתני המטרה Y שהם הסנטימנט (חיובי או שלילי). לאחר מכן מבצעים פיצול של המסד לשתי קבוצות: קבוצת אימון, המשמשת ללימוד המודל, ו־קבוצת בדיקה, המכילה דוגמאות שלא נחשפו למודל בזמן האימון. כך ניתן לבדוק בצורה מהימנה עד כמה המודל מצליח לחזות סנטימנט גם עבור סקירות שלא ראה בעת האימון.
from sklearn.model_selection import train_test_split
def prepare_data(df_X, df_Y):
X = df_X
y = df_Y.apply(lambda x: 1 if x == 'positive' else 0) # Convert 'positive'/'negative' to 1/0
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
return X_train, X_test, y_train, y_testX = df['review_preprocessed']
X_train, X_test, y_train, y_test = prepare_data(df["review_preprocessed"], df["sentiment"])- פה פיצלנו ל-80% קבוצת אימון והיתר לבדיקה.
וקטוריזציה של הטקסט
Naive Bayes Classifier, כמו רוב המודלים ללמידת מכונה, דורשים קלט מספרי. המרת טקסטים לייצוגים מספריים נעשים באמצעות טכניקות דוגמת: Bag-of-Words (BoW) ו-TF-IDF (Term Frequency-Inverse Document Frequency). בעוד BoW מייצג מסמך כאוסף של מספרי מילים תוך התעלמות מסדר והקשר, TF-IDF נותן משקל למילים על פי תדירות ונדירות על פני כל קורפוס המסמכים.
נתחיל משימוש ב-CountVectorizer שהוא כלי המיישם BoW.
from sklearn.feature_extraction.text import CountVectorizer # Or TfidfVectorizer
vectorizer = CountVectorizer()
X_train_vect = vectorizer.fit_transform(X_train)
X_test_vect = vectorizer.transform(X_test)
למידה ממסד הנתונים
קיימים 3 סוגים של מסווגים מסוג Naive Bayes classifiers הנבדלים במקרי השימוש:
- Multinomial Naive Bayes - מתאים לפיצ'רים (עמודות) המיוצגים בצורת התפלגות בדידה, כמו ספירת מילים, כאשר משתמשים בשיטות קידוד המתחשבות בתדירות האירועים (מילים) דוגמת BoW.
- Bernoulli Naive Bayes - מתאים לתכונות בינאריות. לדוגמה, שיטות קידוד נתונים המציינות נוכחות או היעדרות של מילה.
- Gaussian Naive Bayes - עבור נתונים המשכיים המתפלגים נורמלית.
נתחיל משימוש ב- Multinomial Naive Bayes לצורך פיתוח המודל. המודל לומד מסט אימון שעבר עיבוד ווקטוריזציה:
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB(alpha=1.0) # Using default alpha
clf.fit(X_train_vect, y_train)
הערכת ביצועי המודל
לאחר שאימנו את המודל צריך לבדוק את הביצועים שלו באמצעות מדדים מקובלים על נתונים שאליהם הוא לא נחשף בעת האימון דוגמת סט המבחן ששמנו בצד.
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report, f1_score
y_pred = clf.predict(X_test_vect)
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
def evaluate(clf, X_test, y_test, y_pred):
acc = clf.score(X_test, y_test)*100
print(f"Classifier Accuracy: {round(acc, 2)}%")
print(classification_report(y_test, y_pred))
evaluate(clf, X_test_vect, y_test, y_pred)
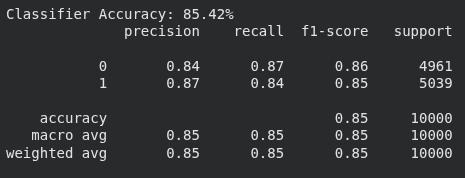
- דיוק המודל 85% וכך גם מדד F1. לקריאה אודות מדדים להערכת המודל בלמידת מכונה.
מה בנוגע ל-confusion matrix?
