
ניתוח סנטימנט - הבנת רגשות ההמון באמצעות בינה מלאכותית
מערכות בינה מלאכותית הגיעו לשלב שבו הם יכולות להבין את כוונת האדם על סמך טקסט שכתב באמצעות ניתוח סנטימנט sentiment analysis מה שיכול לעזור למפרסמים ומשווקים שרוצים לדעת מה רוצה ההמון כדי לעשות מזה הון. במדריך זה נערוך ניתוח סנטימנט כדי לחוש את רגשות הציבור על סמך תגובות גולשים באתר. במסגרת המדריך, נכיר את עולם עיבוד שפות אנוש על ידי מחשבים, NLP, נגרד תגובות מדף אינטרנט, ונערוך ניתוח סנטימנט באמצעות מודל BERT מתקדם.

הבנת שפות אנוש על ידי מחשבים NLP
התחום של למידת מכונה תופס תאוצה בשנים האחרונות לא מעט הודות לטכנולוגית Transformer אשר הומצאה ב-2017 על ידי גוגל כדי לאפשר למחשבים לעבוד עם שפה אנושית אך הוכחה כיעילה למגוון שימושים, דוגמת: תרגום, הבנת שפה אנושית, יצירת תמונות, ואפילו פענוח מבנים מולקולריים.
טכנולוגיות ישנות יותר ניסו ללמד מחשבים לעבוד עם שפה אנושית באמצעות רשתות נוירונים חוזרות RNN אבל הניסיון הראה שהמערכות לומדות לאט מדי, אינן עירות להקשר, ונוטות לשכחה עם התארכות רצף המילים.
כל הטכנולוגיות לעבודה עם שפה אנושית משתמשות בוקטורים מספריים המייצגים מילים בגלל שמחשבים יודעים לעבוד עם מספרים ולא עם מילים. word embedding היא טכנולוגיה הממפה מילים לווקטורים מספריים בתהליך המכונה וקטוריזציה. אתגר חשוב בתהליך הוקטוריזציה הוא שמירה על המשמעות הסמנטית של מילים. לדוגמה, שהמחשב יבין שהמילה "מלך" קרוב יותר למילה "מלכה" מאשר למילה "צב". לשם כך, הומצא אלגוריתם word2vec שעושה וקטוריזציה תוך שמירת המשמעות הסמנטית.
עניין עקרוני בקידוד טקסטים לוקטורים הוא לאיזה מילים וחלקי דיבור יש לתת משקל גבוה יותר. כדי להתמודד עם הבעיה פותחו מערכות attention באמצעותם המחשב לומד בעצמו לאיזה חלק של המשפט עליו לשים לב.
בתחילה, מערכות attention שולבו עם רשתות RNN אבל אז פרץ לחיינו הטרנספורמר שהחליף את מערכות ה-RNN במערכות self-attention. הטרנספורמר מאיץ את הלמידה, בין השאר, על ידי כך שהוא מנצל את היכולת לחישוב מקבילי של מחשבים מודרניים Multi-Head attention. הטרנספורמר לומד את כל הטקסט כחטיבה אחת במקום לחלק לרצפים מה שפותר את הבעיה של "שכחה" ברצפים ארוכים, ושל הבנת המילים בהקשר המשפט (לדוגמה, המילה "חלונות" יכולה להתייחס למערכת הפעלה או לחלון הבית).
בעיה עיקרית של מערכות ממוחשבות היא כמות האנרגיה והמאמץ שיש להשקיע בפיתוח המודל. כדי לפתור את הבעיה גוגל שחררה את BERT - מודל מאומן pre-trained model שחוסך מאיתנו את הצורך ללמד את המחשב בכל פעם מחדש. מה שאנחנו צריכים הוא להוריד את המודל המאומן ולהתאים אותו לצרכים שלנו. כולל: תרגום טקסט, תשובות לשאלות, סיכום טקסט, וניתוח סנטימנט.
