
חיזוי טמפרטורות בעזרת RNN וספריית PyTorch
חיזוי סדרות נתונים מציב אתגר משמעותי בפני למידת מכונה בגלל שהמחשב צריך לזכור את תוצאות השלבים הקודמים של תהליך הלמידה מה שרשת נוירונית רגילה feed forward network לא יודעת לעשות. אחת הדרכים הוותיקות לטפל בבעיה היא באמצעות רשתות מסוג RNN - Recurrent Neural Networks.
ברשת נוירונית שמיישמת ארכיטקטורת RNN לכל יחידה cell יש מצב state המאפשר לזכור מידע שמקורו בשלבים קודמים בתהליך הלמידה.
RNN יכול לשמש למשימות שדורשות עבודה עם רצפים. כדוגמת, שפה שמורכבת מרצף של מילים, סרטונים שעשויים מרצף של פריימים או מידע התלוי בחילופי העיתים, מחזורי שפל וגאות כלכלית או מחזור כתמי השמש.
Andrej Karpathy מזכיר מספר שימושים בפוסט הקלאסי שלו The unreasonable effectiveness of recurrent neural networks, ובדרך הוא גם מסווג את סוגי הבעיות על פי הרכב הקלט והפלט. במסגרת זו הוא מונה 3 סוגים:
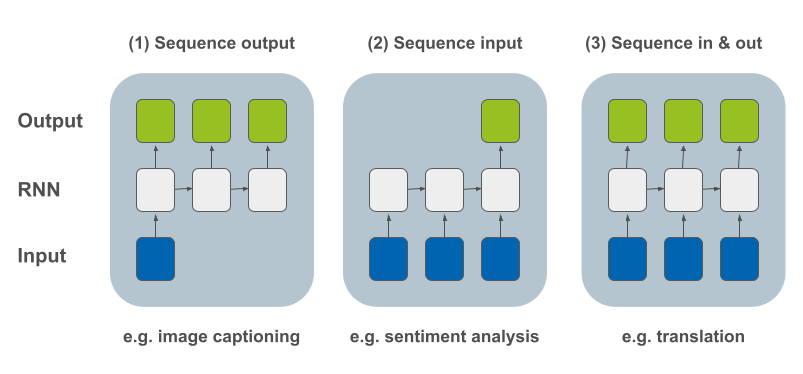
פלט שהוא רצף - לדוגמה, הוספת כיתוב לתמונה. על כל קלט יחיד (תמונה) המחשב מייצר משפט (רצף מילים) המתאר מה בתמונה.
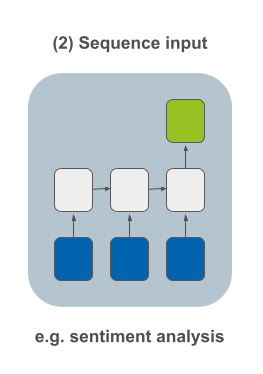
קלט שהוא רצף - לדוגמה, אנליזת סנטימנט שנותנת למחשב להחליט האם ביקורת על סרט (רצף מילים) היא חיובית או שלילית.
רצף בקלט ובפלט - לדוגמה, תרגום של משפט משפה אחת לאחרת.
הבנה מה מבנה הפלט והקלט תהיה חשובה לנו בהמשך כשנבנה את המודל כיוון שקושי עיקרי הוא להחליט מה הצורה של הטנזורים אותם הרשת הנוירונית קולטת, מעבדת, ומחזירה.
מטרת המדריך
במדריך זה נפתח מודל לחיזוי הטמפרטורות בשנים 2019 - 2021 על סמך נתוני השנים 2007 - 2018. על הדרך נלמד לעבוד עם RNN במסגרת ספריית PyTorch.
להורדת הקוד המלא ומסד הנתונים של המדריך חיזוי טמפרטורות באמצעות RNN וספריית PyTorch
סביבת העבודה וייבוא הספריות
את המדריך פיתחתי בתוך סביבה וירטואלית של פייתון על המחשב האישי ללא GPU.
התחלתי מייבוא הספריות הבסיסיות:
# working with multidimensional arrays
import numpy as np
# for dataframes
import pandas as pd
# plotting library
import matplotlib.pyplot as plt
# machine learning framework
import torch- Numpy מבצעת חישובים מתמטיים ומקלה על העבודה עם מערכים רב ממדיים.
- Pandas - מאפשרת לעבוד עם מידע במסגרת נוחה של dataframes.
- Matplotlib להצגת גרפים ותרשימים.
- נשתמש בספריית PyTorch לפיתוח מודל למידת מכונה מבוסס ארכיטקטורת RNN.
נגדיר את המעבד שאיתו אנחנו עובדים:
# device config
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')- אין צורך ב-GPU.
מסד הנתונים
את מאגר הנתונים של טמפרטורות מקסימום יומיות בנמל אשדוד בין השנים 2007 ל-2022 הורדתי מאתר השירות המטאורולוגי הישראלי https://ims.data.gov.il/ims/1.