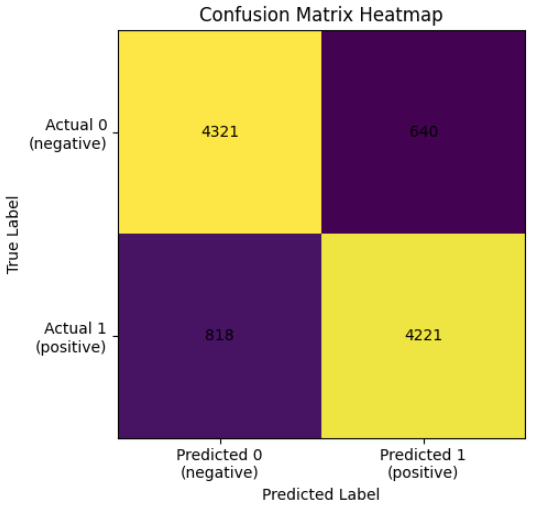
print(confusion_matrix(y_test, y_pred))[[4321 640] [ 818 4221]]
הפונקציה הבאה תאפשר לנו להציג confusion matrix באופן המושך את העין:
import matplotlib.pyplot as plt
import numpy as np
def plot_confusion_matrix(y_test, y_pred):
cm = confusion_matrix(y_test, y_pred)
fig, ax = plt.subplots(figsize=(5, 5))
im = ax.imshow(cm) # No explicit colors allowed
# Labeling
ax.set_xticks(np.arange(2))
ax.set_yticks(np.arange(2))
ax.set_xticklabels(['Predicted (Neg)', 'Predicted (Pos)'])
ax.set_yticklabels(['Actual (Neg)', 'Actual (Pos)'])
# Annotate values
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
ax.text(j, i, cm[i, j], ha='center', va='center')
plt.title("Confusion Matrix Heatmap")
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.tight_layout()
plt.show()
plot_confusion_matrix(y_test, y_pred)
מעניין לגלות לגבי אילו מסמכים טעה המודל. לצורך כך, נאתר את הדוגמאות השגויות באמצעות "מסכה":
misclassified_mask = (y_pred != y_test)נשתמש בפונקציה הבאה להציג את המסמכים שהמודל שגה בסיווג שלהם:
from IPython.display import HTML, display
import pandas as pd
def format_review(text):
return f"""
<div style="
max-height: 200px;
overflow-y: scroll;
padding: 8px;
border: 1px solid #ccc;
border-radius: 6px;
background-color: #fafafa;">
{text}
</div>
"""
def display_misclassified(y_pred, y_test):
# Convert predictions to a pandas Series with matching index
y_pred_series = pd.Series(y_pred, index=y_test.index)
# Boolean mask + indices
misclassified_mask = (y_pred_series != y_test)
misclassified_indices = misclassified_mask[misclassified_mask].index
# Build a DataFrame of misclassified rows
mis_df = pd.DataFrame({
"Predicted": y_pred_series.loc[misclassified_indices].map({1: "positive", 0: "negative"}),
"Actual": y_test.loc[misclassified_indices].map({1: "positive", 0: "negative"}),
"Review": X_test.loc[misclassified_indices]
})
mis_df_html = mis_df.copy()
mis_df_html["Review"] = mis_df["Review"].apply(format_review)
# Display as HTML
display(HTML(mis_df_html.to_html(escape=False)))
display_misclassified(y_pred, y_test)
בחינת המודל על דוגמאות שאינם במסד הנתונים
נבחן את יכולת הסיווג של המודל המאומן על מסמכים שאינם במסד הנתונים. הרשימה הבאה כוללת 5 ביקורות מומצאות:
test_reviews = [
"What a disappointment. The plot makes no sense and the pacing is painfully uneven.",
"An absolute delight from start to finish with lots of charming moments.",
"This film tries to be deep but ends up feeling pretentious and boring.",
"The movie has a few interesting ideas but overall suffers from weak execution.",
"The camera work is fantastic, but the story is messy and the characters are shallow.",
]ונעזר בפונקציה הבאה לבחינת הביקורות:
def predict_reviews(clf, preprocessed_reviews, reviews=None):
if reviews == None:
reviews = preprocessed_reviews
preds = clf.predict(preprocessed_reviews)
prob = clf.predict_proba(preprocessed_reviews)
# Convert numeric labels → words
sentiment_map = {1: "positive", 0: "negative"}
sentiments = [sentiment_map[p] for p in preds]
df = pd.DataFrame({
"Review": reviews,
"Sentiment": sentiments,