חוץ מ-BERT קיימים כמה מאות טרנספורמרים, מתוכם בולטים: GPT של OpenAI המייצר טקסט ברמה חסרת תקדים, עונה על שאלות ומסכם טקסטים, DELL-E ליצירת תמונות על פי משפטים, Alpha Fold של DeepMind לחיזוי המבנה התלת מימדי של חלבונים, ואולי המרשים שבהם, FLAMINGO שמאפשר למכונה להסיק ממספר קטן של דוגמאות בדומה ללמידה אנושית.

תמונה של אסטרונאוט רוכב על סוס על פני הירח שיצר מודל DALL-E 2 מתוך הפוסט שפרסמה OpenAI
גם המעצמה הטכנולוגית הקרויה ישראל אינה טומנת ידה בצלחת ומעבדות AI21 מתל אביב שחררו את המודל Jurassic העולה בהיבטים מסוימים על יכולות המודל GPT-3. ניתן לנסות את המערכת בחינם (לחץ כדי להשתעשע עם Jurassic).
ספריית transformers של Hugging Face מספקת ממשק אחיד, API, לעבודה עם טרנספורמרים. הספרייה ענקית מה שעלול לבלבל. לכן אני ממליץ להתחיל מדף תיאורי המקרה בכתובת: https://huggingface.co/transformers/usage.html. בדף ניתן למצוא דוגמאות שימוש לסיווג טקסטים, תשובות לשאלות, מודלים של שפה, תרגום ויצירת טקסט.
במדריך זה אדגים ניתוח סנטימנט באמצעות מודל BERT מאומן מראש איתו נעבוד באמצעות הממשק של hugging face.
ניתוח סנטימנט (sentiment analysis) הוא תחום של עיבוד שפה אנושית (Natural Language Processing) אשר משתמש במחשבים כדי להסיק את הרגש של בני אדם מהטקסט שהם כותבים. שימוש בניתוח סנטימנט ברשתות חברתיות, בפורומים ובדפי תגובות יכול לסייע בהבנת רגשות הציבור היות ואנשים מרשים לעצמם לכתוב את אשר על ליבם כשהם מוגנים מאחורי המקלדת, וכך הם עשויים לחשוף את מה שהם באמת חושבים. בנוסף, מחשבים מאפשרים לנתח כמות אדירה של מידע מה שעוזר עם הסטטיסטיקה.
גירוד הנתונים מהאינטרנט
גירוד דפי אינטרנט היא טכנולוגיה המאפשרת לנו להעתיק את תוכנם של דפי אינטרנט ומקורות מידע ברשת למחשבים שלנו.
שימו לב! גירוד דפי רשת נחשב לשנוי במחלוקת ועלול לגרום לבעיות משפטיות וטכניות. לכן, לפני שאתם מנסים לגרד את האתר של מישהו אחר הקפידו לוודא איתו שהוא מתיר לכם לגרד את הדפים שלו.
מהטעם שגירוד דפי רשת אינו בהכרח חוקי, נלמד לגרד דף שהקמתי על השרת במחשב האישי.
הדף כולל מספר ביקורות נבחרות שקיבל אתר רשתטק, ועליו נעשה את ניתוח הסנטימנט.
מוזמנים להוריד את קוד ה- HTML של הדף, כמו גם את הקוד שנפתח מכאן. השתמשו בדף ה- HTML כדי לתרגל את נושא הגירוד הלכה למעשה.
את דף ה-HTML אתם יכולים להעלות לשרת שלכם, במידת האפשר. אפשרות אחרת היא ליצור שרת פרטי על המחשב האישי. אינכם יודעים כיצד להקים שרת? קראו את המדריך התקנת PHP על המחשב האישי.
את הדפים נגרד באמצעות ספריית BeautifulSoup עליה הסברתי בפירוט במדריךגירוד דפי רשת (Web scraping) באמצעות פייתון ולכן אתאר את התהליך פה מאוד בקיצור.
נייבא את הספריות הדרושות לנו לצורך גירוד ואיסוף הנתונים:
import numpy as np
import pandas as pd- Numpy מבצעת חישובים מתמטיים בפרט על מערכים רב מימדיים.