נטען את קובץ הנתונים ל-dataframe של Pandas:
# loading the dataset
df = pd.read_csv('./data/ims/temp.csv')נציץ ב-5 השורות הראשונות:
df.head()
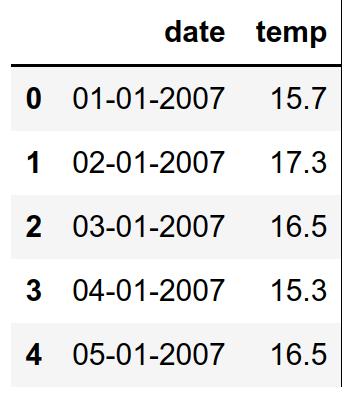
- לכל יום ערך יחיד של טמפרטורה שיא שנמדדה בו.
- התאריכים אינם תואמים את סוג הנתונים date המאפשר לעבוד עם סדרות זמן של נתונים. את זה נצטרך לתקן.
הכנת הנתונים ללמידת מכונה
נפרמט את התאריכים כדי שיתאימו לסוג הנתונים date:
def to_international_date(d):
date = d.split('-')
day = date[0]
month = date[1]
year = date[2]
return '%s-%s-%s' % (year, month, day)
# convert to date data type
df['date'] = df['date'].apply(to_international_date)
# convert to datetime
df['datetime'] = pd.to_datetime(df['date'])
# drop the original column
df = df.drop(['date'], axis=1)ננקה את הנתונים החסרים מעמודת הטמפרטורה, ונמיר את סוג הנתונים ל-float:
# clean the missing values
df = df[df['temp'] != '-']
# set the type of temp to float
df['temp'] = df['temp'].astype(float)נהפוך את העמודה שיצרנו זה עתה, datetime לאינדקס ה-dataframe:
# set the index
df = df.set_index('datetime')כדי שנוכל לגשת לנתוני הטמפרטורה על סמך תאריך. לדוגמה:
df.loc['2018-12-31']temp 17.8 Name: 2018-12-31 00:00:00, dtype: float64
הטמפרטורות המרביות מסודרות על ציר הזמן. נשתמש ב-matplotlib כדי להציג סדרות זמן של נתונים. הפונקציה הבאה תאפשר לנו לשמור על אחידות הצגת הנתונים במדריך:
# matplotlib settings
plt.style.use('seaborn')
params = {'figure.figsize': (36, 27),
'font.size': 24,
'axes.titlesize':'xx-large',
'axes.labelsize': 'large',
'xtick.labelsize': 'medium',
'ytick.labelsize': 'medium'}
from matplotlib import dates as mpl_dates
def plot_dataset(df1, df2=None, labels=[], title='temperatures over time', reset_index=True):
plt.rcParams.update(params)