"Probability": prob[:, 1]
})
return dfנריץ את הפונקציה:
test_reviews_df = pd.DataFrame(test_reviews, columns=['Text'])
preprocessed_reviews = test_reviews_df['Text'].apply(preprocess_text)
reviews_vect = vectorizer.transform(preprocessed_reviews)
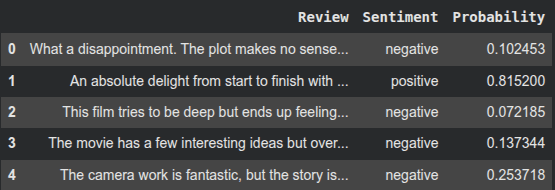
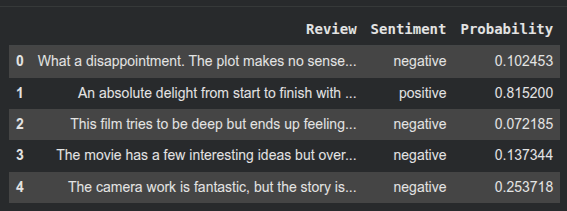
predict_reviews(clf, reviews_vect, test_reviews)התוצאות מסוכמות בטבלה הבאה:
שימוש ב-pipeline
בחינת השפעת שינוי פרמטרים ואף שלבים שלמים על המודל עלולה להיות מייגעת, וכאן בא לעזרה pipeline של sklearn. לדוגמה, pipeline אשר מאפשר הרצה לפי סדר של שלבי עיבוד הטקסט ואח"כ הרצת המודל ללמידת מכונה:
from sklearn.pipeline import Pipeline
clf = Pipeline([
('vectorizer', CountVectorizer()),
('classifier', MultinomialNB(alpha=1.0))
])עכשיו כל מה שנשאר לעשות הוא להריץ את ה-pipeline אשר יעשה את צעדי העיבוד והסיווג ללא הצורך להוסיף כל אחד מהשלבים באופן ידני.
X_train, X_test, y_train, y_test = prepare_data(df["review"], df["sentiment"])
clf.fit(X_train, y_train)
נבחן את ביצועי המודל המאומן על סט נתוני הביקורת:
y_pred = clf.predict(X_test)
evaluate(clf, X_test, y_test, y_pred)Classifier Accuracy: 84.9%
precision recall f1-score support
0 0.83 0.88 0.85 4961
1 0.87 0.82 0.85 5039
accuracy 0.85 10000
macro avg 0.85 0.85 0.85 10000
weighted avg 0.85 0.85 0.85 10000
שימוש ב-pipeline על פונקציות שאינן שייכות לספריית sklearn
ניתן להשתמש ב-pipeline של sklearn על פונקציות שאינן שייכות לספרייה. כדי להדגים זאת נפתח קלאס לעיבוד מקדים של טקסט אותו נשלב בשלב הבא לתוך ה-pipeline.
from sklearn.base import BaseEstimator, TransformerMixin
import pandas as pd
import numpy as np
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
# Ensure stopwords are downloaded
nltk.download("stopwords")
stop_words = set(stopwords.words("english"))
stemmer = PorterStemmer()
class TextPreprocessor(BaseEstimator, TransformerMixin):
"""
Full preprocessing transformer:
- Remove HTML
- Strip non-letters
- Lowercase
- Remove stopwords
- Stemming
"""
def __init__(self):
pass # no parameters (for now)
def clean_text(self, text):
# Basic preprocessing
text = re.sub(r"<br /?>", " ", text)
text = re.sub(r"[^a-zA-Z]", " ", text)
text = text.lower()
words = text.split()
words = [stemmer.stem(w) for w in words if w not in stop_words]
return " ".join(words)
def fit(self, X, y=None):
return self # No fitting needed
def transform(self, X):
# Accept Series, lists, numpy arrays
if isinstance(X, pd.Series):
return X.apply(self.clean_text).tolist()
if isinstance(X, (list, np.ndarray)):
return [self.clean_text(x) for x in X]
raise TypeError(f"Unsupported input type: {type(X)}")את הקלאס TextPreprocessor לעיל נשלב ב-pipline באופן הבא:
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
clf = Pipeline([
('preprocess', TextPreprocessor()),
('vectorize', CountVectorizer()), # Optional: TfidfVectorizer()
('model', MultinomialNB(alpha=1.0))
])נפצל את מסד הנתונים המקורי לסט אימון ובחינה:
X_train, X_test, y_train, y_test = prepare_data(df["review"], df["sentiment"])ונריץ את ה-pipeline על סט נתוני האימון:
clf.fit(X_train, y_train)
- התוצאה היא מודל מאומן.