- Pandas - במטרה להפוך את הנתונים לdataframes נוח לעבודה.
נייבא בנוסף:
import urllib.request
from bs4 import BeautifulSoup
# utf8 support
import codecs
# regular expressions
import re- urllib.request – מאפשר לעבוד עם כל מה שניתן להגיע אליו באמצעות כתובות אינטרנט (דפי אינטרנט ו-json).
- BeautifulSoup – גירוד הדפים בפועל ל-soup שניתן למצות ממנו מידע.
- codecs לעבודה עם שפות UTF-8 דוגמת עברית
- המודול re מאפשר לעבוד עם ביטויים רגולריים בפייתון
נגדיר את ה-url שאותו אנחנו מעוניינים לגרד, וניגש לכתובת האינטרנט באמצעות urllib:
url = 'https://localhost/sentiment_analysis_src.html'
source = urllib.request.urlopen(url)את המידע המוחזר נעביר ל- BeautifulSoup המצויידת בפונקציות שמאפשרות לנו לשלוף מתוך המידע הרלוונטי מתוך המרק soup:
soup = BeautifulSoup(source,'html.parser')התוכן שמעניין אותנו נמצא בתוך divs השייכים לקלאס cibtebt:
reviews = soup.find_all('div',{'class': 'cibtebt'})בשלב זה, יש לנו רשימה של מידע שנמצא בתוך כל אחד מה-divs הרלוונטיים. מכיוון שזו רשימה אנחנו יכולים לרוץ על כל אחד מהפריטים באמצעות לולאה.
בתוך כל div אנחנו מעוניינים בטקסט של התגובה שנמצא בתוך פסקה מסוג review. נאסוף את הטקסטים לתוך רשימה ששמה he_reviews על ידי כך שנריץ לולאה על רשימת ה-reviews:
he_reviews = []
ratings = []
for review in reviews:
# extract the text
content = review.find('p',{'class':'review'}).get_text()
content = re.sub(r'[s,]+', ' ', content)
# extract the ratings
rating = review.find('p',{'class':'rating'}).get_text()
rating = re.sub('[^0-9.]', '', rating)
rating = float(rating)/5*100
rating = "%.2f" % rating
rating = str(rating)+'%'
he_reviews.append(content)
ratings.append(rating)- הלולאה אספה את הטקסט של כל אחת מהתגובות לתוך הרשימה he_reviews וגם את הדירוג בפועל שנתן כל אחד מהמגיבים ברשימה ratings.
נקים DataFrame. -בתוכו נשים את רשימת ה he_reviews וה-ratings:
df = pd.DataFrame({'review': [], 'en_trans': [], 'rating': [], 'score': []})df.review = he_reviews
df.rating = ratingsמה ב-DataFrame:
df
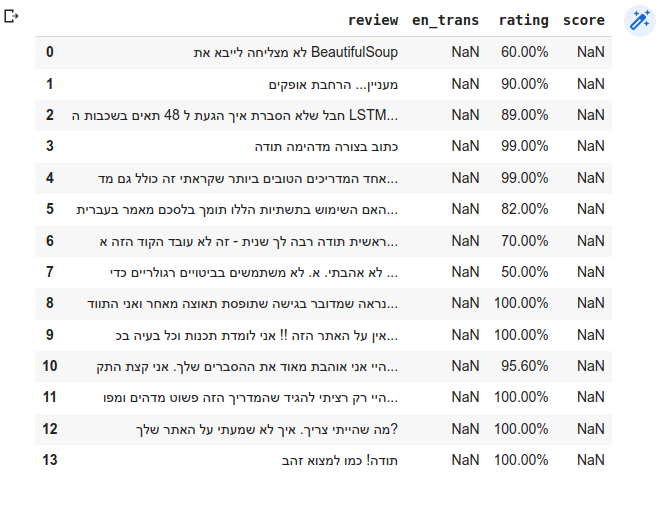
- נוסף לטקסט התגובות בעברית ולדירוג שנתנו המשתמשים, ה-df מכיל שתי עמודות נוספות שמיד נמלא: עמודה של תרגום התוכן לאנגלית en_trans כי לא מצאתי דרך לערוך ניתוח סנטימנט בעברית ועמודת score שתכיל את התוצאות של ניתוח הסנטימנט, אחרי שנעשה אותו.
