
הגדרת סדר העבודה ללמידת מכונה באמצעות pipeline
למידת מכונה היא תהליך שנעשה בשלבים. כולל: הכנת הנתונים, הרצת המודל, הערכת הביצועים, ופריסת הפיתרון לשירות הלקוח. ספריית sklearn כוללת שפע של חבילות המטפלות בשלב הכנת הנתונים ובלמידה בפועל. המתודות להכנת הנתונים, ה-transformers, משנות את המידע, כולל: השלמת נתונים חסרים, סטנדרטיזציה של נתונים מספריים, קידוד הקטגוריות. המודלים המשמשים ללמידת מכונה, ה-estimators, כוללים: רגרסיה, סיווג, עצי החלטה, ועוד. sklearn מציע דרך לשלב את ה-transformers וה-estimators לתהליך מסודר המכונה pipeline בתוכו נשרשר לפי סדר את השלבים הדרושים ללמידת מכונה.

הספריות הבסיסיות
import pandas as pd
import numpy as npבהמשך נייבא ספריות נוספות, כולם שייכות ל-sklearn, בהם החבילה Pipeline לביצוע שלבי למידת מכונה על פי סדר מוגדר מראש.
מסד הנתונים
מסד הנתונים כולל דוגמאות של תלמידי תיכון מפורטוגל. מטרת המודל אותו נפתח במדריך היא לנבא את הציון במתמטיקה בסוף השנה על סמך נתונים. דוגמת: גיל, מצב כלכלי ונתונים התנהגותיים.
# https://archive.ics.uci.edu/ml/datasets/student+performance
# Goal: predict student performance in Math
df = pd.read_csv('data/student-mat.csv', sep=';')
כמה שורות ועמודות?
df.shape(395, 32)
- 395 דוגמאות של תלמידים שצריך לנבא את ציון סוף השנה שלהם על סמך 31 תכונות.
נציץ בשורות הראשונות של מסד הנתונים:
df.head()

האם חסרים נתונים?
# how many missing values in the dataset
df.isna().sum().sum()0
- נראה שאין חוסרים.
מה לגבי סוג הנתונים בעמודות?
df.info()RangeIndex: 395 entries, 0 to 394 Data columns (total 33 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 school 395 non-null object 1 sex 395 non-null object 2 age 395 non-null int64 3 address 395 non-null object 4 famsize 395 non-null object 5 Pstatus 395 non-null object 6 Medu 395 non-null int64 7 Fedu 395 non-null int64 8 Mjob 395 non-null object 9 Fjob 395 non-null object 10 reason 395 non-null object 11 guardian 395 non-null object 12 traveltime 395 non-null int64 13 studytime 395 non-null int64 14 failures 395 non-null int64 15 schoolsup 395 non-null object 16 famsup 395 non-null object 17 paid 395 non-null object 18 activities 395 non-null object 19 nursery 395 non-null object 20 higher 395 non-null object 21 internet 395 non-null object 22 romantic 395 non-null object 23 famrel 395 non-null int64 24 freetime 395 non-null int64 25 goout 395 non-null int64 26 Dalc 395 non-null int64 27 Walc 395 non-null int64 28 health 395 non-null int64 29 absences 395 non-null int64 30 G1 395 non-null int64 31 G2 395 non-null int64 32 G3 395 non-null int64 dtypes: int64(16), object(17) memory usage: 102.0+ KB
- מסד הנתונים מכיל תערובת של עמודות קטגוריות עם עמודות מספריות.
ראינו שאין חוסרים במסד הנתונים. כדי להצדיק הוספת שלב של השלמת נתונים כחלק מה-pipeline נכניס חוסרים באקראי לשתי עמודות.
הראשונה מספרית:
# enter random nan values to one of the numerical columns
np.random.seed(6)
r = np.random.choice(df.index, size=10, replace=False)
df.loc[r, 'age'] = np.nanהשנייה קטגורית:
# enter random nan values to one of the categorical columns
np.random.seed(7)
r = np.random.choice(df.index, size=10, replace=False)
df.loc[r, 'famsize'] = np.nan
הכנת הנתונים ללמידת מכונה
המודל צריך לנבא את ציוני סוף השנה של התלמידים על סמך יתר העמודות. על כן נפריד את העמודה G3 (ציוני התלמידים) מכל יתר העמודות:
X = df.drop("G3", axis=1)
y = df.G3חשוב מאוד להפריד את מסד הנתונים לסט אימון train ומבחן test עוד לפני ביצוע טרנספורמציות במסגרת ההכנה של מסד הנתונים כדי למנוע דליפת מידע data leakage - כאשר התהליכים שמטפלים בסט האימון מודעים לתוצאות בסט המבחן.