נבחן את המודל המאומן על סט נתוני הבחינה:
y_pred = clf.predict(X_test)נעריך את ביצועי המודל על סט המבחן בעזרת הפונקציה אותה הכנו מראש:
evaluate(clf, X_test, y_test, y_pred)והתוצאות:
Classifier Accuracy: 85.42%
precision recall f1-score support
0 0.84 0.87 0.86 4961
1 0.87 0.84 0.85 5039
accuracy 0.85 10000
macro avg 0.85 0.85 0.85 10000
weighted avg 0.85 0.85 0.85 10000
נבחן את ביצועי המודל על הרשימה של `test_reviews` שאין מקורה בסט הנתונים IMDB:
predict_reviews(clf, test_reviews)
החלפת הפונקציות ב-pipeline
נדגים החלפה של אחת הפונקציות ב-pipeline על ידי כך שנשתמש לצורך הוקטוריזציה בפונקציה TfidfVectorizer במקום בפונקציה CountVectorizer:
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
clf = Pipeline([
('preprocess', TextPreprocessor()),
('vectorizer', TfidfVectorizer()),
('classifier', MultinomialNB()),
])נאמן את ה-pipeline לאחר שהחלפנו את הפונקציה האחראית על הוקטוריזציה:
clf.fit(X_train, y_train)
נבחן את ביצועי ה-pipeline על נתוני המבחן:
y_pred = clf.predict(X_test)נעריך את הביצועים:
evaluate(clf, X_test, y_test, y_pred)Classifier Accuracy: 86.03%
precision recall f1-score support
0 0.85 0.87 0.86 4961
1 0.87 0.85 0.86 5039
accuracy 0.86 10000
macro avg 0.86 0.86 0.86 10000
weighted avg 0.86 0.86 0.86 10000
ומה לגבי test_reviews?
predict_reviews(clf, test_reviews)שינוי המודל המסווג ב-pipeline
עד שלב זה של המדריך השתמשנו במודל Naive Bayes של scikit-learn לצורך ביצוע משימות סיווג טקסט. בפרט, במודל MultinomialNB בו הנחת הנאיביות באה לביטוי בסיווג מבוסס תדירויות מילים במסמך. כאשר המודל חוזה את ההסתברות לצפייה בתדירויות מילים נתונות עבור כל אחת מהמחלקות.
הפסאודו-קוד הבא מדגים את סדר העבודה כאשר משתמשים במודל MultinomialNB:
from sklearn.naive_bayes import MultinomialNB ... (vectorize text data, e.g., using CountVectorizer or TfidfVectorizer) model = MultinomialNB() model.fit(X_train, y_train)
מסווגים נוספים ממשפחת Naive Bayes
המודל MultinomialNB הוא אכן הבחירה הנפוצה ביותר לסיווג טקסט במיוחד כאשר עובדים עם תדירויות מילים או עם פונקציות וקטוריזציה כמו TF-IDF. אך בספריית scikit-learn קיימים וריאנטים נוספים של מסווג בייס נאיבי, שלכל אחד מהם מאפיינים ושימושים מעט שונים.
להלן סקירה קצרה של האפשרויות המרכזיות, וכיצד הן עשויות להשתלב במשימות סיווג טקסט כמו סיווג ביקורות IMDB.
Bernoulli Naive Bayes (BernoulliNB)
ניסוי ברנולי הוא ניסוי אקראי עם שתי תוצאות אפשריות בלבד: "הצלחה" ו"כישלון", כאשר ההסתברות להצלחה קבועה עבור כל ניסוי. דוגמאות נפוצות כוללות הטלת מטבע (עץ - הצלחה, פאלי - כישלון) או שחקן כדורסל שקולע או מחמיץ זריקת עונשין. כל ניסוי הוא בלתי תלוי, כלומר תוצאתו של ניסוי אחד אינה משפיעה על תוצאתו של הניסוי הבא.
מתוך ניסוי ברנולי נגזר מסווג נאיבי מסוג BernoulliNB אשר מתאים למצבים שבהם התכונות הן בינאריות. כלומר, מה שמעניין הוא אך ורק האם מילה מופיעה במסמך או לא, בלי קשר לתדירות הופעתה.
מודל זה מתאים במיוחד לייצוגים מהסוג bag-of-words presence/absence, שבהם עצם נוכחות המילה חשובה יותר מכמה פעמים היא מופיעה. למשל, עבור מסמך קצר או עבור מילים שעצם הופעתן עושה את ההבדל (כמו מילים רגשיות חיוביות/שליליות).