תרגום לאנגלית
כיוון שלא מצאתי לדרך לערוך ניתוח סנטימנט בעברית נצטרך לתרגם את הטקסטים של התגובות לאנגלית קודם שנוכל להזין אותם למודל. את התרגום יעשה בשבילנו Google Translate באמצעות ספריית פייתון googletrans:
!pip install googletrans==4.0.0-rc1- גרסת הספרייה חשובה כי לא כל הגרסאות עובדות.
נייבא ונאתחל את ספריית התרגום:
from googletrans import Translator
translator = Translator()נשתמש בפונקצית למדא בשביל התרגום:
def targem(txt) :
en_trans = translator.translate(txt)
return en_trans.text
df['en_trans'] = df['review'].apply(lambda x: targem(x))נסקור כמה שורות של התוצאות:
df.iloc[:3]

ניתוח סנטימנט sentiment analysis
הכנת סביבת העבודה
עבודה על ניתוח הסנטימנט דורשת הורדה והתקנה של חבילות תוכנה:
!pip install transformers[sentencepiece]- סימן הקריאה הוא בגלל שאני מתקין את הספרייה ישירות מתוך המחברת. אפשר להשיג את אותה התוצאה כשעובדים עם
הטרמינל.
# machine learning framework
import torch- ספריית transformers מבית Hugging Face מאפשרת לעבוד עם הטרנספורמרים השונים בממשק אחיד. אפשר לעבוד עם ספריית TensorFlow במדריך זה נעבוד עם ספריית PyTorch.
אין צורך ב-GPU:
# device config
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)cpu
עבודה עם טרנספורמרים של hugging face
# auto classes - automatically retrieve the relevant model given the name/path
import sentencepiece
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment
tokenizer = AutoTokenizer.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')
model = AutoModelForSequenceClassification.from_pretrained('nlptown/bert-base-multilingual-uncased-sentiment')- הקלאסים החכמים של HuggingFace יודעים לגייס את המודל וה-tokenizer על פי מזהה המודל.
נדגים ניתוח סנטימנט באמצעות המודל על משפט אחד:
txt = 'It could have been awesome, uplifting and the best of its kind but it ended up being just meh'נעשה לו טוקניזציה - תהליך שמחלק את הטקסט למרכיבים, בדרך כלל מילים:
tokens = tokenizer.encode(txt, return_tensors='pt')- הטנסורים המוחזרים צריכים להיות מסוג PyTorch (pt)
נעביר את פלט הטוקנים למודל כדי בשביל ניתוח הסנטימנט:
result = model(tokens)
התוצאה היא טנסור המורכב מ-5 פריטים כי הדירוג הוא מ-1 עד-5:
result.logitstensor([[-0.9047, 1.4000, 2.3043, 0.0151, -2.3842]], grad_fn=AddmmBackward0)
התוצאה מכילה רשימה של logits לוג הסתברויות לא מנורמלות unnormalized log probabilities כאשר הערך הגבוה ביותר הוא הניבוי של המודל. במקרה זה, הערך הגבוה ביותר הוא 2.3043 בפריט השלישי מתוך 5. נמצא את הפריט הגבוה ביותר באמצעות הפונקציה argmax(), נוסיף 1 ונחלק ב-5 כדי לקבל את הערך באחוזים במקום בדירוג אורדינלי:
m = torch.argmax(result.logits)+1
r = m/5*100
str(int(r.item()))+'%'60%
- תוצאה של 60% למשפט שאומר ש-"זה יכול היה להיות מדהים אבל בסוף יצא לא "משהו. מראה שהמחשב הצליח להבין את הסנטימנט על אף המשפט המפותל.