נפריד לסט אימון ומבחן:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)מסד הנתונים מכיל משתנים קטגוריים ומספריים. עיבוד הנתונים יכלול השלמת הנתונים החסרים בשני המקרים. הכנת הנתונים הקטגוריים תכלול בנוסף קידוד one hot encoding. הכנת הנתונים המספריים תכלול סטנדרטיזציה.
כיוון שעמודות קטגוריות צריכות לעבור תהליכים שונים מאילו המספריות נתחיל מהפרדה לשני הסוגים.
לעמודות מספריות:
num_cols = [col for col in X_train.columns if X_train[col].dtypes!='O']
num_cols['age', 'Medu', 'Fedu', 'traveltime', 'studytime', 'failures', 'famrel', 'freetime', 'goout', 'Dalc', 'Walc', 'health', 'absences', 'G1', 'G2']
ולעמודות קטגוריות:
cat_cols = [col for col in X_train.columns if (X_train[col].dtypes=='O')]
cat_cols['school', 'sex', 'address', 'famsize', 'Pstatus', 'Mjob', 'Fjob', 'reason', 'guardian', 'schoolsup', 'famsup', 'paid', 'activities', 'nursery', 'higher', 'internet', 'romantic']
כיוון שאנחנו רוצים לערוך יותר מטרנספורמציה אחת נשתמש ב-pipeline.
נייבא את הספריות הדרושות לעיבוד הנתונים:
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder- Pipeline - מאפשר את ביצוע הפעולות של למידת המכונה על פי סדר מוגדר מראש. מועיל במיוחד כשרוצים לחזור על אותם פעולות לפי סדר מסוים.
- ColumnTransformer - לביצוע פעולות שונות על סוגי נתונים שונים.
- SimpleImputer - מתודה לביצוע imputation - החלפת נתונים חסרים באחרים (לדוגמה, החלפת הדוגמאות החסרות בממוצע הדוגמה).
- StandardScaler - סטנדרטיזציה של נתונים מספריים.
- OneHotEncoder - קידוד נתונים קטגוריים.
ניצור שני pipelines. אחד בשביל העמודות המספריות והשני בשביל הקטגוריות כיוון שכל סוג נתונים דורש תהליכי עיבוד שונים.
ניצור את ה-pipeline בשביל העמודות המספריות:
numerical_pipeline = Pipeline([
('numerical_imputation', SimpleImputer(strategy='median', add_indicator=False)),
('scaling', StandardScaler())
])ה-pipeline להכנת העמודות המספריות ללמידה כולל 2 שלבים:
- imputation - להשלמת הנתונים החסרים בעמודות על ידי חציון median.
- סטנדרטיזציה כי אנחנו עובדים עם מודל של רגרסיה.
categorical_pipeline = Pipeline([
('categorical_imputation', SimpleImputer(strategy='constant', add_indicator=False, fill_value='missing')),
('one_hot_encoding', OneHotEncoder(sparse=False, handle_unknown='ignore'))
])ה-pipeline להכנת העמודות הקטגוריות ללמידה כולל 2 שלבים:
- imputation - השלמת הנתונים בדרך המתאימה לנתונים קטגוריים.
- קידוד one hot encoding.
כדי לשלב את שני ה-pipelines לתהליך אחד נשתמש ב-ColumnTransformer:
column_transformer = ColumnTransformer([
('numerical_preprocessing', numerical_pipeline, num_cols),
('categorical_preprocessing', categorical_pipeline, cat_cols)
], remainder='drop')- ה-ColumnTransformer משלב את ה-pipelines לפי סדר. ראשית, ה-pipeline לטיפול בעמודות המספריות. אחריו ה-pipeline של העמודות הקטגוריות.
- הפרמטר remainder מורה מה לעשות במקרה של עמודות שלא טופלו על ידי ה-ColumnTransformer. במקרה זה, ההוראה היא למחוק (drop).