נדגים שימוש במסווג BernoulliNB באמצעות פסאודו-קוד:
from sklearn.naive_bayes import BernoulliNB vectorize text → ensure binary features (0/1) model = BernoulliNB() model.fit(X_train, y_train)
מתי מסווג בייס מבוסס ברנולי מתאים לטקסט?
- כאשר רוצים מודל פשוט ומהיר במיוחד.
- כאשר תדירות מילים אינה חשובה.
- כאשר רוצים להקטין רגישות ל"רעש" של מילים שחוזרות לעיתים קרובות.
בפועל, MultinomialNB לרוב נותן ביצועים טובים יותר על קורפוסים גדולים, אבל BernoulliNB יכול להיות יעיל על טקסטים קצרים או תכונות בינאריות.
Complement Naive Bayes (ComplementNB)
ComplementNB הינו וריאנט חשוב במיוחד של Naive Bayes המותאם למקרים שבהם קבוצות הנתונים אינן מאוזנות כלומר כאשר קיימת מחלקה נדירה בהרבה מהאחרות.
במקום לחשב את ההסתברות מתוך הדוגמאות של כל מחלקה, המודל משתמש בהשלמה שלה, כל שאר המחלקות יחד, וכך מפחית את ההטיה שנוצרת כאשר מחלקה מסוימת כמעט אינה מופיעה.
בניסויים רבים בסיווג טקסט כולל בתיעוד רשמי של scikit-learn, ComplementNB משיג ביצועים טובים יותר מאשר MultinomialNB על מערכי נתונים "קשים" ולא מאוזנים.
שימוש טיפוסי (פסאודו-קוד):
from sklearn.naive_bayes import ComplementNB vectorize text (counts or TF–IDF) model = ComplementNB() model.fit(X_train, y_train)
מתי זה מתאים לטקסט?
- כאשר אחת המחלקות נדירה במיוחד. לדוגמה, ניתוח סנטימנט שבו ביקורות שליליות מהוות רק 20% מהנתונים.
- כאשר המודל MultinomialNB נוטה לטעות במחלקות קטנות.
- כאשר יש צורך בעמידות גבוהה יותר למערכי טקסט אמיתיים ולא "נקיים".
Gaussian Naive Bayes (GaussianNB)
Gaussian Naive Bayes קיים ב-scikit-learn, ומניח שהתכונות מתפלגות נורמלית (Gaussian). הנחה שאינה מתאימה לייצוגי טקסט כמו ספירות מילים או TF-IDF.
לפיכך, GaussianNB כמעט אינו בשימוש לסיווג טקסט. הוא מתאים יותר לנתונים מספריים רציפים בתחומים אחרים (למשל, מאפיינים ביולוגיים או פיזיקליים).
פסאודו-קוד מדגים:
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train_dense, y_train)
כמעט ואף פעם לא משתמשים ב-Gaussian Naive Bayes למשימות סיווג טקסט.
למרות שמודל MultinomialNB הוא סוס העבודה הקלאסי לסיווג טקסט, לעיתים כדאי לשקול:
- BernoulliNB - אם התכונות בינאריות ונרצה מודל פשוט ומהיר.
- ComplementNB - אם הנתונים לא מאוזנים או שהביצועים של MultinomialNB אינם מספקים.
- GaussianNB - בדרך כלל לא לטקסט.
כל אחד מהמודלים הללו מבוסס על עקרונות בייסיאניים פשוטים, אך הדגשים השונים שלהם מאפשרים להתאים את המודל טוב יותר לדרישות הבעיה והנתונים.
נחליף את המסווג ב-pipeline ל-BernoulliNB:
from sklearn.naive_bayes import BernoulliNB
clf = Pipeline([
('preprocess', TextPreprocessor()),
('vectorizer', TfidfVectorizer()),
('classifier', BernoulliNB()),
])
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
evaluate(clf, X_test, y_test, y_pred)תוצאת ההערכה על סט נתוני המבחן:
Classifier Accuracy: 89.21%
precision recall f1-score support
0 0.90 0.88 0.89 4961
1 0.88 0.91 0.89 5039
accuracy 0.89 10000
macro avg 0.89 0.89 0.89 10000
weighted avg 0.89 0.89 0.89 10000
- מעניין שדווקא מסווג BernoulliNB השיג תוצאות טובות יותר עם f1-score של 89%.