נארוז לתוך פונקציה את הקוד למציאת הסנטימנט באחוזים מה-logits:
def get_score_from_logits(logits):
m = torch.argmax(logits)+1
r = m/5*100
return str(int(r.item()))+'%'נריץ את המודל על התרגומים לאנגלית ונאסוף את הדירוג באחוזים לתוך ה-df:
def get_score_for_phrase(phrase):
tokens = tokenizer.encode(phrase, return_tensors='pt')
result = model(tokens)
return get_score_from_logits(result.logits)
df['score'] = df['en_trans'].apply(lambda x: get_score_for_phrase(x[:512]))- המודל יכול לקבל לכל היותר 512 טוקנים.
התוצאה מוצגת ב-DataFrame:
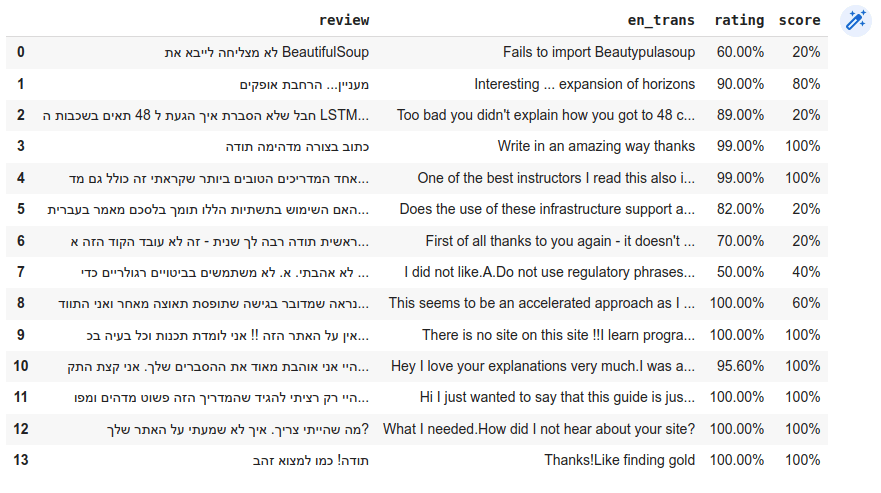
הערכת התוצאות
מתוך המדגם הלא אקראי של תגובות ל מדריכי רשתטק 9/13 תוצאות מראות התאמה בין דירוג הגולשים ובין ניבויי המודל. ננסה להבין מה גרם להבדלים בתוצאות.
def print_result(idx):
print('review: ', df.iloc[idx]['review'])
print('en_trans: ', df.iloc[idx]['en_trans'])
print('rating: ', df.iloc[idx]['rating'])
print('score: ', df.iloc[idx]['score'])print_result(2)review: חבל שלא הסברת איך הגעת ל 48 תאים בשכבות ה LSTM שלך en_trans: Too bad you didn't explain how you got to 48 cells in your LSTM layers rating: 89.00% score: 20%
- למרות שהמשתמש נתן דירוג גבוה 89, ניתוח הסנטימנט נתן ציון נמוך ביותר (20). יכול להיות שהניתוח חשף משהו מהמחשבות האמיתיות של המשתמש אבל יותר סביר שהמשתמש התייחס בדירוג לכל המדריך ובתגובה לבעיה עקרונית שהוא מצא למרות ההערכה הגבוהה באופן כללי.
האם הבינה המלאכותית תצליח להבין את כוונת המשפטים הבאים?
sentences = [
'עוזר ממש!!! חבל על הזמן' ,
'עוזר ממש חבל על הזמן',
'סוף הדרך! מומלץ בטירוף',
'סוף הדרך מומלץ בטירוף',
]
for sentence in sentences:
print('review: ', sentence)
trans = targem(sentence)
print('en_trans: ', trans)
print('score: ', get_score_for_phrase(trans))התוצאות:
review: עוזר ממש!!! חבל על הזמן en_trans: Aid really !!!Really cool score: 100% review: עוזר ממש חבל על הזמן en_trans: Helps really rope on time score: 100% review: סוף הדרך! מומלץ בטירוף en_trans: End of the Road!Insanely recommended score: 100% review: סוף הדרך מומלץ בטירוף en_trans: The end of the road is insanely recommended score: 40%
- המערכת הצליחה לתפוס את משמעות הביטוי "חבל על הזמן" למרות השימוש בלשון סגי נהור.