if reset_index:
df1 = df1.reset_index()
plt.title(title)
plt.xlabel('date')
plt.ylabel('temp')
plt.plot_date(df1['datetime'], df1['temp'], linestyle='solid', color='#163561')
try:
if df2 is not None:
if reset_index:
df2 = df2.reset_index()
plt.plot_date(df2['datetime'], df2['temp'], linestyle='solid', color='#97c022')
except Exception as e:
print(e)
if labels:
plt.legend(labels, loc="lower left", prop={'size': 36})
plt.gcf().autofmt_xdate() # gcf() - get current figure
date_format = mpl_dates.DateFormatter('%b, %d %Y') # python strftime
plt.gca().xaxis.set_major_formatter(date_format) # gca() - get current axisנשתמש בפונקציה להצגת הנתונים:
plot_dataset(df)
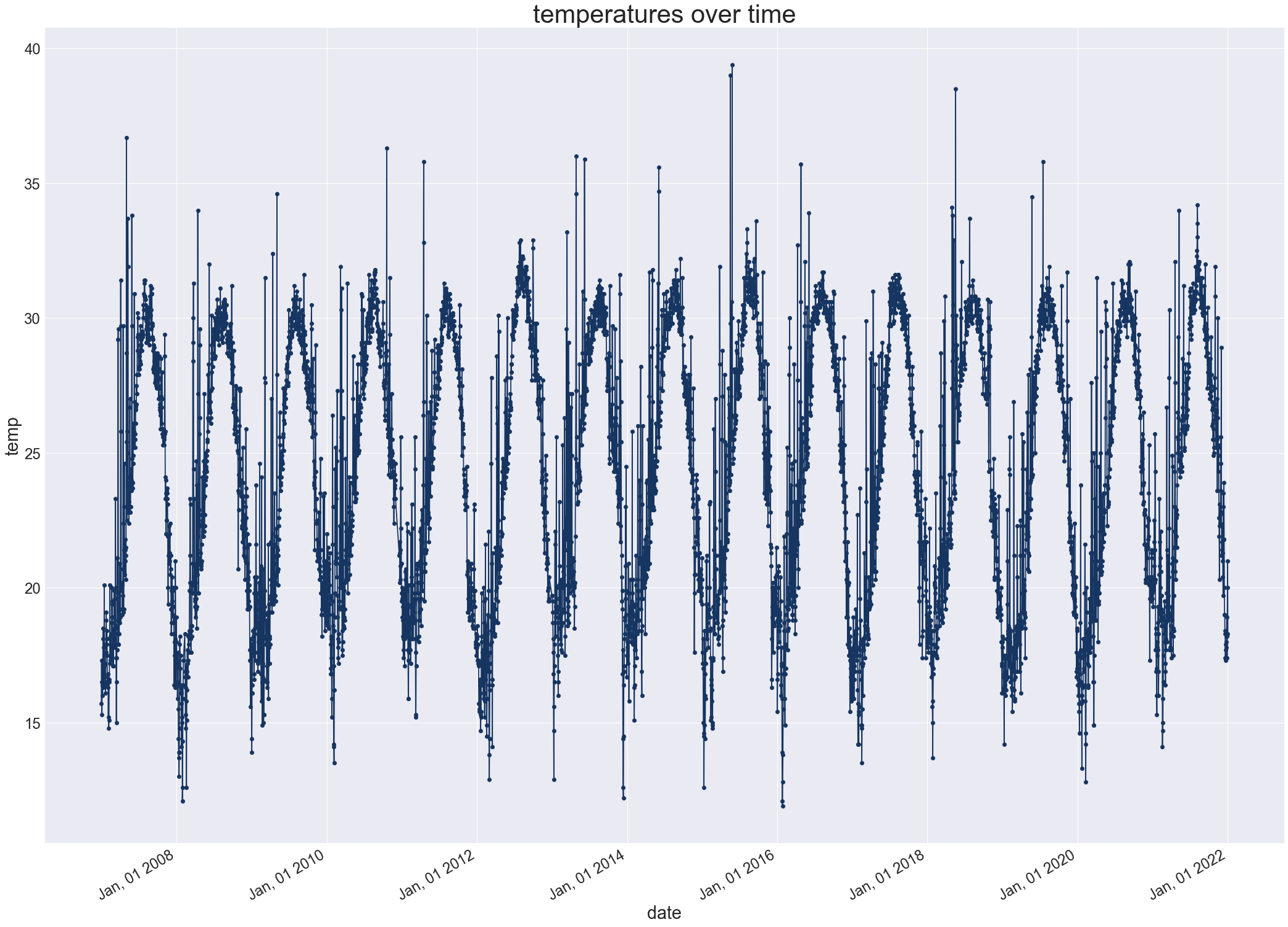
- ערכי הטמפרטורה והמחזוריות שלהם מתאימים לאקלים הממוזג של אזור החוף בישראל.
מה בנוגע לסטטיסטיקה של טמפרטורות השיא:
df.describe()| temp | |
|---|---|
| count | 5410.000000 |
| mean | 24.440166 |
| std | 4.922643 |
| min | 11.9000 |
| 25% | 19.900 |
| 50% | 24.8000 |
| 75% | 29.1000 |
| max | 39.4000 |
נלמד עוד כמה פרטים מעניינים על מסד הנתונים:
print(df)| temp | |
|---|---|
| datetime | |
| 2007-01-01 | 15.7 |
| 2007-01-02 | 17.3 |
| 2007-01-03 | 16.5 |
| 2007-01-04 | 15.3 |
| 2007-01-05 | 16.5 |
| ... | ... |
| 2021-12-28 | 18.2 |
| 2021-12-29 | 17.4 |
| 2021-12-30 | 20.0 |
| 2021-12-31 | 21.0 |
| 2022-01-01 | 18.3 |
5410 rows × 1 columns
- סה"כ 5410 נתונים: תחילתם ב-01.01.2007 והם מסתיימים ב-01.01.2022
print(df.shape)
df.info()DatetimeIndex: 5410 entries, 2007-01-01 to 2022-01-01 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 temp 5410 non-null float64 dtypes: float64(1) memory usage: 213.6 KB
- לא חסרים נתונים. סה"כ 5410 ערכי טמפרטורה מסוג float.