שינוי המודל המסווג ב-pipeline למסווגים שאינם בייסיאנים
הסוגים השונים של מודל Naive Bayes מובילים במשימות סיווג טקסט אך אינם היחידים המשמשים בתחום.
לאחר ביסוס ה־pipeline שלנו, הכולל שלבי preprocessing, קטוריזציה (TF-IDF), וסיווג, פשוט למדי להחליף את שכבת הסיווג במטרה לבדוק מודלים מסוגים נוספים.
בחבילת scikit-learn ישנה משפחה גדולה של מסווגים שאינם מבוססי בייס, שחלקם מציגים ביצועים מרשימים במיוחד על משימות סיווג טקסט.
להלן סקירה של האפשרויות המרכזיות.
מסווגים לינאריים (Linear Models)
Logistic Regression רגרסיה לוגיסטית
אחד המסווגים החזקים והפשוטים ביותר לטקסט הוא רגרסיה לוגיסטית בזכות יכולות התמודדות טובה עם מרחבי־תכונות דלילים (sparse), כמו אלו שמייצר TF-IDF.
יתרונות המודל כוללים:
- מהיר, יציב ויעיל מאוד למימדים גבוהים.
- ניתן לפרש את המשקולות (מילים שמושכות למחלקה חיובית/שלילית).
- משמש כ base line מצוין להשוואה עם מודלים מורכבים יותר.
דוגמה לשימוש במסגרת pipeline:
from sklearn.linear_model import LogisticRegression
clf = Pipeline([
('preprocess', TextPreprocessor()),
('vectorizer', TfidfVectorizer()),
('classifier', LogisticRegression(solver='saga')), # For small datasets, ‘liblinear’ is a good choice, whereas ‘sag’ and ‘saga’ are faster for large ones
])
X_train, X_test, y_train, y_test = prepare_data(df["review"], df["sentiment"])
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
evaluate(clf, X_test, y_test, y_pred)התוצאה על סט המבחן שלנו:
Classifier Accuracy: 89.21%
precision recall f1-score support
0 0.90 0.88 0.89 4961
1 0.88 0.91 0.89 5039
accuracy 0.89 10000
macro avg 0.89 0.89 0.89 10000
weighted avg 0.89 0.89 0.89 10000
- דיוק: ~89%, עם איזון יפה בין precision ל-recall.
- זהה כמעט לביצועי BernoulliNB מה שממחיש כמה מסווגים לינאריים יעילים לסיווג טקסט.
Support Vector Machines: SVM / LinearSVC
מסווגי SVM, ובפרט LinearSVC, נחשבים לכלים חזקים לסיווג טקסט עם כמה חסרונות בולטים.
יתרונות:
- יוצרים "מרווח הפרדה" רחב בין המחלקות.
- מתמודדים היטב עם מאות אלפי תכונות.
- לעיתים מציגים ביצועים טובים במיוחד בבעיות קשות.
החיסרון העיקרי הוא שהם כבדים מאוד חישובית, במיוחד כשמריצים על CPU.
פסאודו-קוד:
from sklearn.svm import SVC
clf = Pipeline([
('preprocess', TextPreprocessor()),
('vectorizer', TfidfVectorizer()),
('classifier', SVC(kernel='linear', probability=True)),
])
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
evaluate(clf, X_test, y_test, y_pred)
predict_reviews_pipeline(clf, test_reviews)
מסווגי Ensemble (יער ו-Boosting)
Random Forest יער אקראי
מודל Ensemble מבוסס על מספר רב של עצי החלטה כאשר הקטגוריה "הזוכה" היא זו אשר מצביעים עבורה המספר הרב ביותר של עצים.
יתרונות:
- מסוגלים ללכוד אינטראקציות מורכבות בין תכונות.
- יציבות בסביבת נתונים רועשת.
חסרונות:
- פחות יעילים במרחבים דלילים כמו טקסט.
- זמן אימון והסקה איטי עם דיוק שהוא נחות מזה של מסווגים לינאריים.