אימון המודל
בשלב זה ניצור pipeline המשלב את צעדי ההכנה שעשינו בסעיף הקודם עם מודל. במקרה שלנו, המודל הוא רגרסיה ליניארית:
from sklearn import linear_model
pipe_preprocessing_model = Pipeline([
('preprocessing_step', column_transformer),
('model', linear_model.LinearRegression())
])נקרא למתודה fit על המידע הגולמי כדי שהשלבים יתבצעו לפי הסדר. העיבוד ואח"כ אימון הרגרסור:
pipe_preprocessing_model.fit(X_train, y_train)עכשיו שיש לנו מודל מאומן, אנחנו יכולים לבחון את הביצועים שלו על סט נתוני המבחן באמצעות המתודה predict:
y_pred = pipe_preprocessing_model.predict(X_test)
הערכת ביצועי המודל
נעריך את ביצועי המודל בעזרת מתודות של sklearn:
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error as mse
from sklearn.metrics import r2_score
from sklearn.metrics import mean_squared_error as mse
def score_model (y_test, y_pred, model_name):
MSE = mse(y_test, y_pred)
RMSE = np.sqrt(MSE)
R_squared = r2_score(y_test, y_pred)
print(f"
Model: {model_name} ,RMSE: {np.round(RMSE, 2)}, R-Squared: {np.round(R_squared, 2)}")score_model (y_test, y_pred, "linear_regression")Model: linear_regression ,RMSE: 2.24, R-Squared: 0.77
התמצאות במידע שמספק ה-pipeline
הבעיה עם sklearn שהרבה דברים קורים מתחת למכסה המנוע וקשה לקבל תחושה מה באמת קורה. בחלק זה נסביר כיצד לתאר חלק מהנתונים בתהליך.
איך נראות העמודות לאחר טרנספורציה? לשם כך, נעשה fit_transform על סט נתוני האימון ואת התוצאה נכניס לתוך DataFrame:
X_train_transformed = column_transformer.fit_transform(X_train)
pd.DataFrame(X_train_transformed).head()
מהם השלבים של ה-pipeline?
האפשרות הבאה תציג סכמות של התהליך:
from sklearn import set_config
set_config(display='diagram')pipe_preprocessing_model

- הסכמה מתארת את השלבים כולל עיבוד נפרד לנתונים הקטגוריים והמספריים ומודל שרץ בסוף.
אם אנחנו רוצים לחפור יותר לעומק אנחנו צריכים לדעת מה שמות השלבים באמצעות התכונה named_steps:
pipe_preprocessing_model.named_steps{'preprocessing_step': ColumnTransformer(transformers=[('numerical_preprocessing',
Pipeline(steps=[('numerical_imputation',
SimpleImputer(strategy='median')),
('scaling',
StandardScaler())]),
['age', 'Medu', 'Fedu', 'traveltime',
'studytime', 'failures', 'famrel', 'freetime',
'goout', 'Dalc', 'Walc', 'health', 'absences',
'G1', 'G2']),
('categorical_preprocessing',
Pipeline(steps=[('categorical_imputation',
SimpleImputer(fill_value='missing',
strategy='constant')),
('one_hot_encoding',
OneHotEncoder(handle_unknown='ignore',
sparse=False))]),
['school', 'sex', 'address', 'famsize',
'Pstatus', 'Mjob', 'Fjob', 'reason',
'guardian', 'schoolsup', 'famsup', 'paid',
'activities', 'nursery', 'higher', 'internet',
'romantic'])]),
'model': LinearRegression()}
- בגדול, יש לנו שני שלבים: preprocessing_step ו- model.
- ה-preprocessing_step מורכב משני טרנספורמרים: numerical_preprocessing ו- categorical_preprocessing.
נחפור יותר לעומק בתוך ה-preprocessing_step המורכב מטרנספורמרים:
pipe_preprocessing_model.named_steps['preprocessing_step'].transformers[('numerical_preprocessing',
Pipeline(steps=[('numerical_imputation', SimpleImputer(strategy='median')),
('scaling', StandardScaler())]),
['age',
'Medu',
'Fedu',
'traveltime',
'studytime',
'failures',
'famrel',
'freetime',
'goout',
'Dalc',
'Walc',
'health',
'absences',
'G1',
'G2']),
('categorical_preprocessing',
Pipeline(steps=[('categorical_imputation',
SimpleImputer(fill_value='missing', strategy='constant')),
('one_hot_encoding',
OneHotEncoder(handle_unknown='ignore', sparse=False))]),
['school',
'sex',
'address',
'famsize',
'Pstatus',
'Mjob',
'Fjob',
'reason',
'guardian',
'schoolsup',
'famsup',
'paid',
'activities',
'nursery',
'higher',
'internet',
'romantic'])]
- עכשיו אנחנו יודעים שיש לנו שני טרנספורמרים: numerical_preprocessing ו- categorical_preprocessing.
נחפור יותר לעומק לתוך הטרנספורמר numerical preprocessing:
pipe_preprocessing_model.named_steps['preprocessing_step'].named_transformers_['numerical_preprocessing']
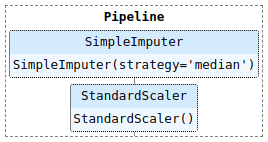
מה שמם של השלבים בתוך הטרנספורמר numerical preprocessing?
pipe_preprocessing_model.named_steps['preprocessing_step'].named_transformers_['numerical_preprocessing'].named_steps{'numerical_imputation': SimpleImputer(strategy='median'),
'scaling': StandardScaler()}
עכשיו כשאנחנו יודעים שיש לנו שלב ששמו numerical_imputation המשתמש במתודה של SimpleImputer אנחנו יכולים לברר לגביו פרטים (ע"ס התכונות והפרמטרים בתיעוד המתודה).