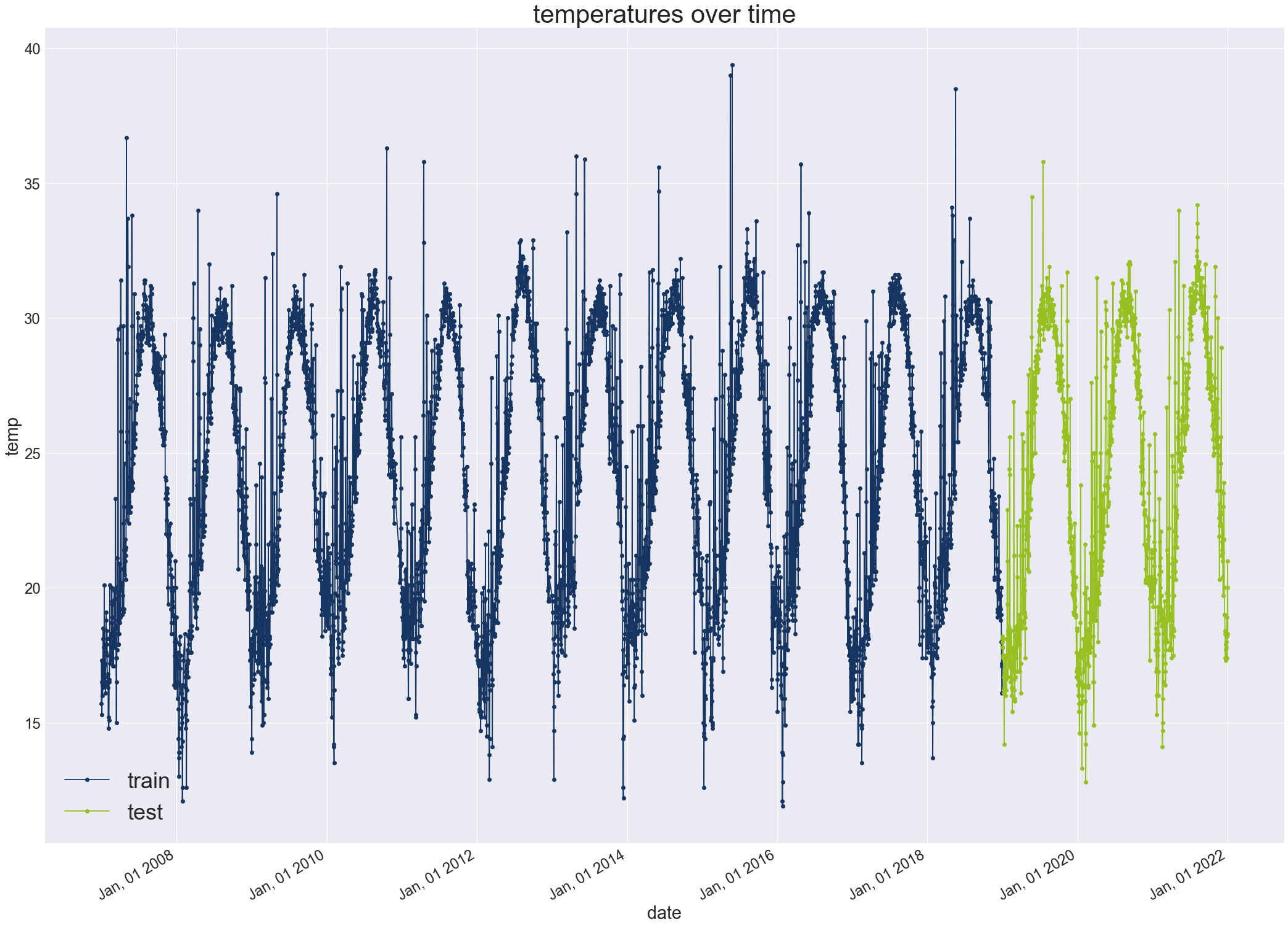
נפריד את מסד הנתונים לשניים. סט אימון שיכלול את הנתונים שנאספו בין 01.01.2007 ל-31.12.2018. סט מבחן שיכלול את סדרת הנתונים המאוחרים יותר בין התאריכים 01.01.2019 ל-01.01.2022:
# separate into train and test datasets
# it is crucial to maintain the right order
# so do not shuffle
from datetime import datetime
split_date = datetime(2018,12,31)
dataset_train = df[:split_date]
dataset_test = df[split_date:]- שמירה על סדר הנתונים הינה מהותית כשעובדים עם סדרות זמן ועל כן נקפיד לא לערבב באקראי shuffle.
נתאר את הנתונים לאחר ההפרדה:
נורמליזציה של הנתונים משפרת את דיוק ומהירות ההתכנסות של מודלים לכן נקפיד להשתמש בה, כל עוד אין לנו סיבה טובה להימנע מכך. במקרה זה, אני משתמש בפונקציה MinMaxScaler של sklearn כדי לנרמל את הנתונים לערכים שבין 0 ל-1:
# scaling the data is helfpful (most of times)
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
dataset_train_scaled = scaler.fit_transform(dataset_train)
dataset_test_scaled = scaler.transform(dataset_test)- הפונקציה MinMaxScaler לומדת את ערכי המינימום והמקסימום מסט נתוני האימון ואח"כ היא מנרמלת אותם.
- הפונקציה מיישמת את מה שלמדה מסט האימון כשהיא מנרמלת את סט המבחן.
נציץ במה שעשינו:
print(dataset_test_scaled[-5:]) # the last data points[[0.22909091] [0.2 ] [0.29454545] [0.33090909] [0.23272727]]
לפני שנוכל להמשיך אנחנו צריכים להבין את הצורה של הקלט והפלט אותם נזין למודל. במקרה שלנו, נשתמש בנתוני טמפרטורה של X ימים רצופים כדי לחזות את הטמפרטורה של היום הבא ברצף X+1 מה שקראנו לו "קלט שהוא רצף" במבוא למדריך.
מכיוון שרצף הימים הוא ארוך (מאות ואף אלפים) ו-X בהכרח קצר יותר (30) נשתמש בטכניקה של "חלון מתגלגל" rolling window. "חלון" בגלל שהאורך X נשאר קבוע, ו-"מתגלגל" בגלל שנחזור על הפעולה כמה פעמים שצריך עד שניצור מספיק סדרות של רצפים והערך שבא מיד אחריהם שיצליחו לכסות את כל הרצף המקורי.
בלמידת מכונה, ה-features משמשים כדי לחזות את ה-labels. במקרה שלנו, ה-features הם רצף של 30 ימים וה-label הוא הערך שבא מיד אחרי הרצף. בטכניקה rolling window נשתמש כדי לייצר את ה-features וה-labels.