דוגמה לשימוש במסגרת pipeline:
from sklearn.ensemble import RandomForestClassifier
clf = Pipeline([
('preprocess', TextPreprocessor()),
('vectorizer', TfidfVectorizer()),
('classifier', RandomForestClassifier(n_estimators=100, random_state=42)),
])
X_train, X_test, y_train, y_test = prepare_data(df["review"], df["sentiment"])
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
evaluate(clf, X_test, y_test, y_pred)התוצאות:
Classifier Accuracy: 85.41%
precision recall f1-score support
0 0.85 0.86 0.85 4961
1 0.86 0.85 0.85 5039
accuracy 0.85 10000
macro avg 0.85 0.85 0.85 10000
weighted avg 0.85 0.85 0.85 10000
- עם דיוק ~85% המודל Random Forest מציג ביצועים נמוכים בכל הנוגע לסיווג טקסט.
מסווגים נוספים שכדאי להזכיר
במדריך זה ניסינו את המודלים מסווגי הטקסט הנפוצים ביותר. ישנם מודלים מסווגים נוספים, וביניהם:
Gradient Boosting (XGBoost / LightGBM / GradientBoostingClassifier)
XGBoost הוא מודל למידת מכונה מבוסס עצי החלטה שמוכיח עליונות על למידת מכונה עמוקה ברוב המקרים וכל עוד מסד הנתונים אינו גדול ומסובך מדי.
המודלים:
- יכולים להגיע לביצועים גבוהים מאוד אולם מתאימים יותר לנתונים טבלאיים מאשר לטקסט גולמי.
- מגיבים טוב כאשר המידע מרוכז במספר מצומצם של תכונות משמעותיות שזה לרוב לא המקרה ב-TF-IDF.
- לא הבחירה הראשונה למשימות טקסט.
K-Nearest Neighbors (KNN)
KNN מסווגים פריטים לקטגוריות על בסיס מרחק במרחב.
חסרונות המודל לטובת סיווג מסמכים כוללות בעיות במרחב רב ממדי עם מספר גדול של תכונות (curse of dimensionality) ואיטיות בחיזוי.
איך לבחור את המודל המסווג המתאים?
הטבלה הבאה מסכמת את הידע בתחום לגבי הביצועים של מודלים מובילים של למידת מכונה על משימות סיווג טקסט.
|
מסווג |
מתי לבחור בו? |
ביצועים |
|---|---|---|
|
Multinomial |
מהיר מאוד, קורפוסים גדולים, מודל בסיס מצוין |
טובים - מצוינים |
|
Bernoulli NB |
תכונות בינאריות, טקסט קצר |
טובים - מצוינים |
|
ComplementNB |
נתונים לא מאוזנים, מונחים נדירים |
מצוינים |
|
Logistic Regression |
מומלץ כברירת מחדל |
מצטיינים |
|
LinearSVC |
המודל החזק ביותר לרוב |
מצטיינים אך איטיים |
|
XGBoost / GBM |
סיווג נתונים טבלאיים, לא טקסט |
בינוניים לטקסט |
|
Random Forest |
לא מומלץ לטקסט |
בינוניים |
|
Trees / KNN |
לא מומלץ לטקסט |
גרועים |
סיום: מה כדאי לזכור?
כל המודלים שהצגנו, למן Naive Bayes הקלאסי ועד LinearSVC, חולקים רעיון משותף: צורך לקבל ייצוג מספרי של הטקסט (לרוב בגישת TF-IDF), ואז לסווג לאיזו מחלקה התוכן שייך.
אבל הבחירה במודל הנכון אינה אוטומטית. היא תלויה, בין השאר: במספר הדוגמאות, האם המחלקות מאוזנות, בזמינות משאבי חישוב (דוגמת GPU או CPU), מהירות ההסקה וברמת הדיוק הנדרשת.
אם אתה מחפש כללי אצבע אז:
- ה-baseline המהיר: MultinomialNB
- לנתונים לא מאוזנים: ComplementNB
- ברירת המחדל החזקה: Logistic Regression
- מיקסום ביצועים: LinearSVC
והדבר החשוב ביותר, כמו תמיד בלמידת מכונה, הוא לא להתחתן עם מודל. לבחון, להשוות, למדוד, ולבחור את מה שעובד הכי טוב בתכלס על הדאטה שלך בסביבת העבודה הזמינה לך.
להורדת הקוד אותו פיתחנו במדריך (imbd_classifier_nb.zip)
אולי גם זה יעניין אותך
מה ההצדקה לשימוש ב-Naive Bayes Classifier בלמידת מכונה
חשיבה בייסיאנית Bayesian: אינטואיציה והבנה בסיסית
סיווג לקבוצות באמצעות למידת מכונה
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.