- קיים הבדל דרמטי בציון שנתנה המערכת לצמד הביטויים:
"סוף הדרך! מומלץ בטירוף"
"סוף הדרך מומלץ בטירוף"
כאשר התגובה שכללה סימן קריאה קיבלה ציון סנטימנט מושלם והתגובה ללא הסימן רק 40. הבדל זה מעניין ונובע מהתרגום השגוי במקרה של המשפט השני.
לסיכום
מערכות בינה מלאכותית הגיעו לשלב שבו הם יכולות להבין את כוונת האדם על סמך טקסט שכתב באמצעות ניתוח סנטימנט מה שיכול לעזור למפרסמים ומשווקים שרוצים לדעת מה רוצה ההמון כדי לעשות מזה הון. עם זאת, קיימים עדיין קשיים בדרך הנובעים, לדוגמה, מכך שהמודלים לא עובדים בעברית. בנוסף, הבעה בכתב מציבה קושי בפני משתמשים ועל כן קל להם יותר לדרג הרגשה כוללת (גשטלט) בדרך של דירוג אורדינלי עם ממשק גרפי שווה לכל נפש. לדוגמה, באמצעות כוכבים:

אולי גם זה יעניין אותך
ניתוח סנטימנט של טקסט (כמעט) בעברית
פיתוח מודל לאנליזת סנטימנט באמצעות למידת מכונה ו-TensorFlow
הטרנספורמרים משנים את עולם הבינה המלאכותית
מבוא ללמידת מכונה באמצעות ספריית PyTorch
לכל המדריכים בנושא של למידת מכונה
אהבתם? לא אהבתם? דרגו!
0 הצבעות, ממוצע 0 מתוך 5 כוכבים

המדריכים באתר עוסקים בנושאי תכנות ופיתוח אישי. הקוד שמוצג משמש להדגמה ולצרכי לימוד. התוכן והקוד המוצגים באתר נבדקו בקפידה ונמצאו תקינים. אבל ייתכן ששימוש במערכות שונות, דוגמת דפדפן או מערכת הפעלה שונה ולאור השינויים הטכנולוגיים התכופים בעולם שבו אנו חיים יגרום לתוצאות שונות מהמצופה. בכל מקרה, אין בעל האתר נושא באחריות לכל שיבוש או שימוש לא אחראי בתכנים הלימודיים באתר.
למרות האמור לעיל, ומתוך רצון טוב, אם נתקלת בקשיים ביישום הקוד באתר מפאת מה שנראה לך כשגיאה או כחוסר עקביות נא להשאיר תגובה עם פירוט הבעיה באזור התגובות בתחתית המדריכים. זה יכול לעזור למשתמשים אחרים שנתקלו באותה בעיה ואם אני רואה שהבעיה עקרונית אני עשוי לערוך התאמה במדריך או להסיר אותו כדי להימנע מהטעיית הציבור.
שימו לב! הסקריפטים במדריכים מיועדים למטרות לימוד בלבד. כשאתם עובדים על הפרויקטים שלכם אתם צריכים להשתמש בספריות וסביבות פיתוח מוכחות, מהירות ובטוחות.
המשתמש באתר צריך להיות מודע לכך שאם וכאשר הוא מפתח קוד בשביל פרויקט הוא חייב לשים לב ולהשתמש בסביבת הפיתוח המתאימה ביותר, הבטוחה ביותר, היעילה ביותר וכמובן שהוא צריך לבדוק את הקוד בהיבטים של יעילות ואבטחה. מי אמר שלהיות מפתח זו עבודה קלה ?
השימוש שלך באתר מהווה ראייה להסכמתך עם הכללים והתקנות שנוסחו בהסכם תנאי השימוש.