לפני שנציג את הפונקציה שתפעיל בשבילנו את ה-rolling window נדגים את פעולתה באמצעות דוגמה פשוטה. נפעיל פונקצית rolling window שתייצר רצפים באורך 3 פריטים מרצף של 7 מספרים 1 עד 7:
[1, 2, 3, 4, 5, 6, 7]
האלגוריתם rolling window יהפוך את הרצף היחיד באורך 7 פריטים ל-4 פריטים קצרים באורך של 3 כל אחד:
| features | label |
|---|---|
| [1, 2, 3] | 4 |
| [2, 3, 4] | 5 |
| [3, 4, 5] | 6 |
| [4, 5, 6] | 7 |
את הפונקציה make_rolling_window_dataset נזין במסדי הנתונים שיצרנו (אימון ומבחן) על מנת שהיא תפריד מתוכם את ה- features וה-labels כאשר סט של 30 מדידות רצופות ישמש לחיזוי המדידה הבאה. הסט של 30 המדידות יהיה features והערך הבא בתור יהיה label שאותו המודל צריך לחזות:
def make_rolling_window_dataset(base_dataset, n_time_points):
features = []
labels = []
for i in range(n_time_points, len(base_dataset)):
# features from the previous N time points
X = base_dataset[i-n_time_points:i]
X = X.T
# label from the current time point
y = base_dataset[i]
# append to the arrays
features.append(X)
labels.append(y)
return np.array(features), np.array(labels)נפעיל את הפונקציה על סט נתוני האימון והמבחן:
# take a series of 30 time points as features
# and the next point as a label
# repeat as much as needed
n_time_points = 30
X_train, y_train = make_rolling_window_dataset(dataset_train_scaled, n_time_points)
X_test, y_test = make_rolling_window_dataset(dataset_test_scaled, n_time_points)
כשעובדים עם PyTorch מחזיקים את מסד הנתונים בתוך קלאס מסוג Dataset. כל Dataset מופקד על טיפול ברשימה list בה כל פריט הוא tuple המורכב מפיצ'רים ותגיות (features and labels). הרחבתי על נושא קלאס ה- Dataset במדריך רגרסיה קווית באמצעות PyTorch אותו מומלץ לקרוא כדי להבין טוב יותר כיצד לעבוד עם הספרייה.
ניישם את הקלאס Dataset פעמיים. עבור מסדי הנתונים של אימון ומבחן:
# create train and test datasets based on a PyTorch class
from torch.utils.data import Dataset
class TrainDataset(Dataset):
def __init__(self):
# data loading
self.data = torch.FloatTensor(X_train)
self.labels = torch.FloatTensor(y_train)
def __getitem__(self, index):
# dataset[index] to get the index-th item
return self.data[index], self.labels[index]
def __len__(self):
# size of dataset
return len(self.labels)
class TestDataset(Dataset):
def __init__(self):
# data loading
self.data = torch.FloatTensor(X_test)
self.labels = torch.FloatTensor(y_test)
def __getitem__(self, index):
# dataset[index] to get the index-th item
return self.data[index], self.labels[index]
def __len__(self):
# size of dataset
return len(self.labels)נאתחל את מסדי הנתונים:
# initialize the datasets
train_dataset = TrainDataset()
test_dataset = TestDataset()הקלאסים מחזיקים רשימה של טופלים. כל טופל מורכב מסידרה של 30 features ו-label 1.
#print(train_dataset[0])
print(train_dataset[0][0].shape)
print(train_dataset[0][1].shape)torch.Size([1, 30]) torch.Size([1])
לרוב, מסדי הנתונים הם גדולים מכדי שמחשב יוכל לעבד אותם בבת אחת. לכן נפעיל את המודל על מספר מצומצם של דוגמאות בכל פעם תוך שימוש באצוות קטנות mini-batch. בכל סיבוב של למידת מכונה epoch נוסיף לולאה שמריצה בכל פעם כמות מצומצמת של דוגמאות מתוך כל הדוגמאות. הלולאה תרוץ כמה פעמים שצריך עד להרצת כל הדוגמאות בכל epoch. יתרון חשוב של שימוש ב- DataLoader הינו היכולת לערבב את הנתונים. במקרה שלנו אסור לערבב כי הנתונים מבוססים על סדרת זמן ועל כן הסדר הוא מהותי. נעזר בקלאס DataLoader של PyTorch שייצר למעננו את ה mini-batches באצוות של 100 דוגמאות:
from torch.utils.data import DataLoader
batch_size = 100
# call the DataLoader to get mini-batches
# for each dataset
# do not shuffle since it is based on time
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=False)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)- יצרנו שני אינסטנסים של DataLoader. אחד עבור נתוני האימון והשני עבור המבחן.
להורדת הקוד המלא ומסד הנתונים של המדריך חיזוי טמפרטורות באמצעות RNN וספריית PyTorch
בניית והרצת מודל למידת מכונה מסוג RNN באמצעות PyTorch
הסברתי כבר במדריך קודם את הנושא של למידת מכונה באמצעות PyTorch, ולכן אדלג על ההסברים המפורטים.