לדוגמה, מה ערך הפרמטר strategy?
pipe_preprocessing_model.named_steps['preprocessing_step'].named_transformers_['numerical_preprocessing'].named_steps['numerical_imputation'].strategy'median'
או מה הערכים שהמתודה מחליפה בהם את הנתונים החסרים עבור העמודות השונות?
pipe_preprocessing_model.named_steps['preprocessing_step'].named_transformers_['numerical_preprocessing'].named_steps['numerical_imputation'].statistics_array([17., 3., 2., 1., 2., 0., 4., 3., 3., 1., 2., 4., 4.,
11., 11.])
בחירת המודל
אפשר להשתמש באותו pipeline כדי להשוות את הביצועים של מודלים שונים.
נבחן את ביצועי ה-pipeline שפיתחנו במדריך על שלושה מודלים:
from sklearn import linear_model
from xgboost.sklearn import XGBRegressor
from sklearn.kernel_ridge import KernelRidge
models = [
linear_model.LinearRegression(),
XGBRegressor(objective="reg:squarederror",n_estimators=1000),
KernelRidge(alpha=1.0)
]נעריך את ביצועי המודל:
for model in models:
pipe_preprocessing_model = Pipeline([
('preprocessing_step', column_transformer),
('model', model)
])
pipe_preprocessing_model.fit(X_train, y_train)
y_pred = pipe_preprocessing_model.predict(X_test)
score_model (y_test, y_pred, model.__class__.__name__)Model: LinearRegression ,RMSE: 2.24, R-Squared: 0.77 Model: XGBRegressor ,RMSE: 2.11, R-Squared: 0.8 Model: KernelRidge ,RMSE: 2.24, R-Squared: 0.77
- נראה ש-XGBoost הוא המוצלח מבין השלושה.
ניצור מהמודל XGBoost את ה-pipeline הנבחר:
selected_model = XGBRegressor(objective="reg:squarederror",n_estimators=1000)
pipe_selected_model = Pipeline([
('preprocessing_step', column_transformer),
('model', selected_model)
])
pipe_selected_model.fit(X_train, y_train)- צריך לשים לב, שלבי העיבוד עבור מודל XGBoost שונים מהמתואר במדריך אבל לא נכנסתי לזה כדי לפשט. לקריאת מדריך המוקדש ספציפית ל-XGBoost.
יצוא ויבוא המודל
עמלנו קשות ועכשיו הגיע הזמן לשמור את העבודה שלנו. כי אולי נרצה לחזור אליה בעתיד או שאנחנו מעוניינים לפרוס את המודל לשימוש הלקוח שהזמין את העבודה.
נשמור את המודל הנבחר באמצעות joblib:
import joblib
joblib.dump(pipe_selected_model, 'pipeline.pkl')['pipeline.pkl']
עכשיו אנחנו יכולים לטעון את המודל:
loaded_pipeline = joblib.load('pipeline.pkl')נעריך את ביצועיו:
y_pred = loaded_pipeline.predict(X_test)
score_model(y_test, y_pred, 'loaded_model')Model: loaded_model ,RMSE: 2.11, R-Squared: 0.8
סיכום
pipeline מאפשר לשרשר לפי סדר את השלבים של הכנת הנתונים ללמידת מכונה עם הרצת המודל. כאשר השלב של הרצת המודל הוא לא הכרחי אבל אם מוסיפים אותו הוא חייב להיות האחרון בשרשרת.
היתרונות של שימוש ב-pipeline כוללים:
- נוחות - אפשר להשתמש באותו סדר של פעולות על סטים שונים של נתונים (אימון, מבחן, נתונים שמגיעים ממשתמשים) בלי לשכפל קוד.
- אפשר לבחור בקלות יחסית את המודל. לפי אותו היגיון, אפשר להשתמש ב-pipeline לבחירת הפרמטרים בשביל מודל.
- מניעת דליפת מידע data leakage מסט נתוני המבחן לנתוני האימון.
להורדת הקוד אותו פיתחנו במדריך
גם זה יעניין אותך
מודלים ללמידת מכונה של SciKit-Learn
חיזוי מחירי מכוניות - XGBoost, Optuna, SHAP, ועוד הרבה דברים טובים...
בחירת התכונות (feature selection) עבור מודל למידת מכונה
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.