מודל ה-PyTorch לחיזוי טמפרטורות כולל שתי שכבות RNN שתפקידם לקלוט ולעבד את רצף הטמפרטורות באמצעות 48 נוירונים. השכבה האחרונה היא לינארית ומחזירה ערך יחיד, הטמפרטורה החזויה ביום שאחרי סדרת הנתונים שהיא מקבלת כקלט.
import torch.nn as nn
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# batch first - because the shape starts with it
self.rnn = nn.RNN(input_size,
hidden_size,
num_layers,
batch_first=False)
# only 1 output
self.fc = nn.Linear(hidden_size*sequence_length, 1)
def forward(self, x):
# initialize hidden layer with zeros
h0 = torch.zeros(self.num_layers, self.hidden_size).to(device)
# forward propagation
out, _ = self.rnn(x, h0)
out = out.reshape(out.shape[0], -1)
out = self.fc(out)
return outנאתחל את קלאס המודל עם הפרמטרים:
input_size = n_time_points # 30
sequence_length = 1
num_layers = 2
hidden_size = 48
model = RNN(input_size, hidden_size, num_layers).to(device)הבעיה היא בעיית רגרסיה כי המודל חוזה ערך יחיד. לפיכך, נשתמש בפונקציית loss המעריכה את ביצועי המודל על פי ממוצע ריבוע ההפרש בין ניבויי המודל לערכי האמת בשיטת MSE - Mean Square Error :
# for regression problems (1 output) use the loss function MSELoss
# that computes the Mean Squared Error(MSE)
# between the real labels and predictions
loss_fn = nn.MSELoss()Adam היא פונקצית אופטימיזציה אדפטיבית מאוד פופולרית. פה אני משתמש בה עם קצב למידה 0.001:
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
אחרי שהגדרנו את כל מה שאנחנו צריכים כדי לאמן את המודל, נשתמש בקוד הבא כדי להריץ את המודל במשך 5 epochs:
# to have a progress bar
from tqdm import tqdm
# train the network
num_epochs = 5
for epoch in range(num_epochs):
for batch_idx, (data, targets) in enumerate(tqdm(train_loader)):
# get data to cuda (if available)
data = data.to(device=device).squeeze(1)
targets = targets.to(device=device)
# forward
scores = model(data)
loss = loss_fn(scores, targets)
# backward
optimizer.zero_grad()
loss.backward()
# gradient descent update step/adam step
optimizer.step()
הערכת ביצועי המודל
הפונקציה evaluate() תאפשר לנו לקבל את רשימת תחזיות המודל עבור הנתונים שנעביר לתוכה:
def evaluate(loader, model):
output = np.array([])
# set model to eval
model.eval()
with torch.no_grad():
for x, y in loader:
x = x.to(device=device).squeeze(1)
y = y.to(device=device)
predictions = model(x)
# convert the scaled data back to the original values
rescaled = scaler.inverse_transform(predictions).squeeze()
# stack rows together
output = np.hstack((output, rescaled))
return output- הפונקציה מקבלת data loader של מסד הנתונים, ומעבירה למודל. את ניבויי המודל היא מחזירה לקנה המידה המקורי, זה שהיה לפני הנרמול באמצעות MinMaxScaler, את התוצאות היא אוספת לרשימת טמפרטורות חזויות אותה היא מחזירה.
לפני שנבקש מהפונקציה לחזות את הטמפרטורות של סט המבחן, נבדוק את התחזיות עבור קבוצת האימון:
train_predictions = evaluate(train_loader, model)הקוד הבא יאפשר לנו לתאר בגרף את הטמפרטורות החזויות (בירוק) על רקע טמפרטורות האמת:
# visualize the predicted values against the actual data
# but first we need to scale back to the actual data
# pop the first 30 values from the timeseries
x_axis = dataset_train.index[n_time_points:]
# make dataframes
actual_train_rescaled_df = pd.DataFrame({'datetime':x_axis, 'temp':np.squeeze(actual_train_rescaled)})
train_predictions_df = pd.DataFrame({'datetime':x_axis, 'temp':np.squeeze(train_predictions)})
# plot
plot_title = 'Actual vs predicted in the train dataset'
labels = ['actual', 'predicted']
plot_dataset(actual_train_rescaled_df, train_predictions_df, labels, plot_title, False)
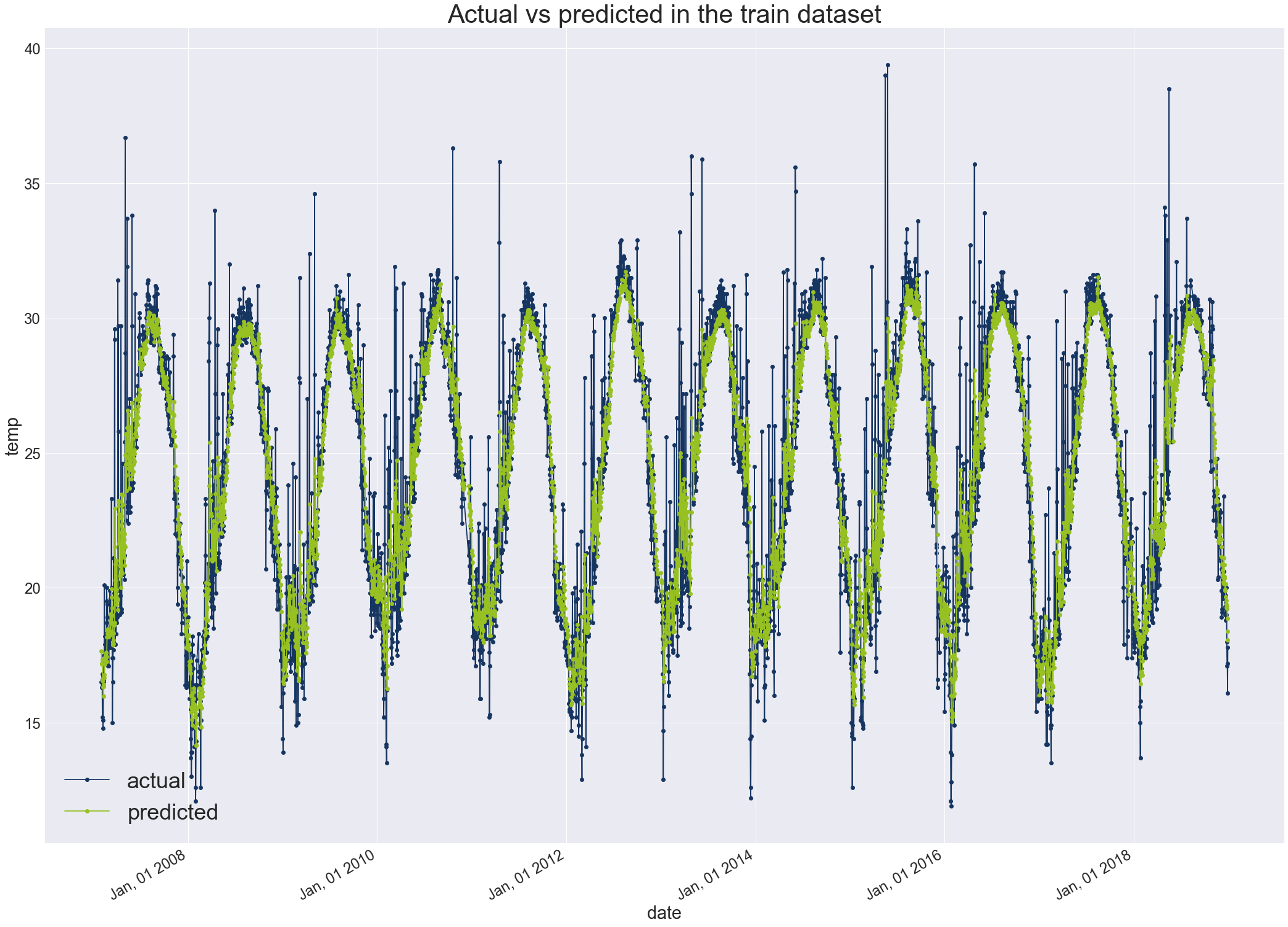
- המודל מצליח לשחזר את המגמה של חילופי העונות. עם ערכים גבוהים בחודשי הקיץ ונמוכים בחורף. הוא יותר מתקשה עם אירועי קיצון בהם הטמפרטורות גבוהות או נמוכות באופן חריג.
מה שיעור הסטייה בין הערכים החזויים והערכים בפועל?
import math
from sklearn.metrics import mean_squared_error
# calculate root mean squared error for the train data
train_score = math.sqrt(mean_squared_error(actual_train_rescaled, train_predictions))
print('Train Score: %.2f RMSE' % (train_score))Train Score: 1.96 RMSE
- ממוצע ריבוע השגיאה Root Mean Square Error הוא פחות מ-2 מעלות במודל מאוד פשוט שלא עשיתי לו אופטימיזציה.
נעריך את קבוצת המבחן באופן דומה:
test_predictions = evaluate(test_loader, model)# visualize the predicted values against the actual data
# but first we need to scale back to the actual data
actual_test_rescaled = scaler.inverse_transform(y_test.reshape(-1, 1))
# pop the first 30 values from the timeseries
x_axis = dataset_test.index[n_time_points:]
# make dataframes
actual_test_rescaled_df = pd.DataFrame({'datetime':x_axis, 'temp':np.squeeze(actual_test_rescaled)})
test_predictions_df = pd.DataFrame({'datetime':x_axis, 'temp':np.squeeze(test_predictions)})
# plot
plot_title = 'Actual vs predicted in the test dataset'
labels = ['actual', 'predicted']
plot_dataset(actual_test_rescaled_df, test_predictions_df, labels, plot_title, False)
# calculate root mean squared error for the test data
test_score = math.sqrt(mean_squared_error(actual_test_rescaled, test_predictions))
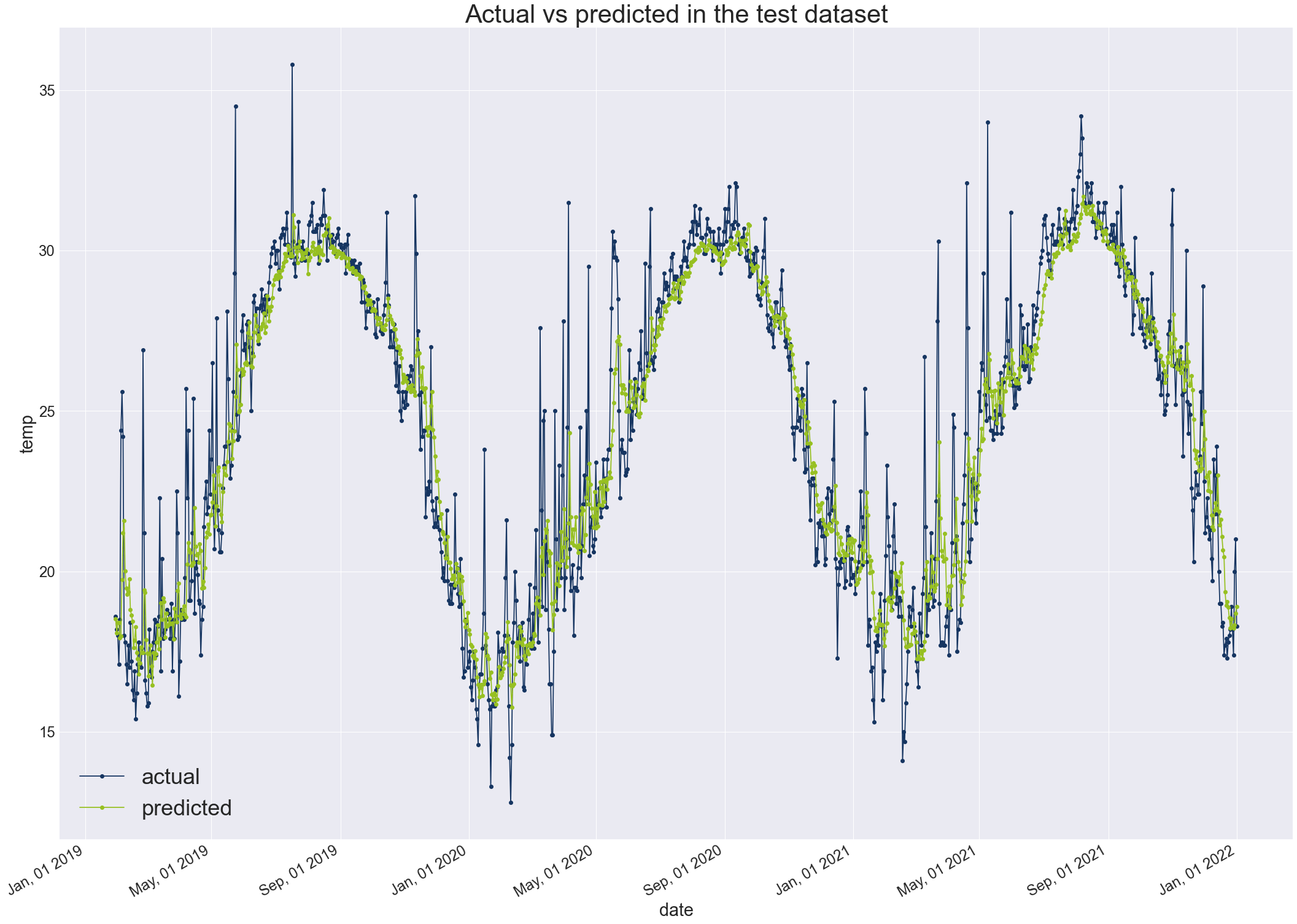
print('Train Score: %.2f RMSE' % (test_score))- בחודשי המעבר המודל נוטה להראות קפיצות גדולות יותר בהתאמה עם המציאות של שינוי מהיר בטמפרטורות. אבל בכל מקרה, המודל נוטה להיות שמרני יותר מהמציאות. יכול להיות שזה בגלל שהוא עושה סוג של ממוצע שלוקח בחשבון 30 יום בכל פעם. אם זה המצב אולי קיצור של חלון הזמן מ-30 יום יוכל לשפר את הביצועים.
Train Score: 1.84 RMSE
- נראה שהמודל מדייק יותר בחיזוי הטמפרטורות בנתוני קבוצת המבחן. זו תופעה שבדרך כלל לא אמורה לקרות. אבל במקרה שלנו אפשר לנסות ולתרץ בכך שנתוני הטמפרטורות נראים יציבים יותר ב-3 השנים האחרונות של המדידה. אפשרות חלופית, היא שבתקופת הזמן הקצרה יותר של נתוני המבחן לעומת נתוני האימון (3 שנים לעומת 11) קרו מספר קטן יותר של אירועי קיצון אקלימיים.
להורדת הקוד המלא ומסד הנתונים של המדריך חיזוי טמפרטורות באמצעות RNN וספריית PyTorch
אולי גם זה יעניין אותך
רגרסיה קווית להערכת מחירי דירות באמצעות PyTorch ולמידת מכונה
סיווג תמונות באמצעות למידת מכונה מבוססת PyTorch
סיווג בינארי עם PyTorch - מתי ואיך
חיזוי טמפרטורות באמצעות למידת מכונה וספריית TensorFlow
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.